阿里巴巴开源canal 工具数据同步异常CanalParseException:parse row data failed,column size is not match for table......
一、异常现象截图
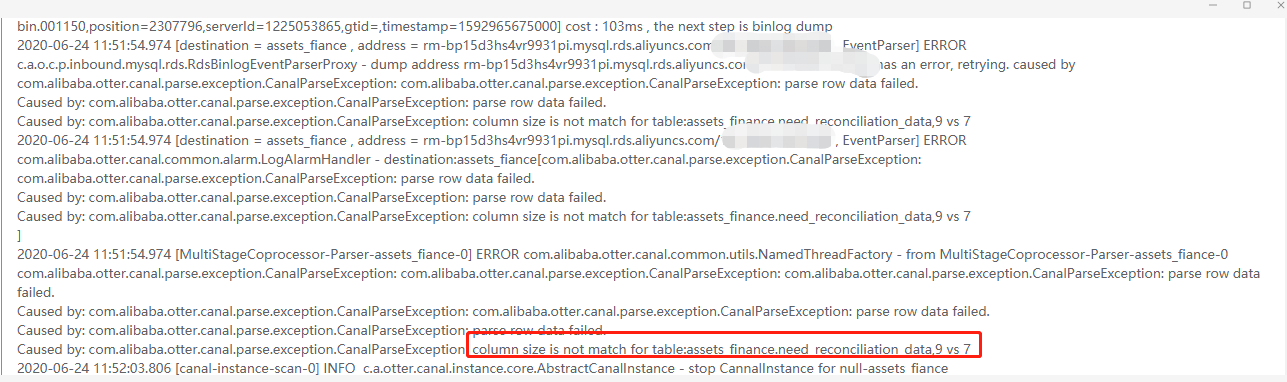
二、解决方式:
1、背景
早期的canal版本(<=1.0.24),在处理表结构的DDL变更时采用了一种简单的策略,在内存里维护了一个当前数据库内表结构的镜像(通过desc table获取)。
这样的内存表结构镜像的维护存在问题,如果当前在处理的binlog为历史时间段T0,当前时间为T1,存在的一些异常分支情况:
- 假如在T0~T1的时间内,表结构A发生过增加列的DDL操作,那在处理T0时间段A表的binlog时,拿到的表结构为T1的镜像,就会出现列不匹配的情况. 比如之前的异常: column size is not match for table: xx , 12 vs 13
- 假如在T0~T1发生了增加 C1列、删除了C2列,此时拿到的列的总数还是和T0时保持一致,但是对应的列会错位
- 假如在T0~T1发生了drop table的DDL,此时拿表结构时会出现无法找到表的异常,一直阻塞整个binlog处理,比如not found [xx] in db
补充一下MySQL binlog的一些技术背景:
本文作者:张永清,转载请注明出处:https://www.cnblogs.com/laoqing/p/13187324.html
- MySQL的在记录DML(INSERT/UPDATE/DELETE)的binlog时,会由一个当前表结构snapshot的TableMap binlog来描述,然后跟着一条DML的binlog
- TableMap对象里,会记录一些基本信息:列的数量、列类型精度、后续DML binlog里的数据存储格式等,但唯独没有记录列名信息、列编码、列类型,这也是大众业务理解binlog的基本诉求(但MySQL binlog只做同构重放,可以不关注这些),所以canal要做的一件事就是补全对应的列信息.
ps. 针对复杂的一条update中包含多张表的更新时,大家可以观察一下Table_map的特殊情况,留待有兴趣的同学发挥
2、方案
扯了一堆的背景之后,再来看一下我们如何解决canal上一版本存在的表结构一致性的问题,这里会把我们的思考过程都记录出来,方便大家辩证的看一下方案.
思考一
解决这个问题,第一个最直接的思考:canal在订阅binlog时,尽可能保持准实时,不做延迟回溯消费. 这样的方式会有对应的优点和缺点:
- canal要做准实时解析,业务上可能有failover的需求,假如在业务处理离线时,原本canal基于内存ringBuffer的模型,会出现延迟解析,如果要解决这个问题,必须在canal store上支持了持久化存储的能力,比如实现或者转存到kafka/rocketmq等.
- canal准实时解析,如果遇到canal本身的failover,比如zookeeper挂、网络异常,出现分钟级别以上的延迟,DDL变化的概率会比较高,此时就会陷入之前一样的表结构一致性的问题
整个方案上,基本是想避开表结构的问题,在遇到一些容灾场景下一定也会遇上,不是一个技术解决的方案,废弃.
思考二
经过了第一轮辩证的思考,基本确定想通过迂回的方式,简单绕过一致性的问题不是正解,所以这次的思考主要就是如何正面解决一致性的问题. 基本思路:基于binlog中DDL的变化,来动态维护一份表结构,比如DDL中增加一个列,在本地表结构中也动态增加一列,解析binlog时都从本地表结构中获取
实现方案:
- 本地表结构的维护,每个canal进程可以带着一个二进制的MySQL版本,把收到的每条DDL,在本地MySQL中进行重放,从而维护一个本地的MySQL表结构
- 每个canal第一次订阅或者回滚到指定位点,刚启动时需要拉取一份表结构基线,存入本地表结构MySQL库,然后在步骤1的方案上维护一个增量DDL.
