python爬虫(七) mozillacookiejar
MozillaCookiejar
保存百度得Cookiejar信息:
from urllib import request
from urllib import parse
from http.cookiejar import MozillaCookieJar # 保存在本地
cookiejar=MozillaCookieJar('cookie.txt')
handler=request.HTTPCookieProcessor(cookiejar)
opener=request.build_opener(handler) # 打开百度,此时已将信息保存在了cookiejar中
resp=opener.open('http://www.baidu.com/') # 下载在本地
cookiejar.save()

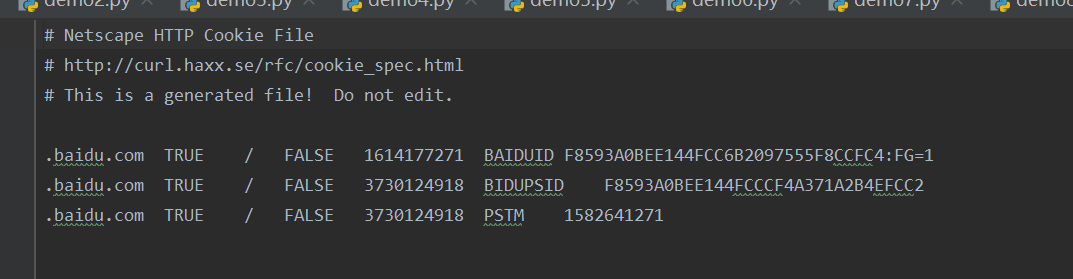
如果通过网址:hyypbin.org中得一个连接来自定义cookie信息,然后再代码中引用这个新的网址,那么下载在本地得cookie.txt为空,因为在cookie信息会在我们结束浏览时过期,如果想浏览刚刚使用得cookie信息,我们可以在代码得save函数中写
cookiejar.save(ignore_discard=True)
如果想把我们过期得cookie得信息打印出来,使用load函数
cookiejar.load(ignore_discard=True)
然后再加上
for cookie in cookiejar:
print(cookie)
python爬虫(七) mozillacookiejar的更多相关文章
- Python 爬虫七 Scrapy
Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓取 )所设 ...
- python爬虫(七)_urllib2:urlerror和httperror
urllib2的异常错误处理 在我们用urlopen或opener.open方法发出一个请求时,如果urlopen或opener.open不能处理这个response,就产生错误. 这里主要说的是UR ...
- Python爬虫实战七之计算大学本学期绩点
大家好,本次为大家带来的项目是计算大学本学期绩点.首先说明的是,博主来自山东大学,有属于个人的学生成绩管理系统,需要学号密码才可以登录,不过可能广大读者没有这个学号密码,不能实际进行操作,所以最主要的 ...
- Python爬虫入门七之正则表达式
在前面我们已经搞定了怎样获取页面的内容,不过还差一步,这么多杂乱的代码夹杂文字我们怎样把它提取出来整理呢?下面就开始介绍一个十分强大的工具,正则表达式! 1.了解正则表达式 正则表达式是对字符串操作的 ...
- 孤荷凌寒自学python第七十九天开始写Python的第一个爬虫9并使用pydocx模块将结果写入word文档
孤荷凌寒自学python第七十九天开始写Python的第一个爬虫9 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 到今天终于完成了对docx模块针对 ...
- 孤荷凌寒自学python第七十八天开始写Python的第一个爬虫8
孤荷凌寒自学python第七十八天开始写Python的第一个爬虫8 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 到今天止基本完成了对docx模块针 ...
- 孤荷凌寒自学python第七十七天开始写Python的第一个爬虫7
孤荷凌寒自学python第七十七天开始写Python的第一个爬虫7 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 今天的学习仍然是在纯粹对docx模 ...
- 孤荷凌寒自学python第七十六天开始写Python的第一个爬虫6
孤荷凌寒自学python第七十六天开始写Python的第一个爬虫6 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 不过由于对python-docx模 ...
- 孤荷凌寒自学python第七十五天开始写Python的第一个爬虫5
孤荷凌寒自学python第七十五天开始写Python的第一个爬虫5 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 直接上代码.详细过程见文末屏幕录像 ...
- 孤荷凌寒自学python第七十四天开始写Python的第一个爬虫4
孤荷凌寒自学python第七十四天开始写Python的第一个爬虫4 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 直接上代码.详细过程见文末屏幕录像 ...
随机推荐
- 发现一个比较好玩的,git的仓库可以转换
我们通过 git clone 下载一个仓库到本地, 1.这个本地的文件夹名字可以随便改. 2.如果你把本地仓库的全部文件,剪切到另一个文件夹内,这个新的文件夹就是git的本地仓库.
- 解密国内BAT等大厂前端技术体系-美团点评之上篇(长文建议收藏)
引言 进入2019年,大前端技术生态似乎进入到了一个相对稳定的环境,React在2013年发布至今已经6年时间了,Vue 1.0在2015年发布,至今也有4年时间了. 整个业界在前端框架不断迭代中,也 ...
- aria2连接网站出现handshake failure问题的分析与解决方法
aria2是一款轻量级的,支持多协议,跨平台的命令行下载工具,是笔者目前在使用的下载工具,结合uget使用基本上能媲美window下的迅雷工具.在笔者使用过程中,遇到了aria2连接部分网站时出现ha ...
- Python函数基础进阶
函数参数的另一种使用方式 def print_info(name,age): print("Name: %s" %name) print("age: %d" % ...
- CSS 绝对定位时,水平居中而不影响原文档中其它元素
div.absolutemiddle { position: absolute; left: 50%; transform: translate(-50%); /* 平移50%为自身尺寸的一半,实现水 ...
- django的静态文件配置和路由控制
上一篇写到刚建完django项目,此时我登录页面中调用了js文件,执行后发现报错了找不到js这个文件 目录结构如图所示: <!DOCTYPE html> <html lang=&qu ...
- python3中的raise使用
raise表示会抛出异常那么就是说raise会向python的解释器一个响应告诉解释器他的后面是一个异常让我们的程序中断 一般是和自定义的异常连用. class CustomError(Excepti ...
- 爬虫,工具 - Splash
What is it? Splash is a javascript rendering service. It's a lightweight web browser with an HTTP AP ...
- 前端必学---JavaScript数据结构与算法---简介
前端必学---JavaScript数据结构与算法---简介 1. 数据结构: 数据结构是相互之间存在一种或者多种特定关系的数据元素的集合.---<大话数据结构> 1.1 数据结构的分类 1 ...
- cmd添加管理员账号
net user 用户名 密码 /add net localgroup Administrators 用户名 /add