pathon 基础学习-集合(set),单双队列,深浅copy,内置函数
collections其实是python的标准库,也就是python的一个内置模块,因此使用之前导入一下collections模块即可,collections在python原有的数据类型str(字符串), int(数值), list(列表) tuple(元组), dict(字典)的基础之上增加一些其他的数据类型即方法,具体如下:
1、Counter(dict):计数器,扩展的字典的方法,对指定数据的字串做统计出现的次数,结果是一个元组,如:

1 import collections
2 li = ("asdasdsdasdahjlklknlknfd")
3 a = collections.Counter(li)
4 print(a)
5
6 执行结果:
7 Counter({'d': 5, 's': 4, 'a': 4, 'k': 3, 'l': 3, 'n': 2, 'j': 1, 'h': 1, 'f': 1})
2、most_common():不加参数以列表里面加元组方式显示每个字符串出现多少次,加数字表示最少出现括号里面传递的数字次数,如:
1 import collections
2 li = ("asdasdsdasdahjlklknlknfd")
3 a = collections.Counter(li)
4 print(a.most_common(2)) #显示出现次数最多的前2个
5 print(a.most_common(5)) #显示出现次数最多的前5个
6
7 执行结果:
8 [('d', 5), ('s', 4)]
9 [('d', 5), ('s', 4), ('a', 4), ('k', 3), ('l', 3)]
3、collections.items:以字典结果方式显示每个元素出现的次数生成一个迭代器,可以使用for循环遍历每个元素:,如下:
1 import collections
2 li = ("asdasdsdasdahjlklknlknfd")
3 a = collections.Counter(li)
4 for k,v in a.items(): #相当是对collections.Counter的结果又做了二次操作
5 print(k,v)
6
7 执行结果:
8 j 1
9 f 1
10 l 3
11 d 5
12 h 1
13 n 2
14 k 3
15 a 4
16 s 4
4、collections.elements:获取每个到每个元素并生成一个迭代器,可以使用for循环遍历每个元素:
1 import collections
2 li = ("asdasdsdasdahjlklknlknfd")
3 a = collections.Counter(li)
4 for k in a.elements():
5 print(k)
5、collections.update:对同一个元素的出现次数进行增加更新:
1 import collections
2 li = "nihao" #原始字符串
3 a = collections.Counter(li) #统计每个元素出现的次数
4 print(a) #打印元素 字符串每个元素出现的次数
5 a.update("hello") #更新字符串元素
6 print(a) #打印更新后的元素出现次数
7
8 执行结果:
9 Counter({'o': 1, 'i': 1, 'h': 1, 'n': 1, 'a': 1}) #原始的字符串出现次数
10 Counter({'o': 2, 'l': 2, 'h': 2, 'i': 1, 'n': 1, 'a': 1, 'e': 1}) #更新后的字符串元素出现次数
5、subtract:对同一个元素做减处理,如下:
1 import collections
2 li = "nihao" #原始字符串
3 a = collections.Counter(li) #统计每个元素出现的次数
4 print(a)
5 a.subtract("hello") #打印元素 字符串每个元素出现的次数
6 print(a) #打印更新后的元素出现次数
7
8 执行结果:
9 Counter({'a': 1, 'h': 1, 'o': 1, 'i': 1, 'n': 1}) #更新之前每个元素的出现次数
10 Counter({'a': 1, 'i': 1, 'n': 1, 'o': 0, 'h': 0, 'e': -1, 'l': -2}) #更新之后的每个元素的出现次数,与update相反,是对原数据进行减操作,如果元素没有则会标记元素为-1,在减一次为-2,对这个元素update一次则增加为-1,如:
11 import collections
12 li = "nihao" #原始字符串
13 a = collections.Counter(li) #统计每个元素出现的次数
14 print(a)
15 a.subtract("hello") #打印元素 字符串每个元素出现的次数
16 print(a) #打印更新后的元素出现次数
17
18 a.update("llo")
19 print(a)
20
21 执行结果:
22 Counter({'a': 1, 'o': 1, 'h': 1, 'i': 1, 'n': 1})
23 Counter({'a': 1, 'n': 1, 'i': 1, 'o': 0, 'h': 0, 'e': -1, 'l': -2})
24 Counter({'a': 1, 'n': 1, 'o': 1, 'i': 1, 'h': 0, 'l': 0, 'e': -1}) #l的次数转正了
6、del:删除指定的元素:会删除元素和元素的计数值:
1 import collections
2 li = "nihao" #原始字符串
3 a = collections.Counter(li) #统计每个元素出现的次数
4 print(a,"原字符串")
5 a.subtract("heello") #打印元素 字符串每个元素出现的次数
6 print(a,"做减操作的字符串")
7 del a["l"]#打印元素 字符串每个元素出现的次数
8 del a["e"]
9 print(a,"使用del删除元素的字符串") #打印更新后的元素出现次数
10
11 执行结果:
12 Counter({'i': 1, 'o': 1, 'h': 1, 'n': 1, 'a': 1}) 原字符串
13 Counter({'i': 1, 'n': 1, 'a': 1, 'o': 0, 'h': 0, 'l': -2, 'e': -2}) 做减操作的字符串
14 Counter({'i': 1, 'n': 1, 'a': 1, 'o': 0, 'h': 0}) 使用del删除元素的字符串,删除后即使该元素的次数为-2也可以只接全部删除元素和元素的出现次数,即会会删除元素本身和其计数
7、get:获取指定元素出现的次数:
1 import collections
2 li = "nihaoiinn" #原始字符串
3 a = collections.Counter(li) #统计每个元素出现的次数
4 print(a.get("n")) #获取指定元素的出现次数
5
6 执行结果:
7 3 #表示n在此字符创当中一共出现了3次
8.copy:是浅copy,浅copy只copy第一层,变量里面包含的列表或字典的id值和以前是不变的:
1 import collections
2 li = "nihaoiinn[jack]" #原始字符串
3 a = collections.Counter(li) #统计每个元素出现的次数
4 b = a.copy()
5 print(id(a),"id-->a的id")
6 print(id(b),"id-->b的id")
7
8 print(id(a[9]),"a的第九个元素的id")
9 print(id(b[9]),"b的第九个元素的id")
10
11 执行结果:
12 11335784 id-->a的id
13 11337064 id-->b的id
14 505605904 a的第九个元素的id
15 505605904 b的第九个元素的id
9、defaultdict:默认字典,在创建的时候指定该字典的默认数据格式,可以是列表、元组或列表等,如:
1 import collections
