Python数据分析之pandas入门
一、pandas库简介
二、pandas库的安装
三、Series的使用

import pandas as pd
ser=pd.Series([12,33,55,66])
print(ser) '''输出为
0 12
1 33
2 55
3 66
dtype: int64
'''
运行上面的代码,可以知道,如果不指定标签,那么默认标签就是从0开始递增,我们也可以在声明一个Series对象时给它指定标签:
import pandas as pd
ser=pd.Series([12,33,55,66],index=['a','s','d','f'])
print(ser) '''输出为:
a 12
s 33
d 55
f 66
dtype: int64
'''
import pandas as pd
ser=pd.Series([12,33,55,66])
print(ser[2])
ser[2]=99
print(ser[2]) '''输出为:
55
99
'''
import pandas as pd
ser=pd.Series([12,33,55,66])
ser2=ser/2
print(ser2) import numpy as np
print(np.log(ser)) '''输出为:
0 6.0
1 16.5
2 27.5
3 33.0
dtype: float64
0 2.484907
1 3.496508
2 4.007333
3 4.189655
dtype: float64
'''
import pandas as pd
dic={'wife':'kathy','son':'mary','mother':'lily','father':'tom'}
ser=pd.Series(dic)
print(ser) '''输出为:
wife kathy
son mary
mother lily
father tom
dtype: object
'''
四、DataFrame的使用
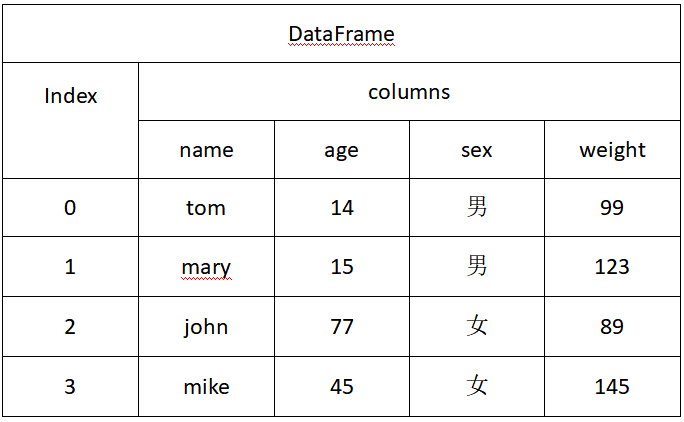
import pandas as pd
dic={'name':['tom','mary','john','mike'],'age':[14,15,77,45],'sex':['男','男','女','男']}
frame=pd.DataFrame(dic)
print(frame) '''输出为:
name age sex
0 tom 14 男
1 mary 15 男
2 john 77 女
3 mike 45 男
'''
import pandas as pd
dic={'name':['tom','mary','john','mike'],'age':[14,15,77,45],'sex':['男','男','女','男']}
frame=pd.DataFrame(dic)
frame['weight']=[89,99,145,123]
print(frame) '''输出为:
name age sex weight
0 tom 14 男 89
1 mary 15 男 99
2 john 77 女 145
3 mike 45 男 123
'''
import pandas as pd
dic={'name':['tom','mary','john','mike'],'age':[14,15,77,45],'sex':['男','男','女','男']}
frame=pd.DataFrame(dic)
print(frame.T) '''输出为:
0 1 2 3
name tom mary john mike
age 14 15 77 45
sex 男 男 女 男
'''
五、Series与DataFrame对象之间的运算
import pandas as pd
import numpy as np
frame=pd.DataFrame(np.arange(16).reshape((4,4)),index=['age','name','sex','weight'],columns=['john','tom','mary','cathy'])
print(frame)
ser=pd.Series(np.arange(4),index=['john','tom','mary','cathy'])
print(ser)
res=frame-ser
print(res) '''输出为:
john tom mary cathy
age 0 1 2 3
name 4 5 6 7
sex 8 9 10 11
weight 12 13 14 15 john 0
tom 1
mary 2
cathy 3
dtype: int32 john tom mary cathy
age 0 0 0 0
name 4 4 4 4
sex 8 8 8 8
weight 12 12 12 12
'''
Python数据分析之pandas入门的更多相关文章
- Python 数据处理库 pandas 入门教程
Python 数据处理库 pandas 入门教程2018/04/17 · 工具与框架 · Pandas, Python 原文出处: 强波的技术博客 pandas是一个Python语言的软件包,在我们使 ...
