Html Agility Pack解析Html(C#爬虫利器)
有个需求要写网络爬虫,以前接触过一个叫Html Agility Pack这个解析html的库,这次又要用到,然而发现以前咋用的已经不记得了,现在从头开始记录一下使用过程.
Html Agility Pack官网.大家用的同时也可以去github上star一下这个项目,支持一下.net开源项目.(首页上有其github的项目地址)
加载Html
有几种方式可以加载Html
从流(Stream)中加载
HtmlWebRequest req = WebRequest.Create("https://www.cnblogs.com/Laggage/p/10740012.html") as HtmlWebRequest;
HtmlWebResponse res = req.GetResponse() as HtmlWebResponse;
Stream s = res.GetResponseStream(); HtmlDocument doc = new HtmlDocument();
doc.Load(s)
从字符串加载Html(直接用的官网的一个例子)
var html = @"<!DOCTYPE html>
<html>
<body>
<h1>This is <b>bold</b> heading</h1>
<p>This is <u>underlined</u> paragraph</p>
<h2>This is <i>italic</i> heading</h2>
</body>
</html> "; var htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(html); var htmlBody = htmlDoc.DocumentNode.SelectSingleNode("//body"); Console.WriteLine(htmlBody.OuterHtml);
从文件加载
string path = @"test.html"; HtmlDocument doc = new HtmlDocument();
doc.Load(path); HtmlNode node = doc.DocumentNode.SelectSingleNode("//body"); Console.WriteLine(node.OuterHtml);
还可以直接从网络上加载(套用官网的例子)
string html = @"http://html-agility-pack.net/"; HtmlWeb web = new HtmlWeb(); HtmlDocument htmlDoc = web.Load(html); HtmlNode node = htmlDoc.DocumentNode.SelectSingleNode("//head/title"); Console.WriteLine("Node Name: " + node.Name + "\n" + node.OuterHtml);
解析html
利用Html Agility Pack解析起html还是很容易的.主要利用XPath语法.同样套用官网的代码.
HtmlDocument htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(html);
string name = htmlDoc.DocumentNode
.SelectNodes("//td/input") //双斜杠表示查询所有的子节点,如果是只要查询范围在当前节点的下一层子节点,则只用一个子节点.
.First()
.Attributes["value"].Value;
主要就是利用 HtmlNode.SelectSingleNode()和HtmlNode.SelectNodes()方法来寻找节点.
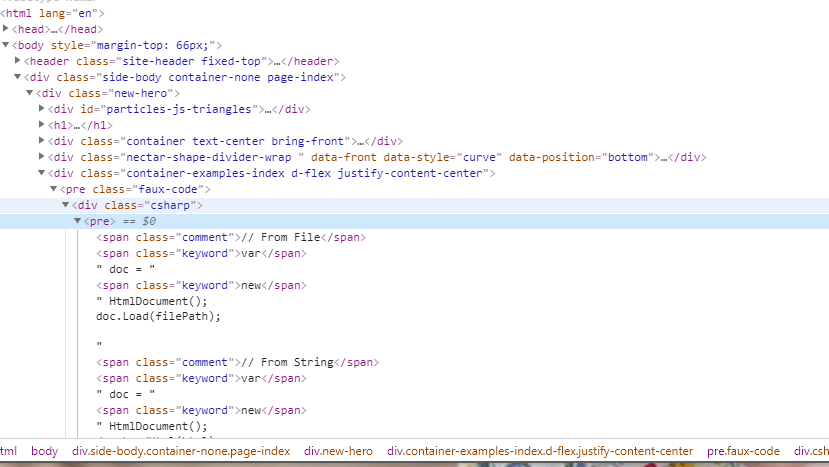
这是 Html Agility Pack 官网首页的一段html,现在以要拿到其中的pre标签的所有内容为例.
string url = @"https://html-agility-pack.net/";
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load(html);
string text = doc.DocumentNode
.SelectSingleNode("//div[@class='side-body container-none page-index']/div[@class='container-examples-index d-flex justify-content-center']/pre")
.InnerText;
Console.WriteLine(text);
具体的XPath语法可以看W3C的教程:W3CXPath教程.
</div>Html Agility Pack解析Html(C#爬虫利器)的更多相关文章
- Html Agility Pack解析HTML页
文章来源:Html Agility Pack解析HTML页 现在,在不少应用场合中都希望做到数据抓取,特别是基于网页部分的抓取.其实网页抓取的过程实际上是通过编程的方法,去抓取不同网站网页后,再进行分 ...
