Kafka与Logstash的数据采集对接
Logstash工作原理
由于Kafka采用解耦的设计思想,并非原始的发布订阅,生产者负责产生消息,直接推送给消费者。而是在中间加入持久化层——broker,生产者把数据存放在broker中,消费者从broker中取数据。这样就带来了几个好处::
1 生产者的负载与消费者的负载解耦
2 消费者按照自己的能力fetch数据
3 消费者可以自定义消费的数量
由于broker采用了主题topic–>分区的思想,使得某个分区内部的顺序可以保证有序性,但是分区间的数据不保证有序性。这样,消费者可以以分区为单位,自定义读取的位置——offset。
Kafka采用zookeeper作为管理,记录了producer到broker的信息,以及consumer与broker中partition的对应关系。因此,生产者可以直接把数据传递给broker,broker通过zookeeper进行leader–>followers的选举管理;消费者通过zookeeper保存读取的位置offset以及读取的topic的partition分区信息。
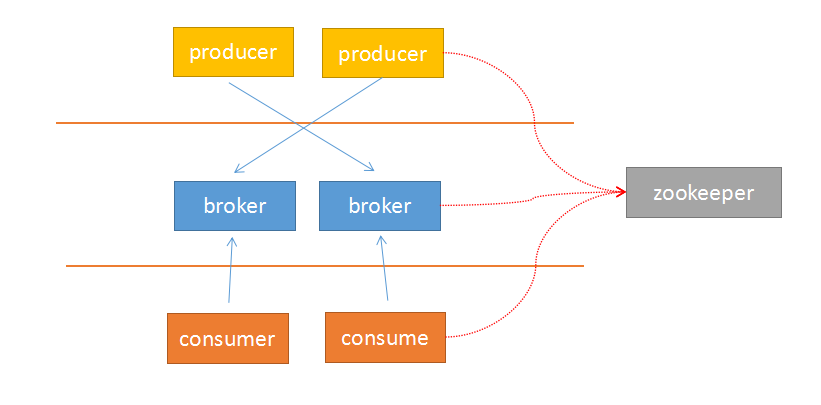
由于上面的架构设计,使得生产者与broker相连;消费者与zookeeper相连。有了这样的对应关系,就容易部署logstash–>kafka–>logstash的方案了。
接下来,按照下面的步骤就可以实现logstash与kafka的对接了。

启动zookeeper
$zookeeper/bin/zkServer.sh start
启动kafka
$kafka/bin/kafka-server-start.sh $kafka/config/server.properties &
创建主题
$kafka/bin/kafka-topics.sh --zookeeper 127.0.0.1:2181 --create --topic hello --replication-factor 1 --partitions 1
查看主题
$kafka/bin/kafka-topics.sh --zookeeper 127.0.0.1:2181 --describe
测试环境
执行生存者脚本
$kafka/bin/kafka-console-producer.sh --broker-list 10.0.67.101:9092 --topic hello
执行消费者脚本
$kafka/bin/kafka-console-consumer.sh --zookeeper 127.0.0.1:2181 --from-beginning --topic hello
测试输入
input{stdin{}}output{kafka{topic_id => "hello"bootstrap_servers => "192.168.0.4:9092" # kafka的地址batch_size => 5}stdout{codec => rubydebug}}
读取测试
input{kafka {codec => "plain"group_id => "logstash1"auto_offset_reset => "smallest"reset_beginning => truetopic_id => "hello"#white_list => ["hello"]#black_list => nilzk_connect => "192.168.0.5:2181" # zookeeper的地址}}output{stdout{codec => rubydebug}}
Kafka与Logstash的数据采集对接的更多相关文章
- Kafka与Logstash的数据采集对接 —— 看图说话,从运行机制到部署
基于Logstash跑通Kafka还是需要注意很多东西,最重要的就是理解Kafka的原理. Logstash工作原理 由于Kafka采用解耦的设计思想,并非原始的发布订阅,生产者负责产生消息,直接推送 ...
- Kafka与Logstash的数据采集
Kafka与Logstash的数据采集 基于Logstash跑通Kafka还是需要注意很多东西,最重要的就是理解Kafka的原理. Logstash工作原理 由于Kafka采用解耦的设计思想,并非原始 ...
