在ubuntu server上搭建Hadoop
1. Java安装:
Because everything work with java.
$ sudo apt-get install openjdk-7-jdk
安装之后,可以查看java的版本信息:
wu@ubuntu:~$ java -version
java version "1.7.0_181"
OpenJDK Runtime Environment (IcedTea 2.6.14) (7u181-2.6.14-0ubuntu0.2)
OpenJDK 64-Bit Server VM (build 24.181-b01, mixed mode)
2. 创建Group
我们将会创建一个group,并配置这个group的权限,之后将user加到这个group之中。在下列程序中hadoop是group name,hduser是该group中的user。
将两个命令在ubuntu server的terminal里输入。
$ sudo addgroup hadoop
$ sudo adduser --ingroup hadoop hduser
3. 配置hduser的权限
打开visudo,配置hduser的权限:
$ sudo visudo
在nano编辑器里增加下面这句话,即给予hduser和root一样的权限
hduser ALL=(ALL) ALL
4. 创建hadoop目录并修改权限
$ sudo mkdir /usr/local/hadoop
$ sudo chown -R hduser /usr/local/hadoop
$ sudo chmod -R 755 /usr/local/hadoop
5. 切换用户(Switch User)
su hduser
6. 下载解压hadoop
这里采用镜像下载:
$ wget http://mirrors.hust.edu.cn/apache/hadoop/core/stable/hadoop-2.9.1.tar.gz
下载完之后解压:
$ tar xzf hadoop-2.9.1.tar.gz
将解压后的目录/hadoop-2.9.1中的所有内容移动到/usr/local/hadoop
mv hadoop-2.9.1/* /usr/local/hadoop
7. 配置环境变量
编辑$HOME/.bashrc 文件,添加java和hadoop路径
$ vim $HOME/.bashrc
在 .bashrc 中添加如下变量:
# Set Hadoop-related environment variables
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_OPTS="$HADOOP_OPTS -Djava.library.path=/usr/local/hadoop/lib/native"
# Set JAVA_HOME (we will also configure JAVA_HOME directly for Hadoop later on)
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
重新加载 .bashrc 文件
$ source $HOME/.bashrc
8. 生成ssh
生成一个新的ssh public/private key pair在你的本机上,我们需要本机访问ubuntu server无需密码。这一步具体操作可见:Mac OS利用ssh访问ubuntu虚拟机及云端操作的第5节内容。
9. 添加localhost
$ ssh localhost
10. 配置文件
1.将当前目录移动到/usr/local/hadoop/etc/hadoop
$ cd $HADOOP_HOME/etc/hadoop
配置hadoop-env.sh文件,将以下内容添加到文件中。
# remove comment and change java_HOME
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
2.配置core-site.xml文件,该文件用于定义系统级别的参数,如HDFS,URL,Hadoop的临时目录等。所以,添加以下内容到configure中:
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
<description>The name of the default file system. A URI whose
scheme and authority determine the FileSystem implementation. The