2 dic1 = collections.defaultdict(list)
3 dic1["k1"].append(1)
4 print(dic1)
5
6 执行结果:
7 defaultdict(<class 'list'>, {'k1': [1]}) #默认的数据格式为list,即元素的默认格式为list,可以使用列表的所有操作方法对字典的值进行操作
10.OrderedDict:有序字典,默认创建的字典是无需的,可以使用OrderedDict创建字典,这样字典内部会对key进行排序显示,key的顺序将会固定保持不变,如下:
1 import collections
2 d=collections.OrderedDict()
3 d['a']='111'
4 d['b']='222'
5 d['c']='333'
6 for k,v in d.items():
7 print(k,v)
8
9 执行结果:
10 a 111
11 b 222
12 c 333 #可以看到时按照是按照顺序排列的,而且刷新以后的顺序也会保持不变
13
14 下面创建一个默认的字典:
15 d={}
16 d['a']='111'
17 d['b']='222'
18 d['c']='333'
19 for k,v in d.items():
20 print(k,v)
21
22 执行结果:
23 c 333
24 a 111
25 b 222 #不是按照顺序排列的,而且每次刷新的顺序都不一致
有序字典的常用操作:
pop、删除指定的字典key,并返回被删除的value
1 import collections
2 dic1 = collections.OrderedDict({'name':'jack','age':20,'job':'IT'})
3 print(dic1)
4 print(dic1.pop("age"))
5 print(dic1)
6
7 执行结果:
8 OrderedDict([('name', 'jack'), ('job', 'IT'), ('age', 20)]) #删除之前的有序字典
9 20 #被删除的value
10 OrderedDict([('name', 'jack'), ('job', 'IT')]) #删除之后的有序字典
keys:获取有序字典的全部key,方法和字典是一样的:
1 import collections
2 dic1 = collections.OrderedDict({'name':'jack','age':20,'job':'IT'})
3 print(dic1.keys())
4
5 执行结果:
6 odict_keys(['name', 'age', 'job'])
values:获取有序字典所有的值,方法和字典是一样的:
1 import collections
2 dic1 = collections.OrderedDict({'name':'jack','age':20,'job':'IT'})
3 print(dic1.values()) 执行结果:
odict_values(['IT', 'jack', 20]) #所有的值
items:获取有序字典所有的键值对,方法和字典是一样的:
1 import collections
2 dic1 = collections.OrderedDict({'name':'jack','age':20,'job':'IT'})
3 print(dic1.items()) 执行结果;
odict_items([('name', 'jack'), ('job', 'IT'), ('age', 20)]) #所有的键值对
move_to_end:将指定的键值对移动到最后的位置:
1 import collections
2 dic1 = collections.OrderedDict({'name':'jack','age':20,'job':'IT'})
3 dic1.move_to_end("name") #将name移动到最后的位置
4 #print(dic1.pop("age"))
5 print(dic1)
6
7 执行结果:
8 OrderedDict([('age', 20), ('job', 'IT'), ('name', 'jack')]) #顺序已经发生变化,name到最后了
clear:清空有序字典的所有键值对:
1 import collections
2 dic1 = collections.OrderedDict({'name':'jack','age':20,'job':'IT'})
3 dic1.clear()
4 print(dic1)
5
6 执行结果:
7 OrderedDict() #字典已经为空
11、namedtuple:可命名元组,可以给元组命名,在通过元素的名称获取到元素的值,也可以使用元素的下标获取到元素的值:
1 import collections
2 Mytuple = collections.namedtuple("xy",['a','b']) # collections.namedtuple表示对一个元素命名,本为名称是xy,名称必须有,其包含有两个元素a和b
3 list1 = Mytuple(10,20) #实例化类,并传递两个参数进去
4 print(list1.a) #打印结果
5 print(list1[0])
6
7 #执行结果:
8 10 #10是a的值,即可以用元素的名称获取到元素的值
9 10 #通过下标获取到的元素的值
12、queue.Queue:单向队列,先进先出,类似于弹夹,先放去的子弹先打出来,只能从左边进行操作:
put,get,qsize,full:插入数据,获取数据,查看队列长度,判断队列是否已经满了:
1 import queue
2 d = queue.Queue(maxsize=3) #创建一个队列并指定最大长度为3个
3 d.put("a") #添加一个队列值
4 d.put("b") #添加一个队列值
5 d.put("c") #添加一个队列值
6 print(d.qsize()) #查看队列的当前长度
7 print(d.full()) #先判断队列是否已经满了
8 print(d.get()) #获取一个队列值
9 print(d.get()) #获取一个队列值
10 print(d.get()) #获取一个队列值
11 print(d.qsize()) #获取完队列值再次查看队列的长度
12 print(d.full()) #再次判断队列是否满了
13
14 执行结果:
15 3 #第一次已经显示队列是3个了
16 True #第一次队列是满的
17 a
18 b
19 c #获取三个值
20 0 #此时队列里面已经再没有数据了
21 False #之后队列就是空的了
empty:判断队列是否为空,是返回True,否返回False:
1 import queue
2 d = queue.Queue(maxsize=3)
3 d.put("a")
4 d.put("b")
5 d.put("c")
6 print(d.qsize())
7 print(d.get())
8 print(d.get())
9 print(d.get())
10 print(d.qsize())
11 print(d.empty(),"#判断是会否为空")
12
13 执行结果:
14 3 #首次的队列长度
15 a
16 b
17 c #获取三个值
18 0 #获取值之后的队列的长度为0
19 True #判断是会否为空,是返回True,否返回False
put_nowait:在队列可以插入的时候不阻塞插入数据数据,可以理解为不按排队顺序插队到最前面put数据:
get_nowait:在队队列有时间后不阻塞获取数据,可以理解为不按排队顺序插队到最前面get数据:
1 import queue
2 d = queue.Queue(maxsize=3)
3 d.put_nowait("a")
4 d.put_nowait("b")
5 d.put_nowait("c") #每获取一次数据,队列的长度减1
6 print(d.qsize())
7 print(d.get_nowait())
8 print(d.get_nowait())
9 print(d.get_nowait())
10 print(d.qsize())
11 print(d.empty(),"#判断是会否为空")