- kafka(logstash) + elasticsearch 构建日志分析处理系统
第一版:logstash + es 第二版:kafka 替换 logstash的方案
- Kafka、Logstash、Nginx日志收集入门
Nginx作为网站的第一入口,其日志记录了除用户相关的信息之外,还记录了整个网站系统的性能,对其进行性能排查是优化网站性能的一大关键. Logstash是一个接收,处理,转发日志的工具.支持系统日志, ...
- 海量日志分析方案--logstash+kibnana+kafka
下图为唯品会在qcon上面公开的日志处理平台架构图.听后觉得有些意思,好像也可以很容易的copy一个,就动手尝试了一下. 目前只对flume===>kafka===>elacsticSea ...
- ELK架构下利用Kafka Group实现Logstash的高可用
系统运维的过程中,每一个细节都值得我们关注 下图为我们的基本日志处理架构 所有日志由Rsyslog或者Filebeat收集,然后传输给Kafka,Logstash作为Consumer消费Kafka里边 ...
- 【ELK】【docker】【elasticsearch】2.使用elasticSearch+kibana+logstash+ik分词器+pinyin分词器+繁简体转化分词器 6.5.4 启动 ELK+logstash概念描述
官网地址:https://www.elastic.co/guide/en/elasticsearch/reference/current/docker.html#docker-cli-run-prod ...
- ELK + kafka 日志方案
概述 本文介绍使用ELK(elasticsearch.logstash.kibana) + kafka来搭建一个日志系统.主要演示使用spring aop进行日志收集,然后通过kafka将日志发送给l ...
- ELK + kafka 分布式日志解决方案
概述 本文介绍使用ELK(elasticsearch.logstash.kibana) + kafka来搭建一个日志系统.主要演示使用spring aop进行日志收集,然后通过kafka将日志发送给l ...
随机推荐
- input全选与单选(把相应的value放入隐藏域去)
框架是Jquery 需求是: 页面上有很多复选框,1.当我选择一项复选框时候 把对应的值放入到隐藏域去 2.当我反选的时候 把隐藏域对应的值删掉.3.当我全选的时候 页面上所有的选择框的值一起放到隐藏 ...
- day29
今日内容: 异常处理 元类介绍 元类(通过元类中的__init__方法,改变实例化获得的类) 元类(通过元类中的__call__方法,改变实例化获得的类实例化出来的对象) 1.异常处理: 什么是异常处 ...
- 从零开始学cookie(个人笔记)——一
未完待续 参考链接 : cookie (储存在用户本地终端上的数据) 关键词: cookie session HTTP 小文本文件 解释 Cookie 是由 Web 服务器保存在用户浏览器上的小文本文 ...
- 五、MYSQL的索引
对于建立的索引(姓,名字,data) 5.1.索引对一下的查询类型有效 1.全值匹配:能查找姓+名为ALLEN.出生日期为1990-11-05的人: 2.最左前缀匹配:可以查找姓为ALLEN的人:即只 ...
- [Oracle][Corruption]究竟哪些检查影响到 V$DATABASE_BLOCK_CORRUPTION
根据 471716.1,11g 之后,下列动作如果遇到坏块,都会输出记录到 V$DATABASE_BLOCK_CORRUPTION. - Analyze table .. Validate str ...
- 阿里云Redis外网转发访问
1.前提条件 如果您需要从本地 PC 端访问 Redis 实例进行数据操作,可以通过在 ECS 上配置端口映射或者端口转发实现.但必须符合以下前提条件: 若 Redis 实例属于专有网络(VPC),E ...
- ECC检验与纠错
引入ECC ECC:Error Checking and Correction,是一种差错检测和修正的算法. NAND闪存在生产和使用中都会有坏块产生,BBM就是坏块的管理机制.而生产坏块已经无法避免 ...
- ESLint 规则详解(二)
接上篇 ESLint 规则详解(一) 前端界大神 Nicholas C. Zakas 在 2013 年开发的 ESLint,极大地方便了大家对 Javascript 代码进行代码规范检查.这个工具包含 ...
- allegro对齐操作
在placement edit模式下 选中元件,右键对齐即可.
- Linux下的信号详解
文章链接:https://blog.csdn.net/qq_38646470/article/details/80257512