认识Hadoop
概述
开源、分布式存储、分布式计算
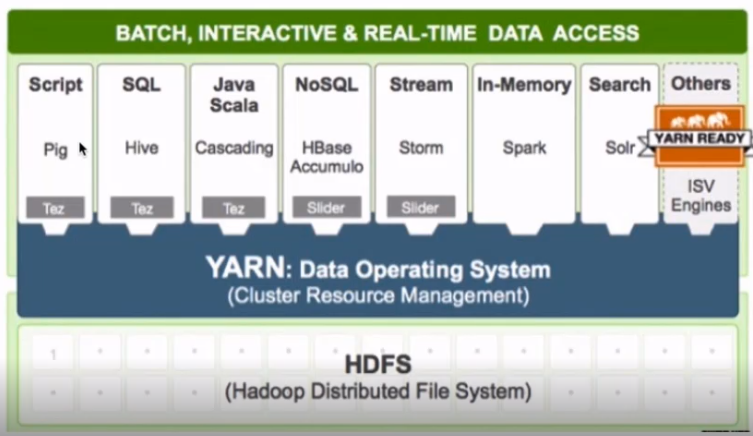
大数据生态体系
- 特点:开源、社区活跃
- 囊括了大数据处理的方方面面
- 成熟的生态圈
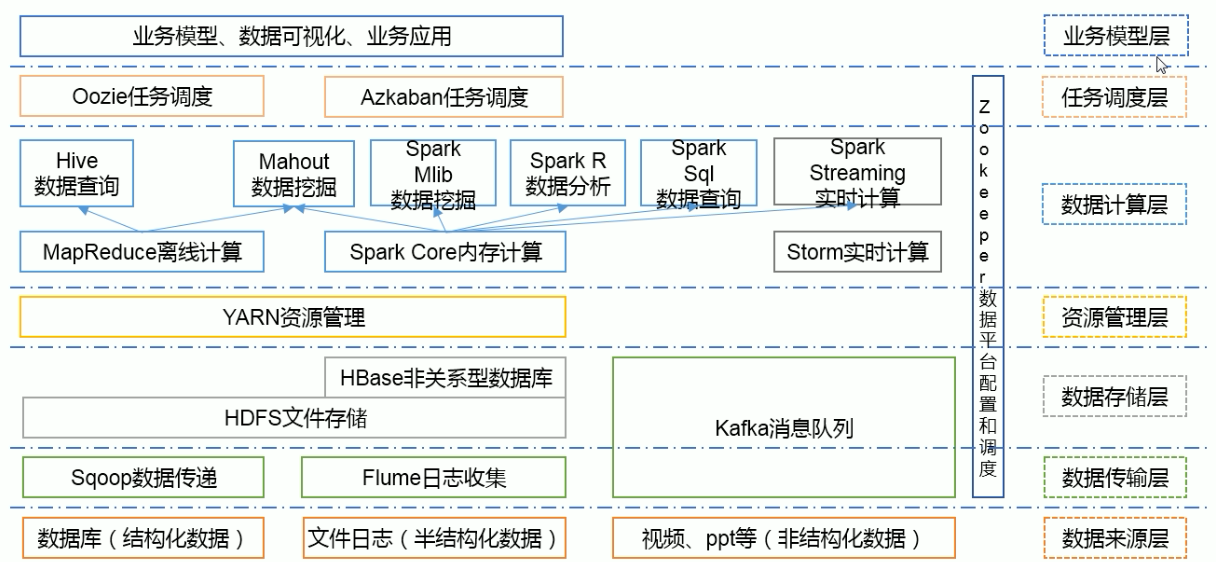
推荐系统
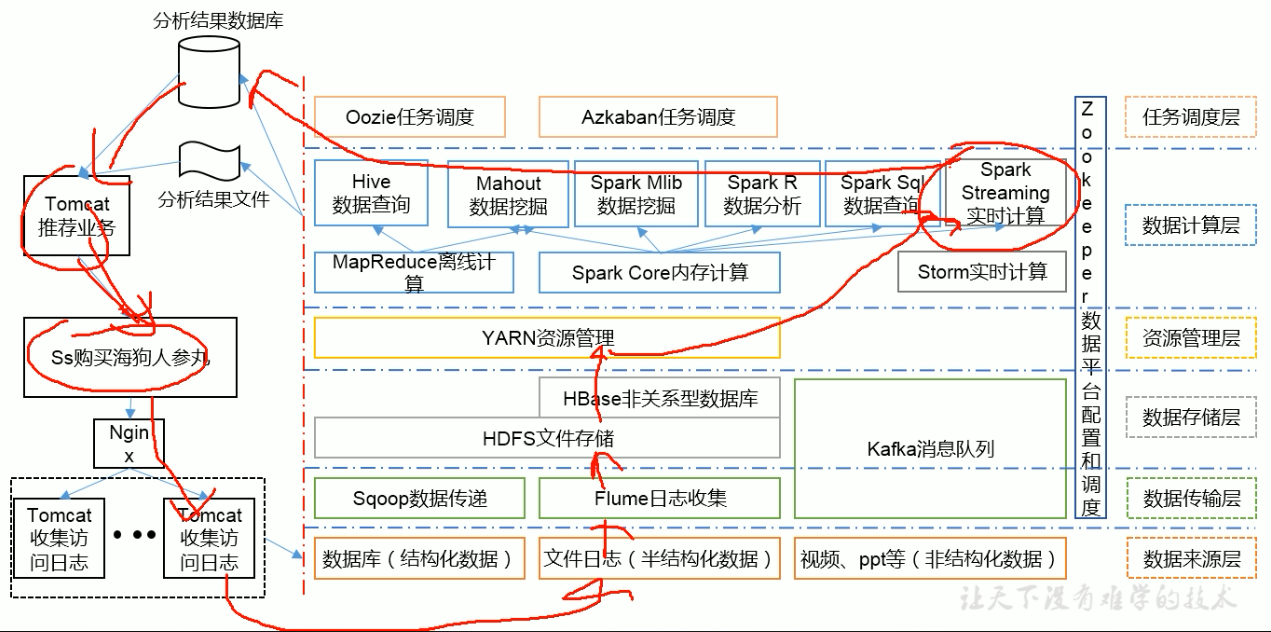
应用场景
- 搭建大型数据仓库,PB级数据的存储、处理、分析、统计
- 日志分析
- 数据挖掘
核心组件
HDFS(分布式文件存储系统)
- 特点:扩展性、容错性、海量数据存储
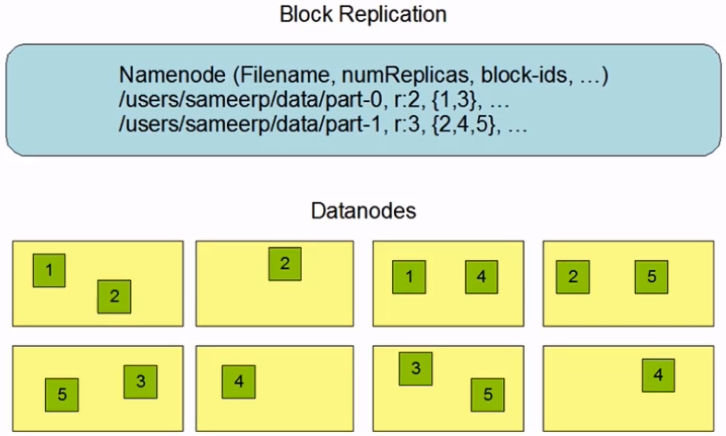
- 将文件切分成指定大小(默认128M)的数据块并以多副本(默认3副本)的存储在多个机器上
- 数据切分、多副本、容错等操作对用户是透明的
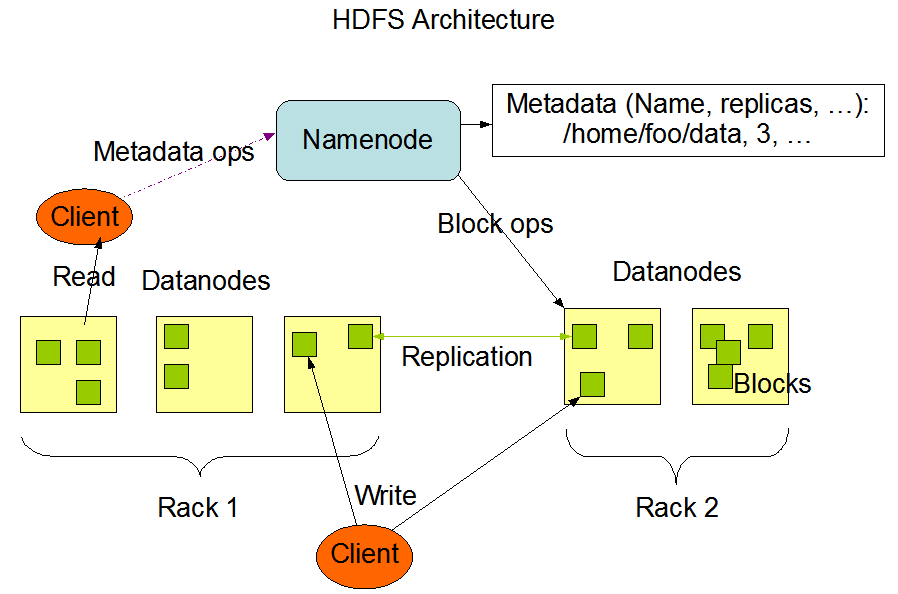
架构
- 1个master(NameNode/NN)带n个slave(datanode/DN)
- 1个文件会被拆分成多个Block(blocksize=128M)
- NN:
- 负责客户端请求响应
- 负责元数据(文件名称、副本系数、block存放的DN)管理