12
13 执行结果:
14 3
15 a
16 b
17 c
18 0
19 True #判断是会否为空
13、queue.deque:双向队列,可以左右两侧都进行操作的队列与单向队列最大的不同是可以从队列左右两侧都进行操作,
appendleft:添加元素到最左侧:
append:添加元素做最右侧,即末尾:
import queue
d = queue.deque(["a,","b","c",'d'])
print(d)
d.append("jack")
d.appendleft("tom")
print(d) 执行结果:
deque(['a,', 'b', 'c', 'd']) #添加之前的队列
deque(['tom', 'a,', 'b', 'c', 'd', 'jack']) #添加之后的队列 append,appendleft
count:统计队列中某个元素出现的次数,而不是某个字符串;
copy:是浅copy,只拷贝第一层,其内部包含的元素和列表的id是一样的
1 import queue
2 d = queue.deque(["a,","b","tom","c",'d',"tom"])
3 print(d)
4 print(d.count("tom"),"tom出现了两次,表示队列中的元素可以重名即可以重复")
5
6 a = d.copy()
7 print(id(a),"a的id")
8 print(id(d),"d的id")
9 print((a[3]),"a的第三个元素")
10 print(id(a[3]),"a的第三个元素的id")
11 print(id(d[3]),"a的第三个元素的id")
12
13 执行结果:
14 deque(['a,', 'b', 'tom', 'c', 'd', 'tom']) 原队列内容
15 2 tom出现了两次,表示队列中的元素可以重名即可以重复
16 12208024 a的id
17 12207920 d的id
18 c a的第三个元素
19 4803472 a的第三个元素的id
20 4803472 a的第三个元素的id
extend:对原队列进行右侧扩展,扩展的元素是是字符串,而append附加是元素,一个元素可以包含多个字符串,如果extend传递的一个包含多个字符串的元素,则会展开元素为多个字符串进行添加:
extendleft:对原队列进行左侧侧扩展,其他同extend
1 import queue
2 d = queue.deque(["a,","b","c",'d',"tom"])
3 print(d)
4 d.extend("jack") #右侧扩展jack
5 d.extendleft("lyly") #左侧扩展lyly
6 print(d)
7
8 执行结果:
9 deque(['a,', 'b', 'c', 'd', 'tom']) #扩展之前的队列
10 deque(['y', 'l', 'y', 'l', 'a,', 'b', 'c', 'd', 'tom', 'j', 'a', 'c', 'k']) #扩展之后的队列,扩展后会将元素拆开为多个字符串进行添加,与append大为不同
index:根据value获取其下标位:
insert:将元素插入到指定的下标位置:
1 import queue
2 d = queue.deque(["a,","b","c",'d',"tom"])
3 print(d)
4 d.insert(1,"jack")
5 print(d.index("jack"))
6 print(d)
7
8 执行结果:
9 deque(['a,', 'b', 'c', 'd', 'tom']) #insert之前的队列
10 1 #获取到的jack的下标位置
11 deque(['a,', 'jack', 'b', 'c', 'd', 'tom']) #打印insert之后的队列结果
reverse:将整个队列顺序反转显示,即倒数第一个为第一个,倒数第二个为第二个,一次类推
rotate:将最后指定数量的几个元素放在最前的位置
1 import queue
2 d = queue.deque(["a,","b","c",'d',"tom"])
3 print(d) #原队列顺序
4 d.reverse() #将整个队列顺序反转显示,即倒数第一个为第一个,倒数第二个为第二个,一次类推
5 print(d) #反转整个队列之后的结果
6
7 a = queue.deque(["a,","b","c",'d',"tom"]) #将最后指定数量的几个元素放在最前的位置
8 print(a) #原队列顺序
9 a.rotate(2) #反转两个元素
10 print(a) #反转2个元素之后的结果
pop:从右侧删除元素并返回被删除的元素
popleft:从左侧删除元素并返回被删除的元素
1 import queue
2 d = queue.deque(["a,","b","c",'d',"tom"])
3 print(d) #原队列顺序
4 print(d.pop()) #删除右侧第一个元素
5 print(d) #删除左右侧第一个元素之后的结果
6
7 a = queue.deque(["a","b","c",'d',"tom"])
8 print(a) #原队列顺序
9 print(a.popleft()) #删除最左侧的元素
10 print(a) #删除最左侧第一个元素之后的结果
11
12 执行结果:
13 deque(['a,', 'b', 'c', 'd', 'tom'])
14 tom #被删除的右侧元素
15 deque(['a,', 'b', 'c', 'd']) #删除右右侧第一个元素之后的结果
16 deque(['a', 'b', 'c', 'd', 'tom'])
17 a #被删除的左侧元素
18 deque(['b', 'c', 'd', 'tom']) #删除最左侧第一个元素之后的结果
remove:根据value删除元素
clear:清空整个队列
1 import queue
2 d = queue.deque(["a,","b","c",'d',"tom"])
3 print(d," #原队列顺序")
4 print(d.remove("d"),"#删除指定的value d")
5 print(d,"#删除d之后的结果")
6
7 a = queue.deque(["a","b","c",'d',"tom"])
8 print(a," #原队列顺序")
9 print(a.clear(),"#清空队列")
10 print(a," #清空队列之后的结果")
11
12 执行结果:
13 deque(['a,', 'b', 'c', 'd', 'tom']) #原队列顺序
14 None #删除指定的value d
15 deque(['a,', 'b', 'c', 'tom']) #删除d之后的结果
16 deque(['a', 'b', 'c', 'd', 'tom']) #原队列顺序
17 None #清空队列
18 deque([]) #清空队列之后的结果
二:深浅copy:
copy:称为浅copy,默认的copy都是浅coyp,即没有特定使用深copy的操作,浅copy只copy第一层,即不copy内部的列表、字典或元组(假如有以上元素),可以用元素的id区分
deepcopy:深copy,会copy每一层的元素,包含copy内部的元组、字段或列表
假如copy对象都是字符串:
1 import copy
2 #a = [123,"a","b","c",456,("tom",["it","18"]),{"jack":{"age":12}}]
3 a = "123456abcd"
4 b = copy.copy(a)
5 c = copy.deepcopy(a)
6 print(a)
7 print(b)
8 print(c) #每个变量的内容
9 print(id(a))
10 print(id(b))
11 print(id(c)) #每个变量的id
12 print(id(a[4]))
13 print(id(b[4]))
14 print(id(c[4])) #每个变量的同一个元素的id值
15
16 执行结果:
17 123456abcd
18 123456abcd
19 123456abcd #三个变量的值
20 7549552
21 7549552
22 7549552 #三个变量的id是相同的
