深夜,我用python爬取了整个斗图网站,不服来斗
QQ、微信斗图总是斗不过,索性直接来爬斗图网,我有整个网站的图,不服来斗。
废话不多说,选取的网站为斗图啦,我们先简单来看一下网站的结构
网页信息

从上面这张图我们可以看出,一页有多套图,这个时候我们就要想怎么把每一套图分开存放(后边具体解释)
通过分析,所有信息在页面中都可以拿到,我们就不考虑异步加载,那么要考虑的就是分页问题了,通过点击不同的页面,很容易看清楚分页规则

很容易明白分页URL的构造,图片链接都在源码中,就不做具体说明了明白了这个之后就可以去写代码抓图片了
存图片的思路
因为要把每一套图存入一个文件夹中(os模块),文件夹的命名我就以每一套图的URL的最后的几位数字命名,然后文件从文件路径分隔出最后一个字段命名,具体看下边的截图。

这些搞明白之后,接下来就是代码了(可以参考我的解析思路,只获取了30页作为测试)全部源码
# -*- coding:utf-8 -*-
import requests
from bs4 import BeautifulSoup
import os
class doutuSpider(object):
headers = {
"user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36"}
def get_url(self,url):
data = requests.get(url, headers=self.headers)
soup = BeautifulSoup(data.content,'lxml')
totals = soup.findAll("a", {"class": "list-group-item"})
for one in totals:
sub_url = one.get('href')
global path
path = 'J:\\train\\image'+'\\'+sub_url.split('/')[-1]
os.mkdir(path)
try:
self.get_img_url(sub_url)
except:
pass
def get_img_url(self,url):
data = requests.get(url,headers = self.headers)
soup = BeautifulSoup(data.content, 'lxml')
totals = soup.find_all('div',{'class':'artile_des'})
for one in totals:
img = one.find('img')
try:
sub_url = img.get('src')
except:
pass
finally:
urls = 'http:' + sub_url
try:
self.get_img(urls)
except:
pass
def get_img(self,url):
filename = url.split('/')[-1]
global path
img_path = path+'\\'+filename
img = requests.get(url,headers=self.headers)
try:
with open(img_path,'wb') as f:
f.write(img.content)
except:
pass
def create(self):
for count in range(1, 31):
url = 'https://www.doutula.com/article/list/?page={}'.format(count)
print '开始下载第{}页'.format(count)
self.get_url(url)
if __name__ == '__main__':
doutu = doutuSpider()
doutu.create()
结果

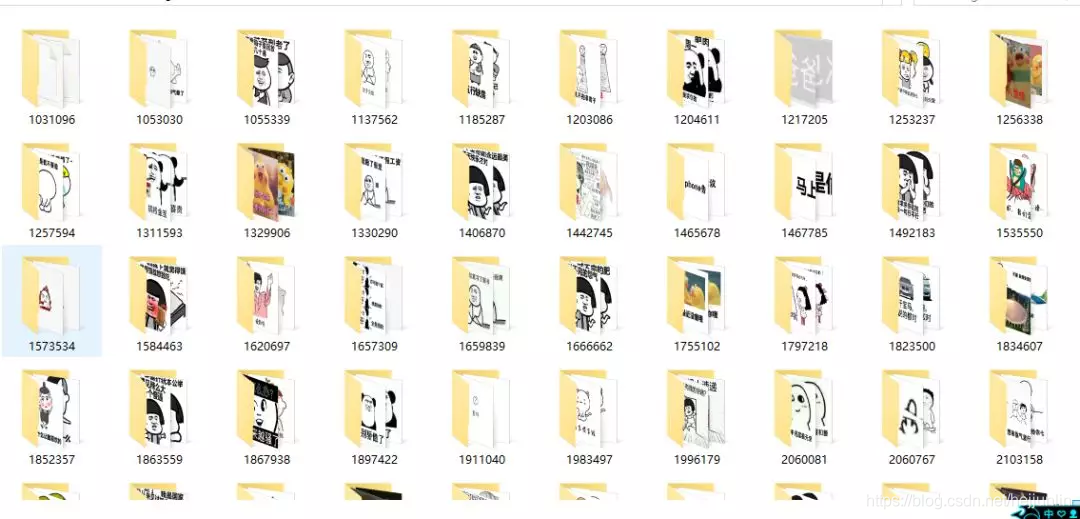
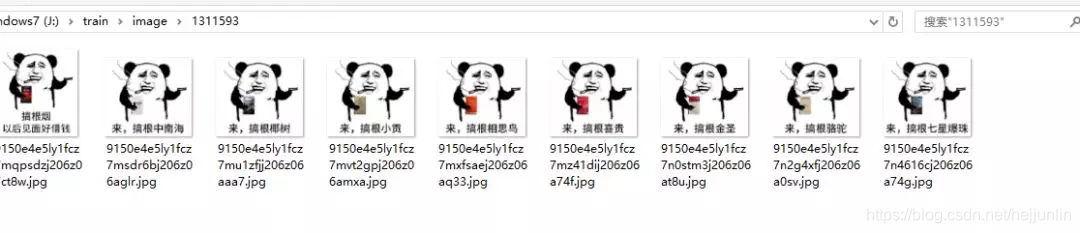
总结
总的来说,这个网站结构相对来说不是很复杂,大家可以参考一下,爬一些有趣的
原创作者:loading_miracle,原文链接:
https://www.jianshu.com/p/88098728aafd