整个方案上,可以绝大部分的解决DDL的问题,但也存在一些缺点:
- 每个canal进程,维护一个隔离的MySQL实例。不论是资源成本、运维成本上都有一些瑕疵,更像是一个工程的解决方案,不是一个开源+技术产品的解决方案
- 位点如果存在相对高频的位点回溯,每次都需要重新做表结构基线,做表结构基线也会概率遇上表结构一致性问题
思考三
有了之前的两次思考,思路基本明确了,在一次偶然的机会中和alibaba Druid的作者高铁,交流中得到了一些灵感,是否可以基于Druid对DDL的支持能力,来构建一份动态的表结构.
大致思路:
- 首先准备一份表结构基线数据,每条建表语句传入druid的SchemaRepository.console(),构建一份druid的初始表结构
- 之后在收到每条DDL变更时,把alter table add/drop column等,全部传递给druid,由druid识别ddl语句并在内存里执行具体的add/drop column的行为,维护一份最终的表结构
- 定时把druid的内存表结构,做一份checkpoint,之后的位点回溯,可以是checkpoint + 增量DDL重放的方式来快速构建任意时间点的表结构
最终方案示意图

- C0为初始化的checkpoint,拿到所有满足订阅条件的表结构
- D1为binlog日志流中的DDL,它会有时间戳T的标签,用于记录不同D1/D2之间的先后关系
- 定时产生一个checkpoint cm,并保存对应的checkpoint时间戳
- 用户如果回溯位点到任意时间点Tx,对应的表结构就是 checkpoint + ddl增量的结合
接口设计:
public interface TableMetaTSDB {
/**
* 初始化
*/
public boolean init(String destination);
/**
* 获取当前的表结构
*/
public TableMeta find(String schema, String table);
/**
* 添加ddl到时间表结构库中
*/
public boolean apply(BinlogPosition position, String schema, String ddl, String extra);
/**
* 回滚到指定位点的表结构
*/
public boolean rollback(BinlogPosition position);
/**
* 生成快照内容
*/
public Map<String/* schema */, String> snapshot();
}

- 依赖了alibaba druid的DDL SQL解析能力,维护一份MemoryTableMeta,实时内存表结构
- 依赖DAO持久化存储的能力,记录WAL结果(每条DDL) + checkpoint
持久化存储的思考:
- 本地嵌入式实现(H2):提供最小化的依赖,完成时序表结构管理的能力。基于磁盘的模式,可以结合存储计算分离的技术,canal failover之后只要在另一个计算节点上拉起,并加载云盘上的DB数据,做到多机冷备。
- 中心管控存储实现(MySQL): 一般结合于规模化的管控系统,允许将DDL数据录入到中心MySQL进行统一运维。
canal中如何使用
- 打开conf/canal.properties,选择持久化存储的方案,默认为H2
canal.instance.tsdb.spring.xml=classpath:spring/tsdb/h2-tsdb.xml
#canal.instance.tsdb.spring.xml=classpath:spring/tsdb/mysql-tsdb.xml
- 打开instance下的instance.properties,修改对应的参数
| 参数名 | 默认值 | 描述 |
|---|---|---|
| canal.instance.tsdb.enable | true | 是否开启时序表结构的能力 |
| canal.instance.tsdb.dir | ${canal.file.data.dir:../conf}/${canal.instance.destination:} | 默认存储到conf/$instance |
| canal.instance.tsdb.url | jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL; | jdbc链接串 |
| canal.instance.tsdb.dbUsername | canal | jdbc用户名,因为有自动创建表的能力,所以对该用户需要有create table的权限 |
| canal.instance.tsdb.dbPassword | canal | jdbc密码 |
例子:
# table meta tsdb info
canal.instance.tsdb.enable=true
canal.instance.tsdb.dir=${canal.file.data.dir:../conf}/${canal.instance.destination:}
canal.instance.tsdb.url=jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL;
#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb
canal.instance.tsdb.dbUsername=canal
canal.instance.tsdb.dbPassword=canal三、最后
目前canal 1.0.26最新版已经默认开启了时序表结构的能力,just have fun !
阿里巴巴开源canal 工具数据同步异常CanalParseException:parse row data failed,column size is not match for table......的更多相关文章
- 【Canal】数据同步的终极解决方案,阿里巴巴开源的Canal框架当之无愧!!
写在前面 在当今互联网行业,尤其是现在分布式.微服务开发环境下,为了提高搜索效率,以及搜索的精准度,会大量使用Redis.Memcached等NoSQL数据库,也会使用大量的Solr.Elastics ...