23 7454368
24 7454368
25 7454368 #三个变量的同一个元素的id也是相同的
假如copy对象有列表并修改列表的值:
1 import copy
2 a = [123,"a","b","c",456,["tom",["it","18"]],{"jack":{"age":12}}]
3 b = copy.copy(a) #b是浅copy的a的值,可以简写为b = a
4 c = copy.deepcopy(a) #c是深copy的a的值
5 print(a) #a的内容
6 print(b) #b的内容
7 print(c) #c的内容
8 #############查看第一层的元素的id
9 print(id(a)) #a的id
10 print(id(b)) #b的id
11 print(id(c)) #c的id
12 #############查看第二层的元素的id
13 print(c[5]) #获取一个元素
14 print(id(a[5])) #a的第5个元素的id值
15 print(id(b[5])) #b是浅copy,查看b的第5个元素的id值
16 print(id(c[5])) #c是深copy,查看c的第5个元素的id值
17
18 #############查看第三层的元素id
19 print(c[5][0]) #第5个元素的是一个元组,获取到该元组的第一个元素是tom
20 print(id(a[5][0])) #查看元组中的元素的ID值
21 print(id(b[5][0])) #查看元组中的元素的ID值
22 print(id(c[5][0])) #查看元组中的元素的ID值
23
24
25 执行结果:
26 [123, 'a', 'b', 'c', 456, ['tom', ['it', '18']], {'jack': {'age': 12}}] #a的内容
27 [123, 'a', 'b', 'c', 456, ['tom', ['it', '18']], {'jack': {'age': 12}}] #b的内容
28 [123, 'a', 'b', 'c', 456, ['tom', ['it', '18']], {'jack': {'age': 12}}] #c的内容
29 14771656 #第一层原a的id
30 11150920 #第一层浅copy之后b的id,可以发现包含了列表之后和a的id也不一样了,上个例子如果只是字符串还是一样的
31 14772168 #第一层深copy之后c的id
32 ('tom', ['it', '18']) #获取到第二层的元素
33 11060424 #a第二层的元素id
34 11060424 #b第二层的元素id
35 11079624 #c第二层的元素id
36 tom #第三层的元素
37 11048360 #a的第三层的元素id
38 11048360 #b的第三层的元素id
39 11048360 #c的第三层的元素id #可以发现最底层的元素id是一样的,最底层是把元素做了链接
40
41
42 #############修改copy源的第三层的元素的值,再看深浅copy的自底层的元素值:
43 a[5][1][0] = "CTO" #此元素为修改之前为it
44 print(id(a[5][0])) #查看元组中的元素的ID值
45 print(id(b[5][0]))
46 print(id(c[5][0]))
47
48 执行结果:
49 14390696 #a修改第三层后的第三层元素的id
50 14390696 #修改后b也发生变化
51 14390696 #a也发生了变化,可见深copy之后最底层的元素是链接到了a的最底层之上,这样节省空间也免去了copy的步骤从而节约了时间
52
53
54 #############修改深copy之后的元素的值,查看a和b是否受影响:
55 print("###########")
56 c[5][1][0] = "CTO" #为指定元素重新赋值
57 print(c[5][1][0]) #打印修改后的元素的结果,验证是否修改成功
58 print(id(a[5][0])) #查看修改后a的此元素的值
59 print(id(b[5][0])) #查看修改后b的此元素的值,
60
61 执行结果:
62 CTO
63 12096936
64 12096936
65 12096936 #以上id都是一样的,可见修改深copy之后最底层的值,会影响到copy源本身和浅copy之后的值
66
67
68 #############修改浅copy之后的元素的值,查看a和b是否受影响:
69 b[5][1][0] = "CTO"
70 print(b[5][1][0])
71 print(id(a[5][0])) #查看元组中的元素的ID值
72 print(id(b[5][0]))
73 print(id(c[5][0]))
74
75 执行结果:
76 CTO
77 14325160
78 14325160
79 14325160 #三个元素的id是一样的,可见即使修改浅copy的底层元素的值也会影响到copy源本身和身copy的元素id值
假如copy对象是字典:
1 import copy
2 a = {"CPU":[80],"MEM":[80],"Disk":[80],}
3 b = copy.copy(a)
4 c = copy.deepcopy(a)
5
6 print(a,"a原字典")
7 print(b,"b浅copy原字典")
8 print(c,"c深copy原字典")
9 print(id(a),"原字典的id")
10 print(id(b),"浅copy的id")
11 print(id(c),"深copy的id")
12
13
14 #############################修改copy源
15 a["CPU"][0] = 50 #对copy源的元素值做修改
16 #print(["CPU"][0])
17 print(id(a["CPU"][0]),"原字典的元素id")
18 print(id(b["CPU"][0]),"浅copy的元素id")
19 print(id(c["CPU"][0]),"深copy的元素id")
20 print(a["CPU"][0],"原元素")
21 print(b["CPU"][0],"浅copy元素值")
22 print(c["CPU"][0],"深copy元素值")
23
24 执行结果:
25 {'MEM': [80], 'Disk': [80], 'CPU': [80]} a原字典
26 {'MEM': [80], 'Disk': [80], 'CPU': [80]} b浅copy原字典
27 {'MEM': [80], 'Disk': [80], 'CPU': [80]} c深copy原字典
28 13825672 原字典的id
29 14370696 浅copy的id
30 14271368 深copy的id
31 493417808 原字典的元素id
32 493417808 浅copy的元素id
33 493418768 深copy的元素id
34 50 原元素
35 50 浅copy元素值,可见修改字典类型的copy源会影响其本身和浅copy的元素值,不会影响到深copy,这是因为浅copy只是copy了表面,内部是做的链接
36 80 深copy元素值,深copy对于字典是从第一层到最末一层完全copy的,没有使用链接
37
38
39 ###########################修改浅copy的元素值
40 b["CPU"][0] = 50 #对浅拷贝之后的CPU的值做修改,b是浅copy
41 print(id(a["CPU"][0]),"原字典的元素id")
42 print(id(b["CPU"][0]),"浅copy的元素id")
43 print(id(c["CPU"][0]),"深copy的元素id")
44 print(a["CPU"][0],"原元素")
45 print(b["CPU"][0],"浅copy元素值")
46 print(c["CPU"][0],"深copy元素值")
47
48 执行结果:
49 {'MEM': [80], 'Disk': [80], 'CPU': [80]} a原字典
