【MySQL】MySQL事务回滚脚本
MySQL自己的 mysqlbinlog | mysql 回滚不好用,自己写个简单脚本试试:
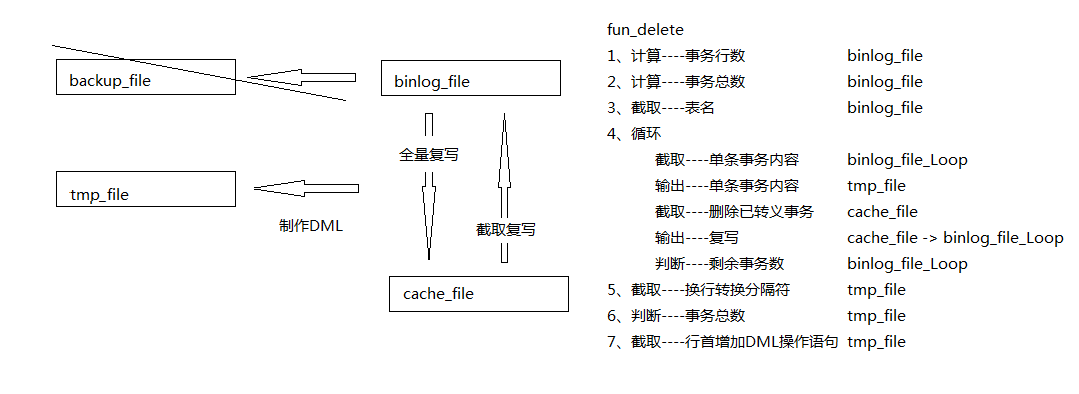
想法是用mysqlbinlog把需要回滚的事务区域从mysql-bin.file中找到,然后通过脚本再插入DB。
## INSERT 需要将新增数据删除 对应DELETE
## DELETE 需要将删除数据恢复 对应INSERT
## UPDATE 需要将修改数据恢复 对应UPDATE
## 手动读取BINLOG,并找到对应位置和对应事务
## 手动删除除事务外的其他说明语句
INSERT回滚最简单,其次是DELETE的,UPDATE操作比较麻烦。
#!/bin/bash
## INSERT 需要将新增数据删除 对应DELETE
## DELETE 需要将删除数据恢复 对应INSERT
## UPDATE 需要将修改数据恢复 对应UPDATE
## 手动读取BINLOG,并找到对应位置和对应事务
## 手动删除除事务外的其他说明语句 path=`pwd`
tmp_file=$path/tmp.file
cache_file=$path/cache.file
binlog_file=$path/$
sql_file=$path/rollback.sql
columns='$2' display_err()
{
echo -e "\033[45;36m$1\033[0m"
} display_ok()
{
echo -e "\033[40;32m$1\033[0m"
} fun_INSERT()
{
echo -e "\033[40;32m$1\033[0m"
} fun_DELETE()
{ ##### GET ONE TRANSACTION ROWS #####
local row_count=`awk 'BEGIN{print 12 + 2}'` ##### GET COUNtS OF TRANSACTION #####
n=`cat $binlog_file | grep DELETE | wc -l` ##### GET TABLE NAME #####
table=`sed -n '1p' $binlog_file | awk '{print $3}'` for ((i=;i<=n;i++))
do
##### MAKE SQL #####
sed -n '3,'$row_count'p' $binlog_file | awk '{print $1}'| awk -F '=' '{print $2}' | tr -t '\n' ',' | sed 's/,$//' | sed 's/^/(/' | sed 's/$/)/' >> $tmp_file ##### GET POS FOR CUT #####
local pos=`awk 'BEGIN{print '$row_count' + 1 }'` ##### CLEAN cache_file FOR TRANSACTION HAVE DONE #####
sed -n ''$pos',$w '$cache_file'' $binlog_file ##### COPY TO binlog_file #####
/bin/cp -f $cache_file $binlog_file ##### CHECK THE NUMBLE OF TRANSACTION ##### done
##### \n to , #####
sed 's/)(/),(/g' $tmp_file | sed 's/^/insert into t1 values /' | sed 's/)$/);/' > $sql_file
rm -rf $tmp_file
echo done! ##### CHECK THE NUMBLE OF TRANSACTION TO MAKE SQL ##### } case $ in
insert ) fun_INSERT
;;
delete ) fun_DELETE
;;
update ) fun_update
;;
* ) display_err "ERROR!!!! Only insert or delete or update could be input!"
;;
esac
【MySQL】MySQL事务回滚脚本的更多相关文章
- php+mysql 原生事务回滚
<?php $conn = mysql_connect('127.0.0.1', 'root', ''); mysql_select_db('msc_test'); mysql_query('S ...