- 阿里巴巴开源故障注入工具_chaosblade
chaosblade是阿里巴巴最近开源的一款故障注入的工具,因为我最近在做公司的虚拟化平台的可靠性测试工具,无意中发现这个工具,个人感觉比较有用,用起来也比较简单,所以拿出来分享一下,期望对大家的工作 ...
- canal数据同步
前面提到数据库缓存不一致的几种解决方案,但是在不同的场景下各有利弊,而今天我们使用的canal进行缓存与数据同步的方案是最好的,但是也有一个缺点,就是相对前面几种解决方案会引入阿里巴巴的canal组件 ...
- Navicat premium对数据库的结构同步和数据同步功能
一.在目标数据库新建一个相同的数据库名. 二.工具-->结构同步. 三.填写源数据库和目标数据库. 四.点击比对 五.点击部署 六.点击运行 七.点击关闭.此时源数据库的结构已经同步到目标数据库 ...
- Spark记录-阿里巴巴开源工具DataX数据同步工具使用
1.官网下载 下载地址:https://github.com/alibaba/DataX DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL.Oracle.SqlSe ...
- Canal - 数据同步 - 阿里巴巴 MySQL binlog 增量订阅&消费组件
背景 早期,阿里巴巴 B2B 公司因为存在杭州和美国双机房部署,存在跨机房同步的业务需求 ,主要是基于trigger的方式获取增量变更.从 2010 年开始,公司开始逐步尝试数据库日志解析,获取增量变 ...
- 开源数据同步神器——canal
前言 如今大型的IT系统中,都会使用分布式的方式,同时会有非常多的中间件,如redis.消息队列.大数据存储等,但是实际核心的数据存储依然是存储在数据库,作为使用最广泛的数据库,如何将mysql的数据 ...
- 实战!Spring Boot 整合 阿里开源中间件 Canal 实现数据增量同步!
大家好,我是不才陈某~ 数据同步一直是一个令人头疼的问题.在业务量小,场景不多,数据量不大的情况下我们可能会选择在项目中直接写一些定时任务手动处理数据,例如从多个表将数据查出来,再汇总处理,再插入到相 ...
- 增量数据同步中间件DataLink分享(已开源)
项目介绍 名称: DataLink['deitə liŋk]译意: 数据链路,数据(自动)传输器语言: 纯java开发(JDK1.8+)定位: 满足各种异构数据源之间的实时增量同步,一个分布式.可扩展 ...
随机推荐
- Java和NodeJS解析XML对比
Java解析XML 1.接收xml文件或者字符串,转为InputStream 2.使用DocumentBuilderFactory对象将InputStream转为document对象 Document ...
- GNS3配置问题(持续更新)
GNS3配置问题 1.关于All in One的GNS3提示"判断dynamips版本失败"的解决办法 当我们找到GNS3根目录里的dynamips.exe,执行会报错告诉我们缺少 ...
- Redis 入门到分布式 (三) Redis客户端的使用
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 一.Java客服端:jedis 获取Jedis Jedis基本使用 Jedis连接池使用 1.Jedis ...
- Qcom rampdump解析工具使用
使用如下命令获取qcom工具: ljj@ljj-ThinkCentre-M83:~/git/qcom_tools/ramdump$ git clone git://codeaurora.org/qui ...
- (Java实现) 洛谷 P1028 数的计算
题目描述 我们要求找出具有下列性质数的个数(包含输入的自然数nn): 先输入一个自然数n(n≤1000),然后对此自然数按照如下方法进行处理: 不作任何处理; 在它的左边加上一个自然数,但该自然数不能 ...
- Java实现 LeetCode 561 数组拆分 I(通过排序算法改写PS:难搞)
561. 数组拆分 I 给定长度为 2n 的数组, 你的任务是将这些数分成 n 对, 例如 (a1, b1), (a2, b2), -, (an, bn) ,使得从1 到 n 的 min(ai, bi ...
- Java实现 蓝桥杯VIP 基础练习 FJ的字符串
问题描述 FJ在沙盘上写了这样一些字符串: A1 = "A" A2 = "ABA" A3 = "ABACABA" A4 = "AB ...
- Java实现 LeetCode 36 有效的数独
36. 有效的数独 判断一个 9x9 的数独是否有效.只需要根据以下规则,验证已经填入的数字是否有效即可. 数字 1-9 在每一行只能出现一次. 数字 1-9 在每一列只能出现一次. 数字 1-9 在 ...
- Java实现 蓝桥杯 基因牛的繁殖
基因牛的繁殖 张教授采用基因干预技术成功培养出一头母牛,三年后,这头母牛每年会生出1头母牛, 生出来的母牛三年后,又可以每年生出一头母牛.如此循环下去,请问张教授n年后有多少头母牛? 以下程序模拟了这 ...
- java实现三角螺旋阵
方阵的主对角线之上称为"上三角". 请你设计一个用于填充n阶方阵的上三角区域的程序.填充的规则是:使用1,2,3-.的自然数列,从左上角开始,按照顺时针方向螺旋填充. 例如:当n= ...