50 {'Disk': [80], 'CPU': [80], 'MEM': [80]} b浅copy原字典
51 {'Disk': [80], 'CPU': [80], 'MEM': [80]} c深copy原字典
52 6289032 原字典的id
53 11224968 浅copy的id
54 11125640 深copy的id
55 503051600 原字典的元素id
56 503051600 浅copy的元素id
57 503052560 深copy的元素id
58 50 原元素
59 50 浅copy元素值
60 80 深copy元素值,可见修改浅copy影响的范围和修改copy源本身的范围是一样的,只会影响copy源和浅copy,深copy不受其影响
61
62
63 #############################修改深copy的元素值
64 c["CPU"][0] = 50 #对深拷贝之后的CPU的值做修改,c是深copy
65 print(id(a["CPU"][0]),"原字典的元素id")
66 print(id(b["CPU"][0]),"浅copy的元素id")
67 print(id(c["CPU"][0]),"深copy的元素id")
68 print(a["CPU"][0],"原元素")
69 print(b["CPU"][0],"浅copy元素值")
70 print(c["CPU"][0],"深copy元素值")
71
72 执行结果:
73 {'Disk': [80], 'MEM': [80], 'CPU': [80]} a原字典
74 {'Disk': [80], 'MEM': [80], 'CPU': [80]} b浅copy原字典
75 {'Disk': [80], 'MEM': [80], 'CPU': [80]} c深copy原字典
76 13760136 原字典的id
77 14305160 浅copy的id
78 14205832 深copy的id
79 499448080 原字典的元素id
80 499448080 浅copy的元素id
81 499447120 深copy的元素id
82 80 原元素
83 80 浅copy元素值
84 50 深copy元素值,可见深copy只影响深copy本身,不影响copy源和浅copy,由此可以断定深copy对于字典是完全copy,包括key和value都是完全copy一份,copy完之后就和copy源没有任何关联了。
深浅copy总结:
1、假如copy源只是字符串,则深浅copy没有区别,只是copy后变量名称的id值不一样,其内部的元素的id值是一致的。
2、假如copy是列表组成,则会将内部的列表完全copy一份,其内部的元素的id会指向copy源的底层元素,假如对元素做了一份浅copy和深copy,则无论是修改了copy源的底层元素、浅copy的底层元素还是深copy的底层元素,都会影响到元素本身和其他copy的元素改变。
3、假如copy源是字典,则深会对字典的key和value完全copy,浅copy依然是对内部的元素做链接到copy源,修改copy源和浅copy只会影响浅copy源和浅copy,不会影响到深copy,同样修改深copy也不会影响到以上浅copy和浅copy源本身。
三:yield 和return:
yield:是一个生成器,在函数里用于记住上一次的操作,下次在执行的时候从当前的位置继续执行,生成器生成的值需要用for循环才能访问到:
1 def func(arg):
2 print(arg,"第一次")
3 yield "a" #以实参作为返回值
4 print(arg,"第二次")
5 yield "b"
6 a = func("a")
7 for i in a:
8 print(i)
9
10 执行结果:
11 a 第一次
12 a #第一次yield的值
13 a 第二次
14 b #第二次yield的值
15
16 #在整个函数运行的时候,先进入到函数内部,执行 print(arg,"第一次")之后遇到yield "a"并执行后返回到for循环print(i),然后再从for循环跳转到函数内部执行print(arg,"第二次")和yield "b",即在函数内部遇到yield会暂停函数内部运行,跳出后遇有调用的时候在从跳出的yield位置继续运行。
return:函数的返回值,遇到return的时候函数会停止继续运行,并以return的返回值赋值给函数本身,一个函数只能有一个return,多余的也不会执行,因为第一个return之后函数就停止运行了。
1 def func():
2 name = "jack"
3 return name
4 age = 18
5 return age
6 print(func()) #打印函数的值,返回值会赋值给函数的名称调用
7
8 执行结果:
9 jack #遇到return跳出后就停止运行函数,并就此终止函数,因此不会执行age的代码
四:集合(set)
set的元素是不能重复出现的,而且是无序排列的,如创建一个包含重复字串的集合:
1 set1 = set("abcdefgabc")
2 print(set1)
3
4 执行结果;
5 {'g', 'c', 'd', 'b', 'e', 'a', 'f'} #可见是无序排列并将元素拆分为单个字串,并将重复的abc只显示了单个
set的常用操作方法:
add:向集合里面添加元素:
remove:删除指定的元素名,且没有返回值
pop:随机删除集合的元素并返回被删除的值
1 set1 = set("abcbdefgabc")
2 set1.add("tom")
3 print(set1)
4 print(set1.remove("b"),"remove删除元素需指定要删除的元素名称,且没有返回")
5 print(set1)
6 print(set1.pop(),"pop删除元素无需参数,切会返回删除的元素")
7 print(set1)
8
9 执行结果:
10 {'g', 'e', 'd', 'b', 'a', 'tom', 'c', 'f'} #添加tom以后的集合
11 None #remove删除元素需指定要删除的元素名称,且没有返回,返回为None
12 {'g', 'e', 'd', 'a', 'tom', 'c', 'f'} #remove删除元素以后的集合
13 g #pop删除元素无需参数,切会返回删除的元素,本次为g
14 {'e', 'd', 'a', 'tom', 'c', 'f'} #pop删除元素以后集合
clear:清空元素列表:
copy:浅copy为另一个集合:
update:更新现有的集合:
1 set1 = set("abcbdefgabc")
2 print(set1,"set1原来的集合效果")
3 set1.update("tom")
4 print(set1,"updatede的tom的效果")
5
6 print("##########################")
7 set2 = set1.copy()
8 print(id(set2))
9 print(id(set1))
10
11
12 print("##########################")
13 set3 = set("abcbdefgabc")
14 print(set3,"set3原来的集合效果")
15 set3.clear()
16 print(set3,"set3的clear的效果")
17
18 执行结果:
19 {'f', 'e', 'g', 'a', 'b', 'c', 'd'} set1原来的集合效果
20 {'o', 'f', 'e', 'g', 'a', 'b', 'c', 'd', 't', 'm'} updatede的tom的效果
21 ##########################
22 14111688 #浅copy之前的set1的id
23 10215208 #浅copy之后的set3的id
24 ##########################
25 {'f', 'e', 'g', 'a', 'b', 'c', 'd'} set3原来的集合效果
26 set() set3的clear的效果
difference:用两个集合作比较,删除传递的参数并生成一个新的集合,只返回非传递的集合里没有的元素,并生成一个新的序列,如:
1 set1 = set("abcd")