欢迎关注我的微信公众号「码农突围」,分享Python、Java、大数据、机器学习、人工智能等技术,关注码农技术提升•职场突围•思维跃迁,20万+码农成长充电第一站,陪有梦想的你一起成长。
深夜,我用python爬取了整个斗图网站,不服来斗的更多相关文章
- Python 爬取各大代理IP网站(元类封装)
import requests from pyquery import PyQuery as pq base_headers = { 'User-Agent': 'Mozilla/5.0 (Windo ...
- Python 爬取所有51VOA网站的Learn a words文本及mp3音频
Python 爬取所有51VOA网站的Learn a words文本及mp3音频 #!/usr/bin/env python # -*- coding: utf-8 -*- #Python 爬取所有5 ...
- python爬取网站数据
开学前接了一个任务,内容是从网上爬取特定属性的数据.正好之前学了python,练练手. 编码问题 因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这个机会算是彻底搞清楚了. 问题要从文字的编码讲 ...
- python爬取某个网页的图片-如百度贴吧
python爬取某个网页的图片-如百度贴吧 作者:vpoet mail:vpoet_sir@163.com 注:随意copy,不用告诉我 #coding:utf-8 import urllib imp ...
- Python:爬取乌云厂商列表,使用BeautifulSoup解析
在SSS论坛看到有人写的Python爬取乌云厂商,想练一下手,就照着重新写了一遍 原帖:http://bbs.sssie.com/thread-965-1-1.html #coding:utf- im ...
- 使用python爬取MedSci上的期刊信息
使用python爬取medsci上的期刊信息,通过设定条件,然后获取相应的期刊的的影响因子排名,期刊名称,英文全称和影响因子.主要过程如下: 首先,通过分析网站http://www.medsci.cn ...
- python爬取免费优质IP归属地查询接口
python爬取免费优质IP归属地查询接口 具体不表,我今天要做的工作就是: 需要将数据库中大量ip查询出起归属地 刚开始感觉好简单啊,毕竟只需要从百度找个免费接口然后来个python脚本跑一晚上就o ...
- Python爬取豆瓣指定书籍的短评
Python爬取豆瓣指定书籍的短评 #!/usr/bin/python # coding=utf-8 import re import sys import time import random im ...
- python爬取网页的通用代码框架
python爬取网页的通用代码框架: def getHTMLText(url):#参数code缺省值为‘utf-8’(编码方式) try: r=requests.get(url,timeout=30) ...
随机推荐
- vm文件的优点
vm文件的优点 相较于内容写在jsp 文件: 1.在网页上上浏览和下载的内容用的是同一套,也就是说只需要维护一套内容,页面上看到的和下载得到的是一致的. 2.版本控制较为简便, 实现了页面内容和jsp ...
- c#数据库解析
引言工作需要将数十万条文本数据解析存入Mysql数据库中,代码使用C#实现,存储效率还可以,以下是一些主要代码的说明. txtdataToMysql 项目描述:解析文本文件,该文件使用爬虫爬下的数十万 ...
- python ATM项目
1.需求: 指定最大透支额度 可取款 定期还款(每月指定日期还款,如15号) 可存款 定期出账单 支持多用户登陆,用户间转帐 支持多用户 管理员可添加账户.指定用户额度.冻结用户等 购物车: 商品信息 ...
- 几种 npm install XXX 的区别
在使用npm命令安装资源包时,有哪些需要注意的区别 npm install X 会把X包安装到node_modules目录中 不会修改package.json 之后运行npm install命令时,不 ...
- Vue数据绑定(一)
Contents Vue作为当下炙手可热的前端三大框架之一,一直都想深入研究一下其内部的实现原理,去学习MVVM模式的精髓.如果说MVVM是当下最流行的图形用户界面开发模式,那么数据绑定则是这一模式的 ...
- tp5.1 请求时间格式化
当前时间:{$Request.time|date='Y-m-d H:i:s'} 注意database.php的配置!记录一下!
- Spring Security基于Oauth2的SSO单点登录怎样做?一个注解搞定
一.说明 单点登录顾名思义就是在多个应用系统中,只需要登录一次,就可以访问其他相互信任的应用系统,免除多次登录的烦恼.本文主要介绍 同域 和 跨域 两种不同场景单点登录的实现原理,并使用 Spring ...
- bootstrap简介与入门
bootstrap前端框架 1.概念:一个前端开发的框架,Bootstrap,来自 Twitter,是目前很受欢迎的前端框架.Bootstrap 是基于 HTML.CSS.JavaScript 的,它 ...
- jvm GC算法和种类
1.GC 垃圾收集 Garbage Collection 通常被称为“GC”,它诞生于1960年 MIT 的 Lisp 语言,经过半个多世纪,目前已经十分成熟了. jvm 中,程序计数器.虚拟 ...
- 【DirectX 11学习笔记】世界矩阵的理解-运动合成
最近在看龙书,写一下自己的学习理解,主要是物体运动的合成. 物体于局部坐标系内构建,每个物体拥有自己的局部坐标系以及相应的顶点矩阵A,并通过世界矩阵变换到唯一的世界坐标系. 物体在某时刻发生了位移和旋 ...