python爬虫(七) mozillacookiejar
MozillaCookiejar
保存百度得Cookiejar信息:
from urllib import request
from urllib import parse
from http.cookiejar import MozillaCookieJar # 保存在本地
cookiejar=MozillaCookieJar('cookie.txt')
handler=request.HTTPCookieProcessor(cookiejar)
opener=request.build_opener(handler) # 打开百度,此时已将信息保存在了cookiejar中
resp=opener.open('http://www.baidu.com/') # 下载在本地
cookiejar.save()

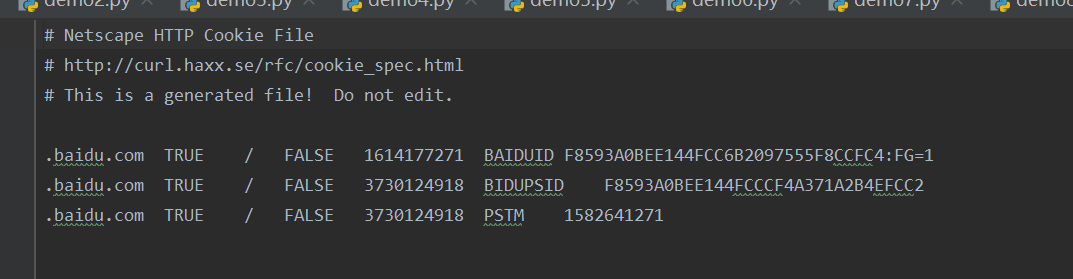
如果通过网址:hyypbin.org中得一个连接来自定义cookie信息,然后再代码中引用这个新的网址,那么下载在本地得cookie.txt为空,因为在cookie信息会在我们结束浏览时过期,如果想浏览刚刚使用得cookie信息,我们可以在代码得save函数中写
cookiejar.save(ignore_discard=True)
如果想把我们过期得cookie得信息打印出来,使用load函数
cookiejar.load(ignore_discard=True)
然后再加上
for cookie in cookiejar:
print(cookie)
python爬虫(七) mozillacookiejar的更多相关文章
- Python 爬虫七 Scrapy
Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓取 )所设 ...
- python爬虫(七)_urllib2:urlerror和httperror
urllib2的异常错误处理 在我们用urlopen或opener.open方法发出一个请求时,如果urlopen或opener.open不能处理这个response,就产生错误. 这里主要说的是UR ...
- Python爬虫实战七之计算大学本学期绩点
大家好,本次为大家带来的项目是计算大学本学期绩点.首先说明的是,博主来自山东大学,有属于个人的学生成绩管理系统,需要学号密码才可以登录,不过可能广大读者没有这个学号密码,不能实际进行操作,所以最主要的 ...
- Python爬虫入门七之正则表达式
在前面我们已经搞定了怎样获取页面的内容,不过还差一步,这么多杂乱的代码夹杂文字我们怎样把它提取出来整理呢?下面就开始介绍一个十分强大的工具,正则表达式! 1.了解正则表达式 正则表达式是对字符串操作的 ...
- 孤荷凌寒自学python第七十九天开始写Python的第一个爬虫9并使用pydocx模块将结果写入word文档
孤荷凌寒自学python第七十九天开始写Python的第一个爬虫9 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 到今天终于完成了对docx模块针对 ...
- 孤荷凌寒自学python第七十八天开始写Python的第一个爬虫8
孤荷凌寒自学python第七十八天开始写Python的第一个爬虫8 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 到今天止基本完成了对docx模块针 ...
- 孤荷凌寒自学python第七十七天开始写Python的第一个爬虫7
孤荷凌寒自学python第七十七天开始写Python的第一个爬虫7 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 今天的学习仍然是在纯粹对docx模 ...
- 孤荷凌寒自学python第七十六天开始写Python的第一个爬虫6
孤荷凌寒自学python第七十六天开始写Python的第一个爬虫6 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 不过由于对python-docx模 ...
- 孤荷凌寒自学python第七十五天开始写Python的第一个爬虫5
孤荷凌寒自学python第七十五天开始写Python的第一个爬虫5 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 直接上代码.详细过程见文末屏幕录像 ...
- 孤荷凌寒自学python第七十四天开始写Python的第一个爬虫4
孤荷凌寒自学python第七十四天开始写Python的第一个爬虫4 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 直接上代码.详细过程见文末屏幕录像 ...
随机推荐
- HGsoft-downloader
[NEW]HGsoft-downloader上线了! 给你提供一个简洁无广告的电脑软件下载平台,换个角度下载电脑软件. 网站地址:Go
- jmeter实现服务器端后台接口性能测试
实现目的 在进行服务器端后台接口性能测试时,需要连接到Linux服务器端,然后通过命令调用socket接口,这个过程就需要用到jmeter的SSH Command取样器实现了. 脚本实现 设置CSV ...
- php 接口获取公网ip并获取天气接口信息
<?php function get_ip(){ //判断服务器是否允许$_SERVER if(isset($_SERVER)){ if(isset($_SERVER['HTTP_X_FORWA ...
- mysql客户端的导出数据库表和数据库数据等相关操作
1.navicat for mysql 11.0.10客户端 导出数据库里所有表中的所有数据,方法如下,选中表,在横向导航栏里面找到“导出向导”,选中sql,点击下一步,点击全选,并且选中“应用相同目 ...
- Blockchain technology and Application
BTC-密码学原理 比特币本质:crypto currency[加密货币] 比特币用到的两个功能: 1.哈希 crypto graphic hash function 2.签名(非对称加密) 哈希cr ...
- win10安装 .net3.5失败解决方法
#开始 最近需要学习Sql Server 但是发现SQL Server2008r2 版本的安装程序基于.net 电脑没有安装.net3.5 #解决过程 可笑的是我在用离线安装包安装.net3.5的时候 ...
- 洛谷P1616疯狂的采药(完全背包)
题目背景 此题为NOIP2005普及组第三题的疯狂版. 此题为纪念LiYuxiang而生. 题目描述 LiYuxiang是个天资聪颖的孩子,他的梦想是成为世界上最伟大的医师.为此,他想拜附近最有威望的 ...
- ListView 基础列表组件、水平 列表组件、图标组件
一.Flutter 列表组件概述 列表布局是我们项目开发中最常用的一种布局方式.Flutter 中我们可以通过 ListView 来定义 列表项,支持垂直和水平方向展示.通过一个属性就可以控制列表的显 ...
- FYF的煎饼果子
利用等差数列公式就行了,可以考虑特判一下m >= n($ m, n \neq 1 $),这时一定输出“AIYAMAYA”. #include <iostream> using nam ...
- P1432
这个题是一个很简单的等比数列. 题目大意是:初始第一步 $ n_1 = 2 $,之后的每一步都比前一步减少 98%,即满足等比数列 $ 2 + 2 \times 0.98 + 2 \times 0.9 ...