2 set2 = set("abc")
3 set3 = set1.difference(set2)
4 print(set3)
5
6 执行结果;
7 {'d'} #返回set1有而set2没有的元素,本次为d
difference_update:删除原集合有并且传递的集合都有的值,这是在原集合直接操作的,删除完成以后查看原集合的值是否有变化:
1 set1 = set("abcd")
2 set2 = set("abce")
3 set1.difference_update(set2)
4 print(set1)
5
6 执行结果;
7 {'d'} #删除完成之后set1就只有一个d了,因为abc和在set2里面也,被删除了
discard:丢弃一个指定的元素:
1 set1 = set("abcd")
2 set1.discard("c") #丢弃c
3 print(set1)
4
5 执行结果:
6 {'a', 'd', 'b'}
intersection:交集运算,即取原集合和传递的集合共同都有的元素,并产生一个新的set集合:
1 set1 = set("abcd")
2 set2 = set("abce")
3 set3 = set1.intersection(set2) #取set1和set2共同含有的元素并赋值给set3
4 print(set3)
5
6 执行结果:
7 {'c', 'a', 'b'} #abc是set1和set2共同含有的元素
intersection_update:交集运算,即取原集合和传递的集合共同都有的元素,并直接赋值给原集合:
1 set1 = set("abcd")
2 set2 = set("abce")
3 set1.intersection_update(set2) #取set1和set2共同含有的值并赋值给set1
4 print(set1)
5
6 执行结果;
7 {'b', 'a', 'c'} #set1的值已经成为abc了
isdisjoint:判断是否没有交集,即判断是否没有同样的元素,没有返回True,有返回False:
1 set1 = set("abcd")
2 set2 = set("qwer")
3 print(set1.isdisjoint("aoiu"))
4 print(set1.isdisjoint(set2))
5
6 执行结果:
7 False #set1与aoiu有共同的元素a,所以返回False
8 True #set1与set2没有共同的元素,所以返回True
issubset:判断是否子集,即原集合是否传递集合的子集:
1 set1 = set("abcd")
2 set2 = set("abcdefg")
3 print(set1.issubset(set2))
4 print(set1.issubset("abcdefg"))
5
6 执行结果:
7 True #set1是set2的子集
8 True #set1是字符串abcdefg的子集
issuperset:与issubset相反,判断是否父集:
1 set1 = set("abcd")
2 set2 = set("abcdefg")
3 print(set2.issuperset(set1))
4 print(set1.issuperset("abcdefg"))
5
6 执行结果:
7 True #set2是set1的父集
8 False #set1不是abcdefg的父集
symmetric_difference:取出来两个集合相互没有的元素,并将结果赋值给一个新的集合:
1 set1 = set("abcdiop")
2 set2 = set("abcdefg")
3 set3 = set2.symmetric_difference(set1) #取出来两个集合相互没有的元素并赋值给set3
4 print(set3)
5
6 取差集:
7 {'g', 'e', 'i', 'f', 'p', 'o'} #取出来两个集合相互没有的元素
symmetric_difference_update:取出来两个集合相互没有的元素,并将结果赋值给原集合而不是赋值给一个新的集合:
1 set1 = set("abcdiop")
2 set2 = set("abcdefg")
3 set1.symmetric_difference_update(set2) #取两个集合相互都没有的元素并就地赋值给原集合set1
4 print(set1)
5
6 执行结果;
7 {'p', 'e', 'g', 'f', 'o', 'i'} #这就是set1的值,是取出两个集合相互没有的元素
union:去两个几个的并集,等于将两个集合的元素全部取出来并去重,最终每个元素只留一个:
1 set1 = set("abc")
2 set2 = set("abg")
3 set3 = set1.union(set2)
4 print(set3)
5
6 执行结果:
7 {'a', 'g', 'b', 'c'} #结果是每个元素都有而且每个元素只有一个的新的集合
有一个数据,需要通过集合的方式计算出需要更新、添加和删除的数据,最终要求是原来的没有新数据有就添加,原来有新的也有就更新,原来有新的没有删除,具体如下:
old_dict = {
"#1":{ 'hostname':"c1", 'cpu_count': 2, 'mem_capicity': 80 },
"#2":{ 'hostname':"c2", 'cpu_count': 2, 'mem_capicity': 80 },
"#3":{ 'hostname':"c3", 'cpu_count': 2, 'mem_capicity': 80 },
}
new_dict = {
"#1":{ 'hostname':"c2", 'cpu_count': 2, 'mem_capicity': 80 },
"#3":{ 'hostname':"c3", 'cpu_count': 2, 'mem_capicity': 80 },
"#4":{ 'hostname':"c4", 'cpu_count': 2, 'mem_capicity': 80 },
}
old = set(old_dict.keys()) #就的数据key
new = set(new_dict.keys()) #新的数据key
update_set = old.intersection(new) #交集运算,取出old和new共同含有的元素,并赋值给update_set,共同都有的数据是要更新的数据
delete_set = old.difference(update_set) #要删除的数据,用旧的数据删除要两边都有的数据,即得到要删除的数据
add_set = new.difference(update_set) #要更新的数据,
for i in update_set: #循环要更新的数据
print("要更新的数据是%s" % i)
old_dict[i] = new_dict.get(i) #将新的数据赋值给旧的字典,
print(old_dict,"更新数据的字典")
for i in delete_set:
print("要删除的数据是%s" % i)
old_dict.pop(i) #删除指定的要删除的数据
print(old_dict,"删除数据的字典")
for i in add_set:
print("要添加的数据是%s" % i)
old_dict[i] = new_dict.get(i)
print(old_dict)
执行结果:
要更新的数据是#1
{'#1': {'cpu_count': 2, 'mem_capicity': 80, 'hostname': 'c2'}, '#3': {'cpu_count': 2, 'mem_capicity': 80, 'hostname': 'c3'}, '#2': {'cpu_count': 2, 'mem_capicity': 80, 'hostname': 'c2'}} 更新数据的字典
要更新的数据是#3
{'#1': {'cpu_count': 2, 'mem_capicity': 80, 'hostname': 'c2'}, '#3': {'cpu_count': 2, 'mem_capicity': 80, 'hostname': 'c3'}, '#2': {'cpu_count': 2, 'mem_capicity': 80, 'hostname': 'c2'}} 更新数据的字典