- Python数据分析库pandas基本操作
Python数据分析库pandas基本操作2017年02月20日 17:09:06 birdlove1987 阅读数:22631 标签: python 数据分析 pandas 更多 个人分类: Pyt ...
- Python数据分析之pandas基本数据结构:Series、DataFrame
1引言 本文总结Pandas中两种常用的数据类型: (1)Series是一种一维的带标签数组对象. (2)DataFrame,二维,Series容器 2 Series数组 2.1 Series数组构成 ...
- Python 数据分析:Pandas 缺省值的判断
Python 数据分析:Pandas 缺省值的判断 背景 我们从数据库中取出数据存入 Pandas None 转换成 NaN 或 NaT.但是,我们将 Pandas 数据写入数据库时又需要转换成 No ...
- 利用python进行数据分析之pandas入门
转自https://zhuanlan.zhihu.com/p/26100976 目录: 5.1 pandas 的数据结构介绍5.1.1 Series5.1.2 DataFrame5.1.3索引对象5. ...
- Python数据分析之pandas学习
Python中的pandas模块进行数据分析. 接下来pandas介绍中将学习到如下8块内容:1.数据结构简介:DataFrame和Series2.数据索引index3.利用pandas查询数据4.利 ...
- python数据分析之pandas数据选取:df[] df.loc[] df.iloc[] df.ix[] df.at[] df.iat[]
1 引言 Pandas是作为Python数据分析著名的工具包,提供了多种数据选取的方法,方便实用.本文主要介绍Pandas的几种数据选取的方法. Pandas中,数据主要保存为Dataframe和Se ...
- Python数据分析之pandas
Python中的pandas模块进行数据分析. 接下来pandas介绍中将学习到如下8块内容:1.数据结构简介:DataFrame和Series2.数据索引index3.利用pandas查询数据4.利 ...
- Python数据分析之Pandas操作大全
从头到尾都是手码的,文中的所有示例也都是在Pycharm中运行过的,自己整理笔记的最大好处在于可以按照自己的思路来构建矿建,等到将来在需要的时候能够以最快的速度看懂并应用=_= 注:为方便表述,本章设 ...
随机推荐
- HDU3572构造图的模型
第一次面对建模的图,也映照了我以前想的算法不是重点,问题的转化才是重点 Description: N个任务,M台机器,对于每一个任务有p,s,e表示该任务要做p个时长,要从[s,……)开始,从(……e ...
- HTTP状态代码列表
httpContext.Response.StatusCode=200 1xx - 信息提示这些状态代码表示临时的响应.客户端在收到常规响应之前,应准备接收一个或多个 1xx 响应. · 100 - ...
- 深入探索AngularJS
目录 深入探索AngularJS 作用域Scope是DOM和Directives交互的抽象 Scope是POJO对象 Scope是上下文 Scope继承树 Scope附加功能 正交功能 Element ...
- intellij 快捷键整理
[常规] Ctrl+Shift + Enter,语句完成 “!”,否定完成,输入表达式时按 “!”键 Ctrl+E,最近的文件 Ctrl+Shift+E,最近更改的文件 Shift+Click,可以关 ...
- 常见配置redis.conf介绍
参数说明redis.conf 配置项说明如下:1. Redis默认不是以守护进程的方式运行,可以通过该配置项修改,使用yes启用守护进程 daemonize no2. 当Redis以守护进程方式运行 ...
- C/C++掌握技能(一)
1.在编译器中输入代码并将其保存为.cpp文件(C语言的文件扩展名.c,但为了使用C++中的一些好用的特性,请把文件扩展名改为C++的.cpp)2.等价头文件:#include<stdio.h& ...
- 复习 C++ 中类的函数指针
函数指针这种东西,平时工作中基本上不会用到. 那函数指针会用在哪里? 下面是一些基本的用法,根据消息号调到对应的函数: #include <iostream> #include <m ...
- Python MySQL - 创建/查询/删除数据库
#coding=utf-8 import mysql.connector import importlib import sys #连接数据库的信息 mydb = mysql.connector.co ...
- log4j的日志级别(ssm中log4j的配置)
log4j定义了8个级别的log(除去OFF和ALL,可以说分为6个级别),优先级从高到低依次为:OFF.FATAL.ERROR.WARN.INFO.DEBUG.TRACE. ALL. 1. ALL ...
- iOS---代理、协议、通知 详解
一.代理 1.代理的介绍 代理是一种通用的设计模式 代理使用方式:A 让 B 做件事,空口无凭,签个协议. 所以代理有三部分组成: 委托方: 定义协议 协议 : 用来规定代理方可以做什么,必须做什 ...