- DN:
- 存储用户的文件对应的数据块(block)
- 定期向NN发送心跳信息,汇报本身及所有的block信息,健康状况
hdfs副本策略
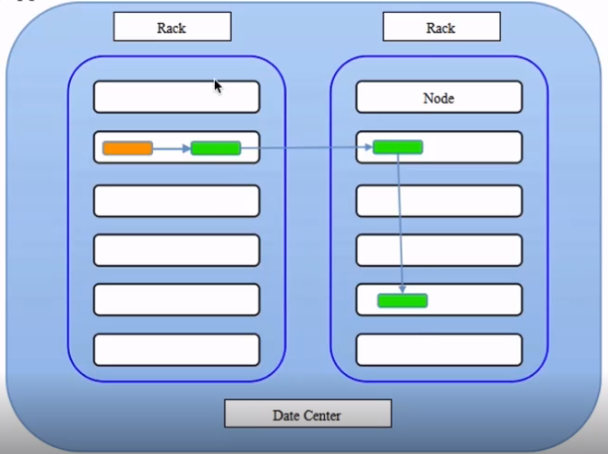
Yarn(资源调度系统)
- 特点:扩展性、容错性(任务失败重试)、多框架资源统一调度 (比如spark、hivesql、hbase、storm)
- yarn:Yet another resource negotiator
- 负责整个集群资源的管理和调度
MapReduce(分布式计算框架)
- 特点:扩展性、容错性、海量离线数据处理

Hadoop的优势
高可靠性
- 数据存储:数据块多副本
- 数据计算:重新调度作业计算
扩展性
- 存储/计算资源不够时,可以横向的线性扩展机器
- 一个集群可以包含数以千计的节点
其他
- 存储在廉价机器上,降低成本
- 成熟的生态圈
Hadoop常用发行版及选型
- Apache Hadoop(解决了单个框架的问题,联合使用时很多包冲突)
- CDH:Cloudera Distributed Hadoop(60~70%)
- HDP:Hortonworks Data PlatForm
认识Hadoop的更多相关文章
- Hadoop 中利用 mapreduce 读写 mysql 数据
Hadoop 中利用 mapreduce 读写 mysql 数据 有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如一些 pv.uv 数据,然后为了实时查询的需求,或者一些 OLAP ...
- 初识Hadoop、Hive
2016.10.13 20:28 很久没有写随笔了,自打小宝出生后就没有写过新的文章.数次来到博客园,想开始新的学习历程,总是被各种琐事中断.一方面确实是最近的项目工作比较忙,各个集群频繁地上线加多版 ...
- hadoop 2.7.3本地环境运行官方wordcount-基于HDFS
接上篇<hadoop 2.7.3本地环境运行官方wordcount>.继续在本地模式下测试,本次使用hdfs. 2 本地模式使用fs计数wodcount 上面是直接使用的是linux的文件 ...
- hadoop 2.7.3本地环境运行官方wordcount
hadoop 2.7.3本地环境运行官方wordcount 基本环境: 系统:win7 虚机环境:virtualBox 虚机:centos 7 hadoop版本:2.7.3 本次先以独立模式(本地模式 ...