要删除的数据是#2
{'#1': {'cpu_count': 2, 'mem_capicity': 80, 'hostname': 'c2'}, '#3': {'cpu_count': 2, 'mem_capicity': 80, 'hostname': 'c3'}} 删除数据的字典
要添加的数据是#4
{'#1': {'cpu_count': 2, 'mem_capicity': 80, 'hostname': 'c2'}, '#3': {'cpu_count': 2, 'mem_capicity': 80, 'hostname': 'c3'}, '#4': {'cpu_count': 2, 'mem_capicity': 80, 'hostname': 'c4'}}
五:模块变量:
__main__:判断是不是执行的主文件,当前文件为主执行文件的时候,其变量 __name__的名为__main__,如果有其他的模块或文件被调用到此文件,则其他的文件或模块的名称不会为__main__。
1 def func(arg):
2 print("func1",arg)
3
4 if __name__ == "__main__":
5 func(123)
6 print(__name__) #当前文件为主执行文件的时候,其文件名为__main__,其他被调用的文件名
7
8 执行结果:
9 func1 123
10 __main__ #打印name的值
vars() :当前模块的所有变量,file-当前文件的路径、doc-最开始的三个引号的注释
1 print(vars())
2
3 执行结果:
4 {'__doc__': '\nimport collections\nobj = collections.Counter("asdasdasdasdtghtiotl")\nprint(obj)\n\n\n', '__package__': None, '__file__': '/Users/zhangshijie/PycharmProjects/S12-Python3/Day3/s1.py', '__spec__': None, '__cached__': None, '__name__': '__main__', '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x1007a5be0>, '__builtins__': <module 'builtins' (built-in)>}
reload(os) #执行程序的时候,重新读取python的模块,用于对模块进行修改的情况
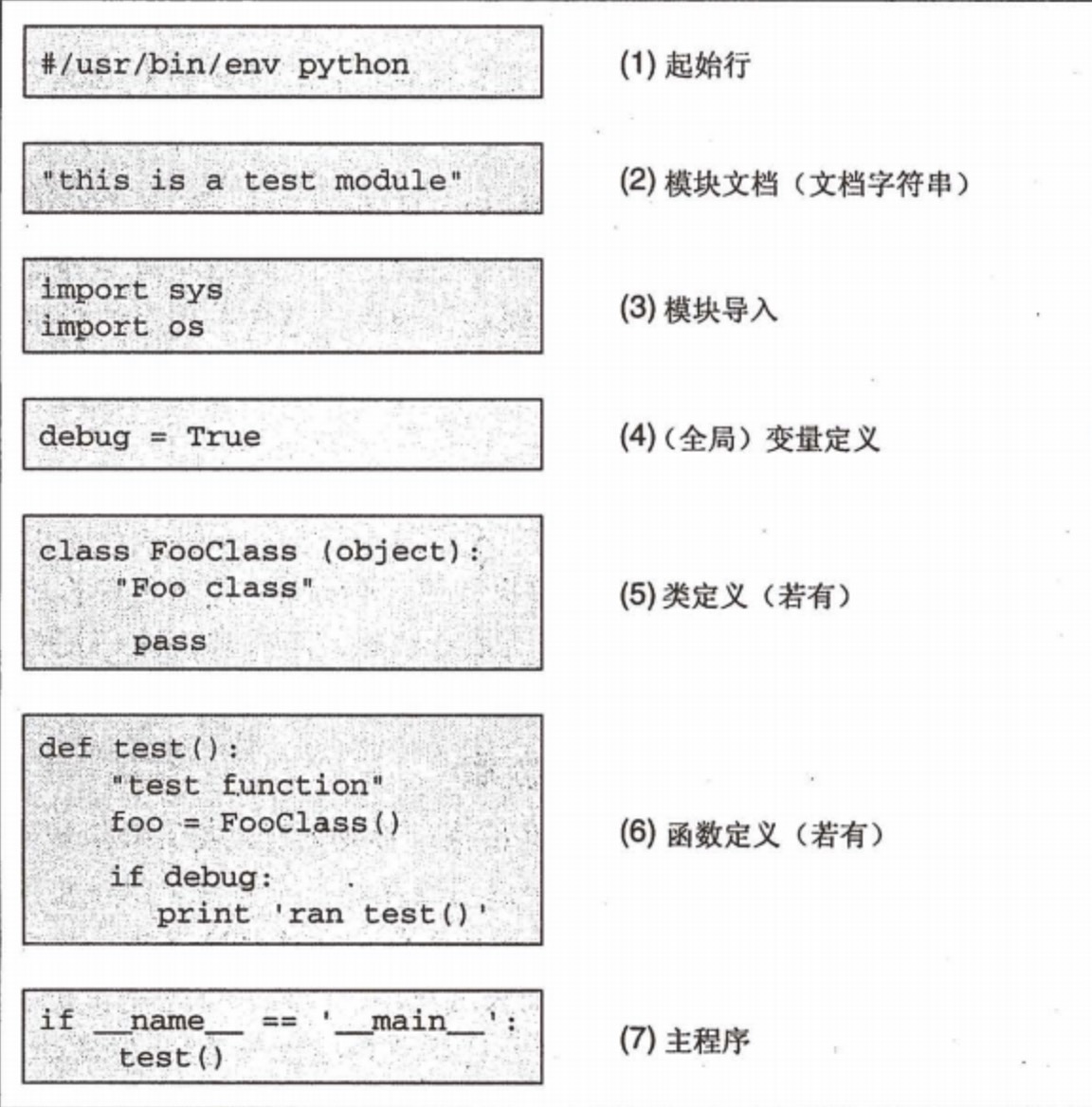
典型的python文件结构图:
六:内置函数:
python安装好之后会有很多内置函数模块已经配置好并且可以按需调用,

all:所有的值都不为false,则整个变量才True,可用于判断用户输入是否完整:
print(all([]),"#空的列表结果为True")
print(all(["a",""]),"有一个空值的列表结果为False")
print(all(["a",0]),"有一个值为0的列表结果为False")
print(all(()),"空元组结果为True")
print(all({}),"空的字典结果为True")
print(all([""]),"#列表有一个空的元素,结果为False")
print(all(["a","b",1,0]),"#要所有的元素都为真,结果才为True,而0等于假,所以结果为False")
print(all({"name":[]}),"value为空的字典也为True")
print(all({"name":0}),"value为0的字典也为True") 执行结果:
True #空的列表结果为True
False 有一个空值的列表结果为False
False 有一个值为0的列表结果为False
True 空元组结果为True
True 空的字典结果为True
False #列表有一个空的元素,结果为False
False #要所有的元素都为真,结果才为True,而0等于假,所以结果为False
True value为空的字典也为True
True value为0的字典也为True
abs() #返回一个数值的绝对值
1 >>> abs(-9)
2 9
any:与all函数作用相反,如果任何迭代的一个元素为ture,或者为空,则返回false
ascii: 转成ascii码
bin:转一个整数得到一个二进制的字符串
bool:转换一个值,得到一个bool类型
bytearray:返回一个字节数据
bytes: 根据一个编码转换成字节形式
callable: 回调函数,如果返回false,则代表回调失败,如果为true,它也仍然可能失败
chr:返回一个整形数字的Unicode形式,比如97返回a
classmethod:为函数返回一个类方法
compile:编译一个资源进入一个代码里或一个AST对象
complex:创建一个复数的表达式
delattr:移除一个对象的属性
dict:创建一个词典结构(类似Map)
dir:如果没有参数返回本文件的路径,如果有参数返回一个对象的属性列表
divmod:两个整形数字做相除
enumerate:可用于指定起始num的排序,如:
1 list1 = ["沙发","彩电","手机","Mac","汽车"]
2 for i in enumerate(list1,1):
3 print(i)
4
5 执行结果:
6 (1, '沙发')
7 (2, '彩电')
8 (3, '手机')
9 (4, 'Mac')
10 (5, '汽车')
eval:执行一个表达式,或字符串作为运算
exec:支持python代码的动态执行
filter:在一个元组里面过滤出目标字符串
float:字符串转成浮点类型
format:格式化字符串
frozenset:返回一个新的克隆对象
getattr:获取对象的一个方法的结果,类似于x.foobar
globals: 返回当前全局的字典表
hasattr:判断是否有某个属性值,返回true代表有
hash:取一个对象的hash值
help:调用系统内置的帮助系统
hex:转换一个整形数字,为小写的十六进制
id: 返回一个对象的唯一标识值
input:从控制台读取数据
int,转换字符串为int型
isinstance:判断一个对象是否为该类的一个实例
issubclass:判断一个类是否为另一个类的子类
iter: 返回一个可迭代的对象
len: 返回一个字符串的长度
list:打印一个集合对象
locals:更细并返回一个词典的本地标志表
map:返回一个可迭代的map函数
max:返回集合里面最大的一个或多个值
memoryview:返回一个python对象的内部数据
min:返回集合里面最小的一个或多个值
next:返回集合里面的下一项数值
object:返回一个新的对象,是所有的类的父类
oct:返回一个整形为八进制类型
open: 打开一个系统文件
ord:得到一个字符串或unicode类型的ascii数值
pow:返回的数字n次方值
print:打印输出语句
property:返回一个属性值
range:产生一个数字序列
repr:返回一个字符串可打印对象
reversed:反转一个集合
round:返回一个四舍五入的浮点数
set:返回一个新的set对象
setattr:设置一个新的属性值
slice:返回一个集合的区间集合
sorted:对一个集合进行排序
staticmethod:声明返回一个静态方法
str:将数字类型转换为字符串
sum:对一个集合里面的值求和
super:返回一个代理父类的对象
tuple:返回一个不可变的元组
type:返回一个对象的类型
vars:返回对象的属性
zip:返回组合一个对等的项
__import__: 比import高级的导入方法
quit,exit,copyright,license,credits
pathon 基础学习-集合(set),单双队列,深浅copy,内置函数的更多相关文章
- Python小白学习之路(十六)—【内置函数一】
将68个内置函数按照其功能分为了10类,分别是: 数学运算(7个) abs() divmod() max() min() pow() round() sum() 类型转换(24个) bo ...