- C# mysql 处理 事务 回滚 提交
MySqlConnection myCon; void iniMysql() { //连接数据库 myCon = new MySqlConnection("server=127.0.0.1; ...
- php+mysql实现事务回滚
模拟条件:第一个表插入成功,但是第二个表插入失败,回滚.第一个表插入成功,第二个表插入成功,执行.第一个表插入失败,第二个表插入成功,回滚.第一个表插入失败,第二个表插入失败,回滚.以上情况都需要回滚 ...
- mysql数据库 索引 事务和事务回滚
mysql索引 索引相当于书的目录优点:加快数据的查询速度缺点:占物理存储空间,添加,删除,会减慢写的速度 查看表使用的索引 mysql> show index from 表名\G;(\G分行显 ...
- 为什么mysql事务回滚后, 自增ID依然自增
事务回滚后,自增ID仍然增加,回滚后,自增ID仍然增加.比如当前ID是7,插入一条数据后,又回滚了.然后你再插入一条数据,此时插入成功,这时候你的ID不是8,而是9.因为虽然你之前插入回滚,但是ID还 ...
- MySQL 存储引擎、锁、调优、失误与事务回滚、与python交互、orm
1.存储引擎(处理表的处理器) 1.基本操作 1.查看所有存储引擎 mysql> show engines; 2.查看已有表的存储引擎 mysql> show create table 表 ...
- mysql事务回滚机制概述
应用场景: 银行取钱,从ATM机取钱,分为以下几个步骤 1 登陆ATM机,输入密码: 2 连接数据库,验证密码: 3 验证成功,获得用户信息,比如存款余额等: 4 用 ...
- 解析binlog生成MySQL回滚脚本
如果数据库误操作想恢复数据.可以试试下面这个脚本.前提是执行DML操作. #!/bin/env python #coding:utf-8 #Author: Hogan #Descript : 解析bi ...
- [转] C# mysql 事务回滚
什么是数据库事务 数据库事务是指作为单个逻辑工作单元执行的一系列操作. 设想网上购物的一次交易,其付款过程至少包括以下几步数据库操作: · 更新客户所购商品的库存信息 · 保存客户付款信息--可能包括 ...
随机推荐
- [JavaWebService-axis]-环境搭建
一.准备 1.下载环境需要的zip包 JDK Eclipse axis(http://axis.apache.org/axis2/java/core/download.html)(axis2-1.7. ...
- POJ2226 Muddy Fields 二分匹配 最小顶点覆盖 好题
在一个n*m的草地上,.代表草地,*代表水,现在要用宽度为1,长度不限的木板盖住水, 木板可以重叠,但是所有的草地都不能被木板覆盖. 问至少需要的木板数. 这类题的建图方法: 把矩阵作为一个二分图,以 ...
- xhprof 安装使用
1.安装扩展 windows下把 xhprof.dll 放到extensions目录下 修改配置文件 [xhprof] extension=xhprof.so; ; directory used by ...
- 设置Excel的自动筛选功能
单元格数字格式的问题 NPOI向Excel文件中插入数值时,可能会出现数字当作文本的情况(即左上角有个绿色三角),这样单元格的值就无法参与运算.这是因为在SetCellValue设置单元格值的时候使用 ...
- 区分listview的item和Button的点击事件
这两天修改领导通的ListView widget,在ListView中加入Button这类的有 “点击” 事件的widget,发现原来listview的itemclick居然失效了, 后来在网上查资料 ...
- ajax提交后完全不进入action直接返回错误
今天遇到个问题就是jQuery提交ajax请求,居然没有进入action的断点而直接返回错误信息. 仔细排查后才发现原来是因为客户端提交的某字段是100w的值,而后台对应的字段是个Short类型,根本 ...
- 要件审判九步法及其基本价值 z
要件审判九步法及其基本价值 发布时间:2014-12-24 14:29:05 作者介绍 邹碧华,男,1967年出生于江西奉新,毕业于北京大学法学院,获法学博士学位.上海市高级人民法院副院长.2006年 ...
- [Flex] IFrame系列 —— IFrame嵌入html后Alert弹出窗口被IFrame遮挡问题
<?xml version="1.0" encoding="utf-8"?> <!--- - - - - - - - - - - - - - ...
- SecureCRT的背景和文字颜色的修改
options->;session options->;emulation->;terminal选择linux(相应的服务器系统)ansi color 打上钩options-> ...
- C Primer Plus(第五版)6
第 6 章 C 控制语句 : 循环 在本章中你将学习下列内容 已经多次学过,没怎么标注 · 关键字: for while do while · 运算符: < > >= <= ! ...