- Html Agility Pack 解析Html
Hello 好久不见 哈哈,今天给大家分享一个解析Html的类库 Html Agility Pack.这个适用于想获取某网页里面的部分内容.今天就拿我的Csdn的博客列表来举例. 打开页面 用Fir ...
- [c#] Html Agility Pack 解析HTML
摘要 在开发过程中,很有可能会遇到这样的情况,服务端返回的是html的内容,但需要在客户端显示纯文本内容,这时候就需要解析这些html,拿到里面的纯文本.达到这样的目的可以有很多途径,比如自己写正则表 ...
- C# 网络爬虫利器之Html Agility Pack如何快速实现解析Html
简介 现在越来越多的场景需要我们使用网络爬虫,抓取相关数据便于我们使用,今天我们要讲的主角Html Agility Pack是在爬取的过程当中,能够高效的解析我们抓取到的html数据. 优势 在.NE ...
- Html Agility Pack基础类介绍及运用
第一篇只对Html Agility Pack做了一个大概的介绍,在接下来的章节会比较深入的介绍Html Agility Pack. Html Agility Pack 源码中的类大概有28个左右,其实 ...
- C#解析HTML利器-Html Agility Pack
今天刚开始做毕设....好吧,的确有点晚.我的毕设设计需要爬取豆瓣的电影推荐,于是就需要解析爬取下来的html,之前用Python玩过解析,但目前我使用的是C#,我觉得C#不比python差,有微软大 ...
- 强大而灵活的的Html解析器——Html Agility Pack
一.概述 Html Agility Pack 简称HAP,是一个强大而灵活的解析Html DOM的.Net类库. 二.官方链接 官网:http://html-agility-pack.net/ NuG ...
- 开源项目Html Agility Pack实现快速解析Html
这是个很好的的东西,以前做Html解析都是在用htmlparser,用的虽然顺手,但解析速度较慢,碰巧今天找到了这个,就拿过来试,一切出乎意料,非常爽,推荐给各位使用. 下面是一些简单的使用技巧,希望 ...
- 使用Html Agility Pack快速解析Html内容
Html Agility Pack 是一个开源的.NET 方案HTML解析器. 开源地址:https://github.com/zzzprojects/html-agility-pack 用法:vs上 ...
随机推荐
- 20180613更新 leetcode刷题
最近就是忙工作项目 工作间隙就刷了刷LEETCODE 所以没啥更新 // 1111111.cpp: 定义控制台应用程序的入口点. // #include "stdafx.h" #i ...
- mybatis3.2初学感悟
新手,学了mybatis框架一周,写点感悟下来. mybatis,是操作数据库,持久层的一个框架,它是对JDBC的封装.看到了这个框架,我突然感受到封装与抽象的力量.也明白了些为什么要分层的原因. 记 ...
- SpringBoot定制修改Servlet容器
1.如何修改Servlet容器的相关配置: 第一种:在application.properties中修改和server有关的配置(ServerProperties提供): server.port=80 ...
- 【Java】使用Apache POI生成和解析Excel文件
概述 Excel是我们平时工作中比较常用的用于存储二维表数据的,JAVA也可以直接对Excel进行操作,分别有jxl和poi,2种方式. HSSF is the POI Project's pure ...
- innodb_log_buffer_size和innodb_buffer_pool_size参数说明
innodb_log_buffer_size Command-Line Format --innodb_log_buffer_size=# System Variable Name innodb ...
- JSON.parse和JSON.stringify的区别
JSON.stringify()的作用是将 JavaScript 值转换为 JSON 字符串, 而JSON.parse()可以将JSON字符串转为一个对象. 简单点说,它们的作用是相对的,我用JSON ...
- Codeforces Round #543 (Div. 2)B,C
https://codeforces.com/contest/1121 B 题意 给你n(<=1000)个数ai,找出最多对和相等的数,每个数只能用一次,且每个数保证各不相同 题解 重点:每个数 ...
- Win7 VS2015及MinGW环境编译矢量库agg-2.5和cairo-1.14.6
书接上文,昨天装了MinGW,主要原因之一是要用到MSYS,所以顺手把FFMPEG又编译了一遍. 回到主题,其实我是想编译矢量库,因为最近要学习一些计算几何算法,所以找个方便的2D画图库就很重要. 说 ...
- java项目显示红叉,程序却没有错误
转 http://blog.sina.com.cn/s/blog_825b7d7c0102w7rq.html (2016-07-02 11:38:38) 分类: javaWeb 电脑换了不同版本的 ...
- c语言结构体链表
原文链接:http://zhina123.blog.163.com/blog/static/417895782012106036289/ 引用自身的结构体,一个结构体中有一个或多个成员的基类型就是本结 ...