- python学习笔记(七)- 递归、python内置函数、random模块
1.函数的不固定参数: #参数不是必填的.没有限制参数的个数.返回参数组的元组 def syz(*args): #参数组,不限制参数个数 #‘args’参数的名字可以随便命名 print(args) ...
- python学习笔记(五):装饰器、生成器、内置函数、json
一.装饰器 装饰器,这个器就是函数的意思,连起来,就是装饰函数,装饰器本身也是一个函数,它的作用是用来给其他函数添加新功能,比如说,我以前写了很多代码,系统已经上线了,但是性能比较不好,现在想把程序里 ...
- Python开发基础-Day10生成器表达式形式、面向过程编程、内置函数部分
生成器表达式形式 直接上代码 # yield的表达式形式 def foo(): print('starting') while True: x=yield #默认返回为空,实际上为x=yield No ...
- python基础之生成器表达式形式、面向过程编程、内置函数部分
生成器表达式形式 直接上代码 1 # yield的表达式形式 2 def foo(): 3 print('starting') 4 while True: 5 x=yield #默认返回为空,实际上为 ...
- Python小白学习之路(十八)—【内置函数三】
一.对象操作 help() 功能:返回目标对象的帮助信息 举例: print(help(input)) #执行结果 Help on built-in function input in module ...
- Hive学习之路 (九)Hive的内置函数
数学函数 Return Type Name (Signature) Description DOUBLE round(DOUBLE a) Returns the rounded BIGINT valu ...
- python基础-requests模块、异常处理、Django部署、内置函数、网络编程
网络编程 urllib的request模块可以非常方便地抓取URL内容,也就是发送一个GET请求到指定的页面,然后返回HTTP的响应. 校验返回值,进行接口测试: 编码:把一个Python对象编码转 ...
- python学习 day12 (3月18日)----(装饰器内置函数)
读时间函数: # import time # def func(): # start_time = time.time() # 代码运行之前的时间 # print('这是一个func函数') # ti ...
随机推荐
- [代码]--IIS发布网站浏览之后看到的是文件目录 & Internal Server Error 处理程序“ExtensionlessUrlHandler-ISAPI-4.0_64bit”在其模块列表中有一个错误模块“IsapiModule” 解决方法 & App_global.asax.pduxejp_.dll”--“拒绝访问。 ”
Q:IIS发布网站浏览之后看到的是文件目录 A:它出现了一个说到.NET4.0 更高框架什么的错误,所以我将 .NTE CRL版本由4.0改为2.0了,改为2.0后就出现了只能浏览文件目录了.改为4. ...
- 【题解】 [HNOI2015]菜肴制作 (拓扑排序)
题目描述 知名美食家小 A被邀请至ATM 大酒店,为其品评菜肴. ATM 酒店为小 A 准备了 N 道菜肴,酒店按照为菜肴预估的质量从高到低给予1到N的顺序编号,预估质量最高的菜肴编号为1. 由于菜肴 ...
- 【OpenCV】摄像机标定+畸变校正
摄像机标定 本文目的在于记录如何使用MATLAB做摄像机标定,并通过OpenCV进行校正后的显示. 首先关于校正的基本知识通过OpenCV官网的介绍即可简单了解: http://docs.open ...
- BZOJ5093 [Lydsy1711月赛]图的价值 【第二类斯特林数 + NTT】
题目链接 BZOJ5093 题解 点之间是没有区别的,所以我们可以计算出一个点的所有贡献,然后乘上\(n\) 一个点可能向剩余的\(n - 1\)个点连边,那么就有 \[ans = 2^{{n - 1 ...
- 洛谷 P2303 [SDOi2012]Longge的问题 解题报告
P2303 [SDOi2012]Longge的问题 题目背景 SDOi2012 题目描述 Longge的数学成绩非常好,并且他非常乐于挑战高难度的数学问题.现在问题来了:给定一个整数\(N\),你需要 ...
- 2019.3.16 noiac的原题模拟赛
RT,这太谔谔了,我不承认这是模拟赛 但是虽然是搬了三道题,题目本身也还能看,就这么着吧 (怎么机房里就我一道原题都没做过啊 T1 CF24D Broken Robot 比较简单地列出式子之后,我们发 ...
- CF679E Bear and Bad Powers of 42
一段时间不写线段树标记,有些生疏了 codeforces 679e Bear and Bad Powers of 42 - CHADLZX - 博客园 关键点是:42的次幂,在long long范围内 ...
- 洛谷P4211 LCA
题意:多次询问,每次求点的标号在[l, r]之间的所有点到点z的lca的深度. 解:看到这题有没有想到某一道很熟悉的题?紫妹和幽香是17岁的少女,喜欢可爱的东西...... 显然这就是开店的超级无敌弱 ...
- Python数据分析初始(一)
基础库 pandas:python的一个数据分析库(pip install pandas) pandas 是基于 NumPy 的一个 python 数据分析包,主要目的是为了 数据分析 .它提供了大量 ...
- Java基础-SSM之mybatis一对一外键关联
Java基础-SSM之mybatis一对一外键关联 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.准备测试环境(创建数据库表) 1>.创建husbandsfk和wife ...