- 【Big Data】HADOOP集群的配置(一)
Hadoop集群的配置(一) 摘要: hadoop集群配置系列文档,是笔者在实验室真机环境实验后整理而得.以便随后工作所需,做以知识整理,另则与博客园朋友分享实验成果,因为笔者在学习初期,也遇到不少问 ...
- Hadoop学习之旅二:HDFS
本文基于Hadoop1.X 概述 分布式文件系统主要用来解决如下几个问题: 读写大文件 加速运算 对于某些体积巨大的文件,比如其大小超过了计算机文件系统所能存放的最大限制或者是其大小甚至超过了计算机整 ...
- 程序员必须要知道的Hadoop的一些事实
程序员必须要知道的Hadoop的一些事实.现如今,Apache Hadoop已经无人不知无人不晓.当年雅虎搜索工程师Doug Cutting开发出这个用以创建分布式计算机环境的开源软...... 1: ...
- Hadoop 2.x 生态系统及技术架构图
一.负责收集数据的工具:Sqoop(关系型数据导入Hadoop)Flume(日志数据导入Hadoop,支持数据源广泛)Kafka(支持数据源有限,但吞吐大) 二.负责存储数据的工具:HBaseMong ...
- Hadoop的安装与设置(1)
在Ubuntu下安装与设置Hadoop的主要过程. 1. 创建Hadoop用户 创建一个用户,用户名为hadoop,在home下创建该用户的主目录,就不详细介绍了. 2. 安装Java环境 下载Lin ...
- 基于Ubuntu Hadoop的群集搭建Hive
Hive是Hadoop生态中的一个重要组成部分,主要用于数据仓库.前面的文章中我们已经搭建好了Hadoop的群集,下面我们在这个群集上再搭建Hive的群集. 1.安装MySQL 1.1安装MySQL ...
随机推荐
- PAT 1087 有多少不同的值(20)(STL-set代码)
1087 有多少不同的值(20 分) 当自然数 n 依次取 1.2.3.--.N 时,算式 ⌊n/2⌋+⌊n/3⌋+⌊n/5⌋ 有多少个不同的值?(注:⌊x⌋ 为取整函数,表示不超过 x 的最大自然数 ...
- 安装php_sqlsrv扩展
https://www.cnblogs.com/wtcl/p/7727636.html
- js、css、img等浏览器缓存问题的2种解决方案
转:http://www.jb51.net/article/42339.htm 浏览器缓存的意义在于提高了执行效率,但是也随之而来带来了一些问题,导致服务端修改了js.css,客户端不能更新,下面有几 ...
- openssl 连接 https(nginx)
参考源码路径 demos\ssl #include <stdio.h> #include <string.h> #include <stdlib.h> #incl ...
- [IBM][CLI Driver][DB2/NT] SQL1101N 不能以指定的授权标识和密码访问节点 "" 上的远程数据库 "LBZM"。 SQLSTATE=08004
[IBM][CLI Driver][DB2/NT] SQL1101N 不能以指定的授权标识和密码访问节点 "" 上的远程数据库 "LBZM". SQLST ...
- How to Create Triggers in MySQL
https://www.sitepoint.com/how-to-create-mysql-triggers/ I created two tables: CREATE TABLE `sw_user` ...
- jQuery学习笔记:基础
本文主要总结jQuery中一些知识点 概念 美元符号$是著名的jQuery符号.jQuery把所有功能全部封装在一个全局变量jQuery中,而$也是一个合法的变量名,它是变量jQuery的别名 $本质 ...
- 【转】你知道C#中的Lambda表达式的演化过程吗?
[转]你知道C#中的Lambda表达式的演化过程吗? 那得从很久很久以前说起了,记得那个时候... 懵懂的记得从前有个叫委托的东西是那么的高深难懂. 委托的使用 例一: 什么是委托? 个人理解:用来传 ...
- python学习 day1 (3月1日)
01 cpu 内存 硬盘 操作系统 CPU:中央处理器,相当于人大脑. 飞机 内存:临时存储数据. 8g,16g, 高铁 1,成本高. 2,断电即消失. 硬盘:长期存储大量的数据. 1T 512G等等 ...
- 【转】linux 磁盘挂载
挂载好新硬盘后输入fdisk -l命令看当前磁盘信息 可以看到除了当前的第一块硬盘外还有一块sdb的第二块硬盘,然后用fdisk /dev/sdb 进行分区 进入fdisk命令,输入h可以看到该命令的 ...