uri's scheme determines the config property (fs.SCHEME.impl) naming
the FileSystem implementation class. The uri's authority is used to
determine the host, port, etc. for a filesystem.</description>
</property>
3.配置hdfs-site.xml文件,该文件主要有hdfs参数,如名称节点和数据节点的存放位置,文件副本的个数,文件读取权限等。所以,添加以下内容到configure中:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/app/hadoop/tmp/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/app/hadoop/tmp/datanode</value>
</property>
4.配置yarn-site.xml文件,该文件主要包含集群资源管理系统参数,如配置ResourceManager, NodeManger的通信端口,web监控端口等。所以,添加以下内容到configure中:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
5.复制文件mapred-site.xml.template,并粘贴为 mapred-site.xml。
$ cp mapred-site.xml.template mapred-site.xml
配置mapred-site.xml文件,它里面主要是Mapreduce参数,包含JobHistory Server和应用程序两部分,如reduce任务的默认个数、任务所能够使用内存的默认上限等。所以,将以下内容加入到文件中:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
6.编辑slaves文件,添加如下一句话到文件中:
localhost
11. 添加/app/hadoop/tmp目录,并改变权限:
$ sudo mkdir /app/hadoop/tmp
$ sudo chown -R hduser /app/hadoop/tmp
$ sudo chmod -R 755 /app/hadoop/tmp
12. 格式化
我们现在完成所有的配置,所以在启动集群之前,我们需要格式化namenode。
将工作目录移动到/usr/local/hadoop/sbin,并进行格式化:
$ cd /usr/local/hadoop/sbin
$ hadoop namenode -format
13. 启动
是时候启动hadoop了,有两种方式:
- 分别启动dfs和yarn:
$ start-dfs.sh
$ start-yarn.sh
- 一键全部启动:
$ start-all.sh
14. JPS
一旦dfs启动没有任何错误,我们可以使用命令JPS(java virtual machine process status tool)检查一切是否正常工作,我们应该看到至少一个Namenode和Datanode
$ jps

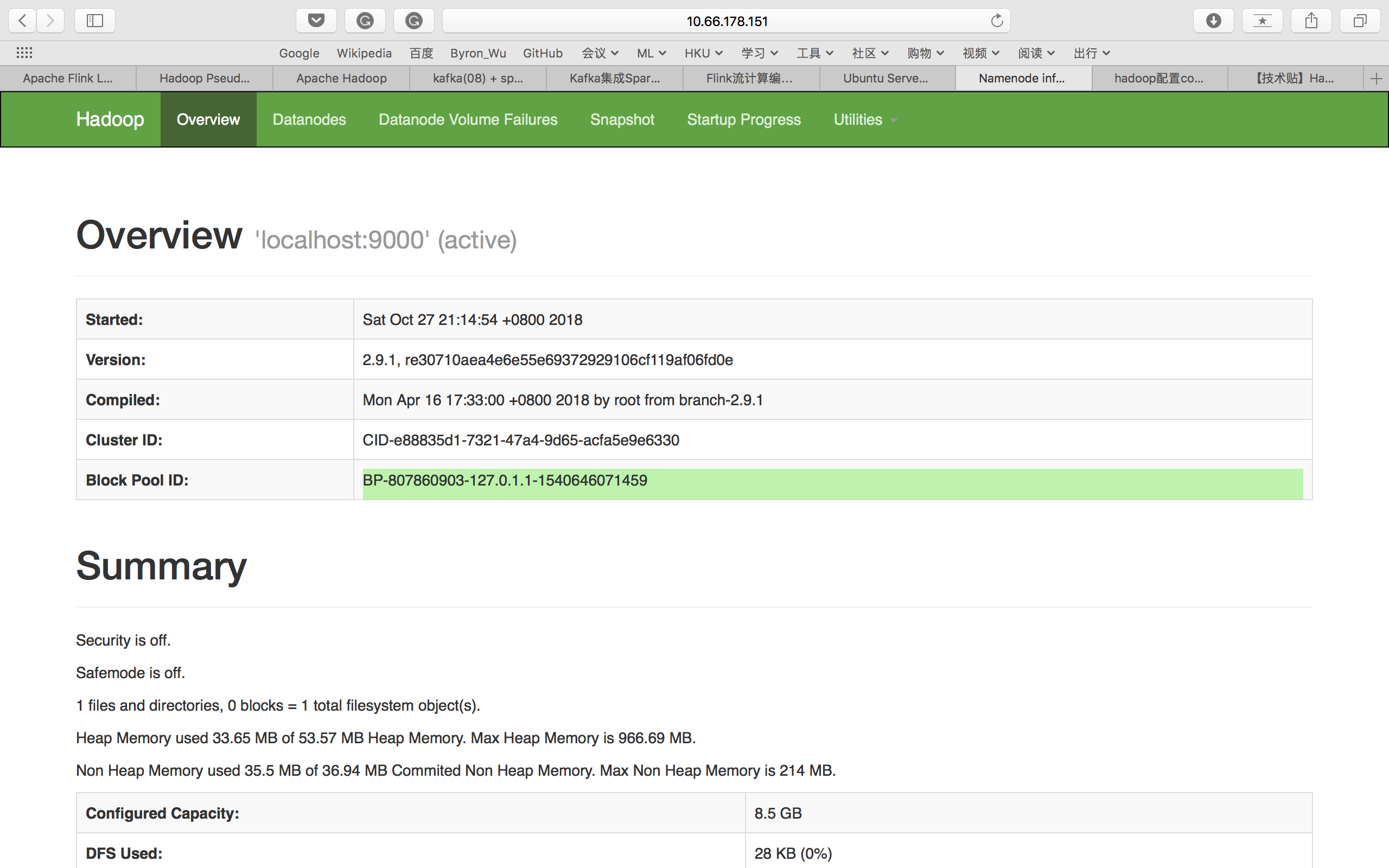
15. 网页查看
由于我们是在ubuntu server中配置的,没有ui界面,所以我们只能通过主机来访问。用http://your IP address:50070上的Namenode的Web界面检查Apache Hadoop的状态。
16.关闭
$ stop-all.sh
Reference:
- http://hadoop.praveendeshmane.co.in/hadoop/hadoop-2-6-4-pseudo-distributed-mode-installation-on-ubuntu-14-04.jsp
- https://zhuanlan.zhihu.com/p/25472769
- https://blog.csdn.net/boonya/article/details/55194170
- 《鸟哥的Linux私房菜》
在ubuntu server上搭建Hadoop的更多相关文章
- 在Ubuntu系统上搭建Hadoop 2.x(2.6.2)
官方的中文版的Hadoop快速入门教程已经是很老的版本了,新版的Hadoop目录结构发生了变化,因此一些配置文件的位置也略微调整了,例如新版的hadoop中找不到快速入门中提到的conf目录,另外,网 ...
