mycat 分库分表
单库分表已经在上篇写过了,这次写个分库分表,不同在于配置文件上的一点点不同
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="app_house" checkSQLschema="false" sqlMaxLimit="100"> <table name="t_order" primaryKey="id" autoIncrement="true" dataNode="dn1,dn2" rule="mod-long" />
</schema>
<dataNode name="dn1" dataHost="mycluster" database="testdb2" />
<dataNode name="dn2" dataHost="mycluster" database="testdb3" />
<dataHost name="mycluster" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="86_M" url="172.17.3.86:3306" user="root" password="123456">
<!-- can have multi read hosts -->
<readHost host="177_S" url="172.17.3.177:3306" user="root" password="123456" />
</writeHost>
<!-- <writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/> -->
</dataHost>
</mycat:schema>
tabe标签里的dataNode改为2个了分表为dn1 dn2,表示分为2个片,规则为均分mod-long
下面定义两个dateNode,两个dateNode不同在于,数据库都在同一台物理机上,只是数据库名字不同而已,分库分表顾名思义就是把一张表存储在不同库里,但是表明还是相同的
另外注意rule.xml文件,修改count数量为2才可以启动
看下测试效果
首先需要在物理机上的testdb2和testdb3数据库里分别建立t_order表
CREATE TABLE `t_order` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
`t_user_id` int(11) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8;
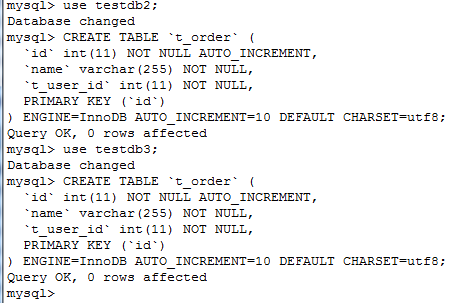
已经建立好了
现在连接到Mycat机器在t_order表插入几条数据试试

依然记住选择逻辑库
然后去查看物理机数据库testdb2和testdb3里的t_order表
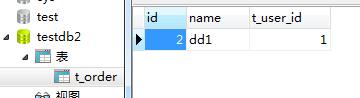
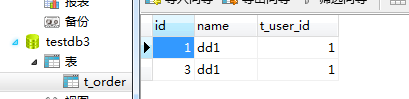
可以看到成功实现了分库分表操作
mycat 分库分表的更多相关文章
- MySQL+MyCat分库分表 读写分离配置
一. MySQL+MyCat分库分表 1 MyCat简介 java编写的数据库中间件 Mycat运行环境需要JDK. Mycat是中间件.运行在代码应用和MySQL数据库之间的应用. 前身 : cor ...
- 《MyCat分库分表策略详解》
在我们的项目发展到一定阶段之后,随着数据量的增大,分库分表就变成了一件非常自然的事情.常见的分库分表方式有两种:客户端模式和服务器模式,这两种的典型代表有sharding-jdbc和MyCat.所谓的 ...
- MyCat | 分库分表实践
引言 先给大家介绍2个概念:数据的切分(Sharding)根据其切分规则的类型,可以分为两种切分模式. 切分模式 一种是按照不同的表(或者Schema)来切分到不同的数据库(主机)之上,这种切可以称之 ...
- MyCat分库分表入门
1.分区 对业务透明,分区只不过把存放数据的文件分成了许多小块,例如mysql中的一张表对应三个文件.MYD,MYI,frm. 根据一定的规则把数据文件(MYD)和索引文件(MYI)进行了分割,分区后 ...
- 3.Mysql集群------Mycat分库分表
前言: 分库分表,在本节里是水平切分,就是多个数据库里包含的表是一模一样的. 只是把字段散列的分到不同的库中. 实践: 1.修改schema.xml 这里是在同一台服务器上建立了4个数据库db1,db ...
- 分布式数据库中间件 MyCat | 分库分表实践
MyCat 简介 MyCat 是一个功能强大的分布式数据库中间件,是一个实现了 MySQL 协议的 Server,前端人员可以把它看做是一个数据库代理中间件,用 MySQL 客户端工具和命令行访问:而 ...
- Mycat分库分表(一)
随着业务变得越来越复杂,用户越来越多,集中式的架构性能会出现巨大的问题,比如系统会越来越慢,而且时不时会宕机,所以必须要解决高性能和可用性的问题.这个时候数据库的优化就显得尤为重要,在说优化方案前,先 ...
- mycat分库分表 看这一篇就够了
之前我们已经讲解过了数据的切分,主要有两种方式,分别是垂直切分和水平切分,所谓的垂直切分就是将不同的表分布在不同的数据库实例中,而水平切分指的是将一张表的数据按照不同的切分规则切分在不同实例的相同 ...
- MYCAT分库分表
一.整体架构 1.192.168.189.130:mysql master服务,两个数据库db_store.db_user,db_store做了主从复制 db_user: 用户表users为分片表 数 ...
随机推荐
- MySQL 之mydumper安装详解
方法一: 安装依赖包: 1 yum install glib2-devel mysql-devel zlib-devel pcre-devel openssl-devel cmake make 下载二 ...
- 逻辑运算符&逻辑短路
(1)and 逻辑与 全真则真,一假则假 print(True and True) #True print(False and True) #False print(False and False) ...
- video兼容--可用
兼容ie6,7,8,但是播放器会卡顿黑屏<!DOCTYPE html> <html lang="en"> <head> <meta cha ...
- Linux常用指令之二
1.用户权限 1).查看文件属性 ls -l file(ll别名) drwxr-x--- 2 root root 4096 Jan 20 19:39 mnt # ...
- boost json序列化
json序列化 #ifndef FND_JSON_OBJECT_H #define FND_JSON_OBJECT_H #include <sstream> #include <bo ...
- Javascript异步编程的4种方法(阮一峰)
转载: http://www.ruanyifeng.com/blog/2012/12/asynchronous%EF%BC%BFjavascript.html 你可能知道,Javascript语言的执 ...
- MySQL高可用架构之基于MHA的搭建
一.MySQL MHA架构介绍: MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于Fa ...
- Linux netstat命令查看并发连接数
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}' 解释: 返回结果示例: LAST_ACK 5 (正在等待处理的 ...
- IE 主页被恶意篡改的解决方法
IE 主页被篡改了,在ie 的 主页设置中不起任何作用,这个时候,就要打开注册表来修改: 具体操作如下: 1.运行 regedit 打开注册表 2.找到 HKEY_LOCAL_MACHINE\SOF ...
- jmater分布式压力测试总结
总结,总是为了方便以后 1.jmeter 2000个并发,4台slave ,每台slave是500个线程即可完成测试 2.jmx文件只需要拷贝到master下 jmeter目录下(最保险的方法) 3. ...