认识Hadoop
概述
开源、分布式存储、分布式计算
大数据生态体系
- 特点:开源、社区活跃
- 囊括了大数据处理的方方面面
- 成熟的生态圈
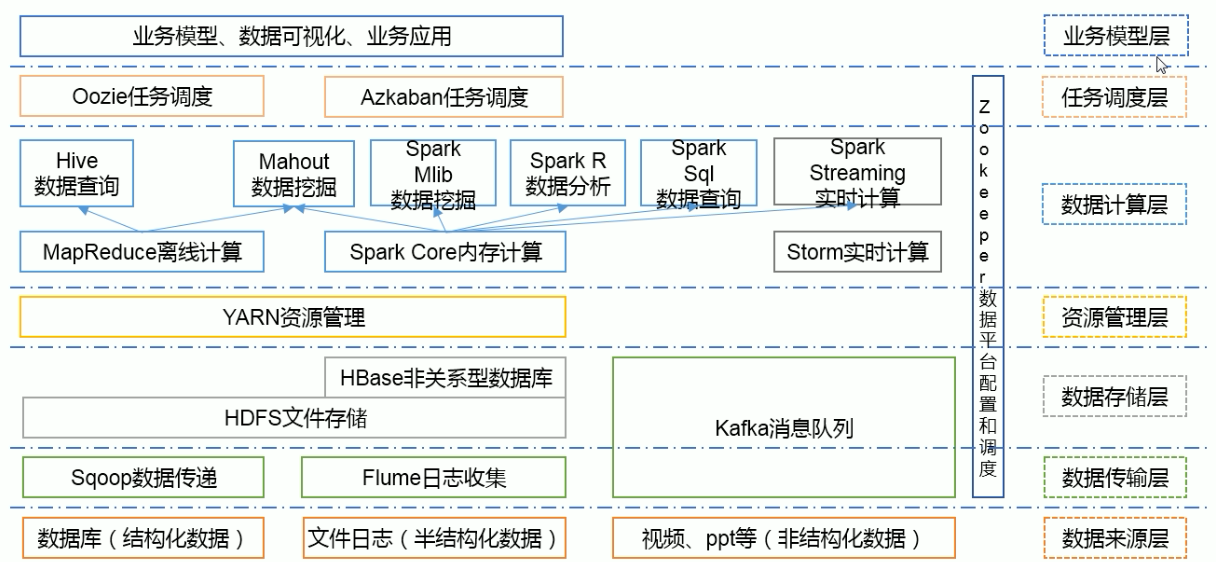
推荐系统
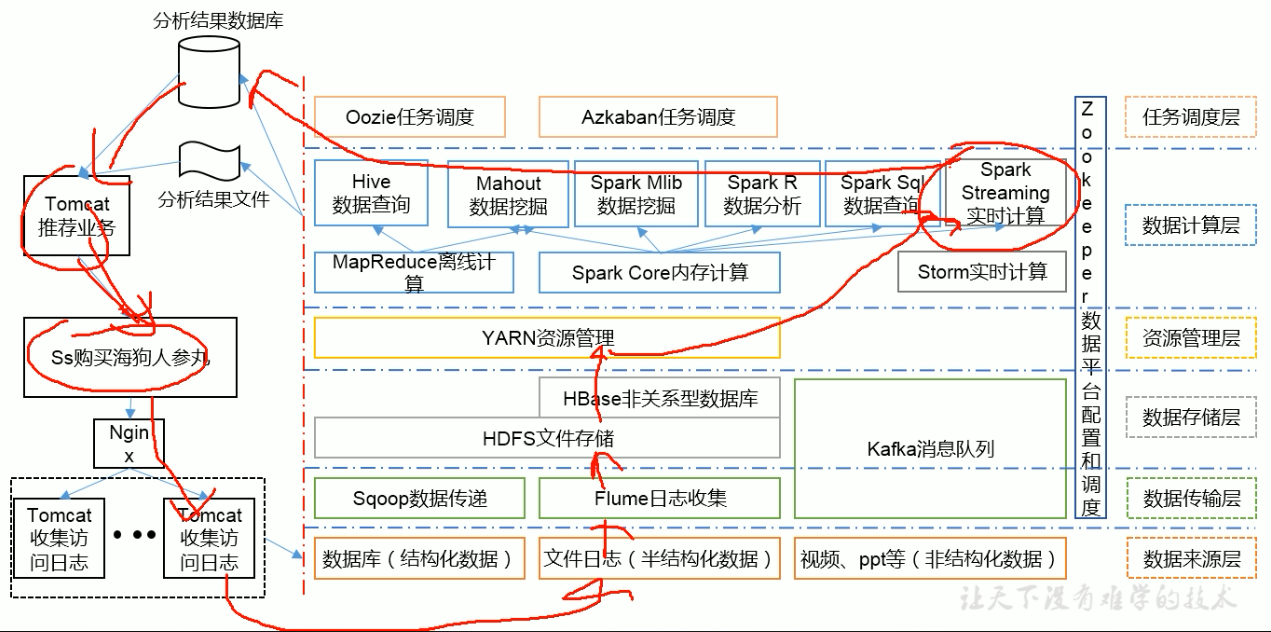
应用场景
- 搭建大型数据仓库,PB级数据的存储、处理、分析、统计
- 日志分析
- 数据挖掘
核心组件
HDFS(分布式文件存储系统)
- 特点:扩展性、容错性、海量数据存储
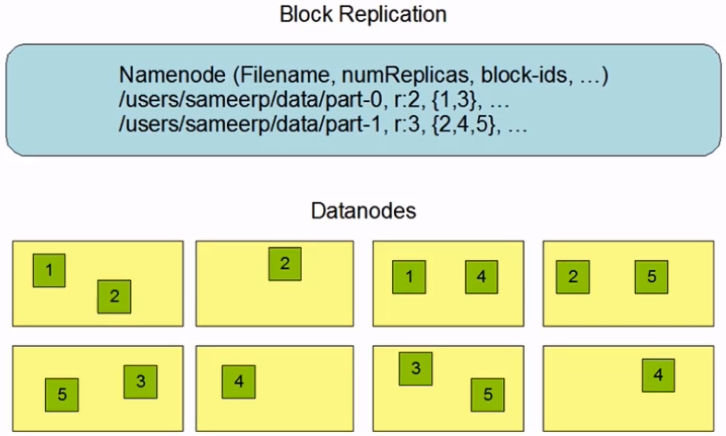
- 将文件切分成指定大小(默认128M)的数据块并以多副本(默认3副本)的存储在多个机器上
- 数据切分、多副本、容错等操作对用户是透明的
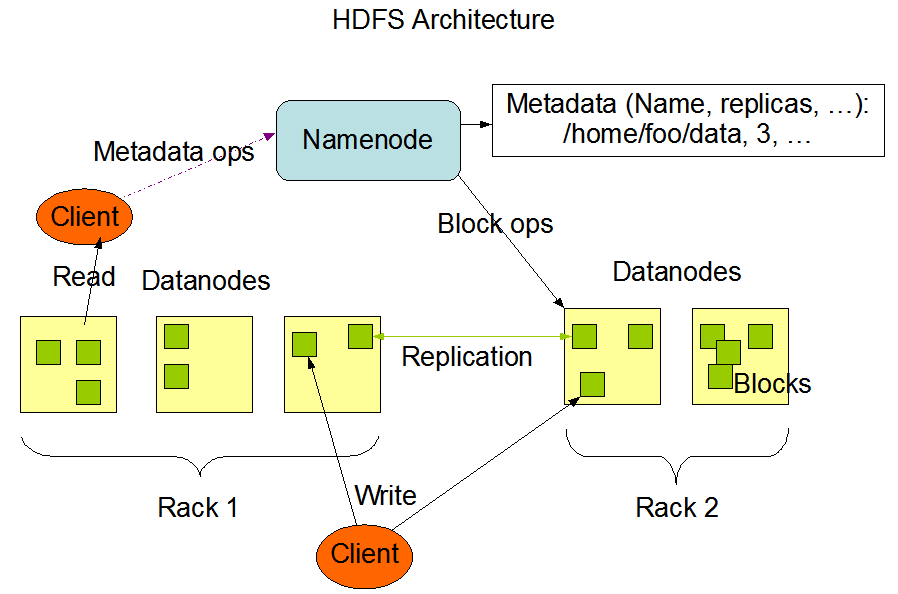
架构
- 1个master(NameNode/NN)带n个slave(datanode/DN)
- 1个文件会被拆分成多个Block(blocksize=128M)