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式) (转载)
Hadoop在处理海量数据分析方面具有独天优势.今天花了在自己的Linux上搭建了伪分布模式,期间经历很多曲折,现在将经验总结如下. 首先,了解Hadoop的三种安装模式: 1. 单机模式. 单机模式 ...
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式)
首先要了解一下Hadoop的运行模式: 单机模式(standalone) 单机模式是Hadoop的默认模式.当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守地选 ...
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式)【转】
[转自:]http://blog.csdn.net/hitwengqi/article/details/8008203 最近一直在自学Hadoop,今天花点时间搭建一个开发环境,并整理成文. 首先要了 ...
- Ubuntu server下搭建Maven私服Nexus
Ubuntu server下搭建Maven私服Nexus Maven私服Nexus的作用,主要是为了节省资源,在内部作为maven开发资源共享服务器来使用. 1.下载 通过root用户进去Ubuntu ...
- Ubuntu Server 上使用Docker Compose 部署Nexus(图文教程)
场景 Docker-Compose简介与Ubuntu Server 上安装Compose: https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/deta ...
- 一台Ubuntu server上安装多实例MySQL
受环境所迫,在一台Ubuntu server上安装多个实例MySQL. 手动安装MySQL 环境:Ubuntu server 11.10 64bit + mysql-5.5.17-linux2.6-x ...
- Docker-Compose简介与Ubuntu Server 上安装Compose
Compose简介 Compose是Docker官方的开源项目,负责对Docker容器集群的快速编排. Compose是定义和运行多个Docker容器的应用. 举例来说: 一个项目除了Tomcat容器 ...
- 如何在一个ubuntu系统上搭建SVN版本控制工具
有话说,由于公司项目部署需要,将Windows工程迁移到Linux,通过调查确定使用Ubuntu的Linux操作系统.那么如何快速搭建和Windows一样快捷方便的开发环境就很重要了.本文讲述如何在一 ...
随机推荐
- Photoshop CS4破解方法
先在网上下载Photoshop CS4的版本,安装后按如下步骤操作即可. 激活码: 1330-1082-3503-2270-3738-6738 1330-1776-8671-6289-7706-291 ...
- Mysql + Mybatis动态建表
service层业务 package com.zx.common.service.impl; import com.zx.common.entity.SysUser; import com.zx.co ...
- effective c++ 笔记 (45-48)
//#45 运用成员函数模版接受所有兼容类型 { /* 1:当你使用智能指针的时候,会发生一个问题,想把一个子类的对象赋给基类的指针变得不可能了, 因为智能指针指定了的是基类的类型,而赋给它的是 ...
- node.js学习笔记(四)——EventEmitter
error 事件 EventEmitter 定义了一个特殊的事件 error,它包含了错误的语义,我们在遇到异常的时候通常会触发 error 事件.当 error 被触发时,EventEmitter ...
- 初识kibana
前言: 什么是Kibana?? Kibana是一个开源的分析与可视化平台,设计出来用于和Elasticsearch一起使用的.你可以用kibana搜索.查看.交互存放在Elasticsearch索引里 ...
- Mac下搭建lamp
Mac下搭建lamp Mac 自带了Apache,并默认支持PHP环境,只需要配置Apache和PHP即可使用.需要单独安装mysql服务端. Apache 基础配置 Apache支持PHP配置 Ap ...
- Python中的字典详解
https://www.cnblogs.com/yjd_hycf_space/p/6880026.html
- 5月29,48h,Geekathon,创业极客的梦想起点
http://mp.weixin.qq.com/s?__biz=MjM5ODQ3MDIwMg==&mid=213768178&idx=1&sn=0a607fac483f3eab ...
- (Alpha)Let's-展示博客
Let's Alpha 项目答辩 ·选题由来 手机端——用户相对较多,使用环境限制相对宽松 手机游戏?校园p2p应用?线下交流!(滴滴打水?) 模式的选择:发起——加入活动 ...
- Daily Scrum 11.1
今天放假一天,明天又是新的一周,预计开始Alpha版本所有功能的整合和优化,争取在两天内完成各种功能的整合. Member Task on 11.1 Task on 11.2 仇栋民 放假一天 开始T ...