- NN:
- 负责客户端请求响应
- 负责元数据(文件名称、副本系数、block存放的DN)管理
- DN:
- 存储用户的文件对应的数据块(block)
- 定期向NN发送心跳信息,汇报本身及所有的block信息,健康状况
hdfs副本策略
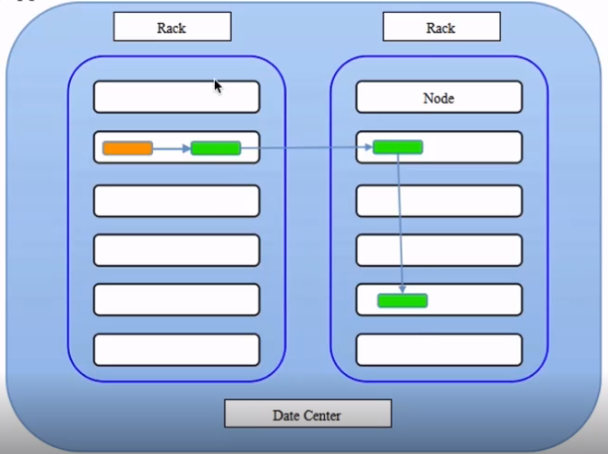
Yarn(资源调度系统)
- 特点:扩展性、容错性(任务失败重试)、多框架资源统一调度 (比如spark、hivesql、hbase、storm)
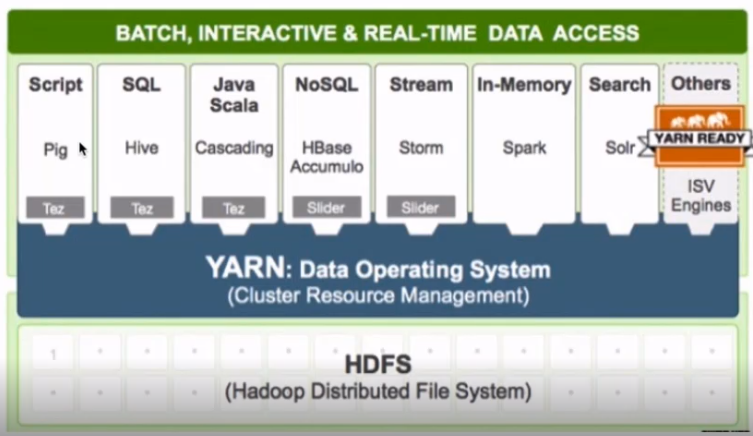
- yarn:Yet another resource negotiator
- 负责整个集群资源的管理和调度
MapReduce(分布式计算框架)
- 特点:扩展性、容错性、海量离线数据处理

Hadoop的优势
高可靠性
- 数据存储:数据块多副本
- 数据计算:重新调度作业计算
扩展性
- 存储/计算资源不够时,可以横向的线性扩展机器
- 一个集群可以包含数以千计的节点
其他
- 存储在廉价机器上,降低成本
- 成熟的生态圈
Hadoop常用发行版及选型
- Apache Hadoop(解决了单个框架的问题,联合使用时很多包冲突)
- CDH:Cloudera Distributed Hadoop(60~70%)
- HDP:Hortonworks Data PlatForm
认识Hadoop的更多相关文章
- Hadoop 中利用 mapreduce 读写 mysql 数据
Hadoop 中利用 mapreduce 读写 mysql 数据 有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如一些 pv.uv 数据,然后为了实时查询的需求,或者一些 OLAP ...
- 初识Hadoop、Hive
2016.10.13 20:28 很久没有写随笔了,自打小宝出生后就没有写过新的文章.数次来到博客园,想开始新的学习历程,总是被各种琐事中断.一方面确实是最近的项目工作比较忙,各个集群频繁地上线加多版 ...
- hadoop 2.7.3本地环境运行官方wordcount-基于HDFS
接上篇<hadoop 2.7.3本地环境运行官方wordcount>.继续在本地模式下测试,本次使用hdfs. 2 本地模式使用fs计数wodcount 上面是直接使用的是linux的文件 ...
- hadoop 2.7.3本地环境运行官方wordcount
hadoop 2.7.3本地环境运行官方wordcount 基本环境: 系统:win7 虚机环境:virtualBox 虚机:centos 7 hadoop版本:2.7.3 本次先以独立模式(本地模式 ...
- 【Big Data】HADOOP集群的配置(一)
Hadoop集群的配置(一) 摘要: hadoop集群配置系列文档,是笔者在实验室真机环境实验后整理而得.以便随后工作所需,做以知识整理,另则与博客园朋友分享实验成果,因为笔者在学习初期,也遇到不少问 ...
- Hadoop学习之旅二:HDFS
本文基于Hadoop1.X 概述 分布式文件系统主要用来解决如下几个问题: 读写大文件 加速运算 对于某些体积巨大的文件,比如其大小超过了计算机文件系统所能存放的最大限制或者是其大小甚至超过了计算机整 ...
- 程序员必须要知道的Hadoop的一些事实
程序员必须要知道的Hadoop的一些事实.现如今,Apache Hadoop已经无人不知无人不晓.当年雅虎搜索工程师Doug Cutting开发出这个用以创建分布式计算机环境的开源软...... 1: ...
- Hadoop 2.x 生态系统及技术架构图
一.负责收集数据的工具:Sqoop(关系型数据导入Hadoop)Flume(日志数据导入Hadoop,支持数据源广泛)Kafka(支持数据源有限,但吞吐大) 二.负责存储数据的工具:HBaseMong ...
- Hadoop的安装与设置(1)
在Ubuntu下安装与设置Hadoop的主要过程. 1. 创建Hadoop用户 创建一个用户,用户名为hadoop,在home下创建该用户的主目录,就不详细介绍了. 2. 安装Java环境 下载Lin ...
- 基于Ubuntu Hadoop的群集搭建Hive
Hive是Hadoop生态中的一个重要组成部分,主要用于数据仓库.前面的文章中我们已经搭建好了Hadoop的群集,下面我们在这个群集上再搭建Hive的群集. 1.安装MySQL 1.1安装MySQL ...
随机推荐
- 使用RSS订阅
1.绪论 对某一主题完成一次文献检索后,我们希望能持续了解该主题最新文献,即实现文献追踪. 为此,搜索引擎和数据库厂商(数据源)提供一般两种订阅服务:邮件和RSS.订阅后,数据源会自动推送最新信息,免 ...
- 利用七牛存储7天远程自动备份LINUX服务器
受服务器空间制约,我们不可能在VPS上每天都备份一份新的网站数据,一是没必要,二是占空间.我们折中一下,采用星期命名,每次备份将覆盖上星期同一天的文件.从而只备份7份数据,不至于占用特别大的空间. 如 ...
- 杭电1518 Square(构成正方形) 搜索
HDOJ1518 Square Time Limit: 10000/5000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) ...
- [SoapUI] Property Expansion in soapUI
1. Property Expansion in soapUI SoapUI provides a common syntax to dynamically insert ("expand& ...
- rabbitmq安装.教程
https://www.cnblogs.com/ericli-ericli/p/5902270.html (rabbitmq安装)https://www.cnblogs.com/iiwen/p/538 ...
- jqgrid子表格
.前台 <%-- builed by manage.aspx.cmt [ver:] at // :: --%> <%@ Page Language="C#" Au ...
- 各种编译不通过xcode
2017-08-24 Apple Mach-O Linker (Id) Error Linker command failed with exit code 1 (use -v to see invo ...
- Vue单页面应用
单页面应用指一个系统只加载一次资源,然后下面的操作交互.数据交互是通过router.ajax来进 行,页面并没有刷新:<1>在vue搭建的环境里面怎么有没有公用的css和js? ...
- C# 使用 HttpPost 请求调用 WebService
之前调用 WebService 都是直接添加服务引用,然后调用 WebService 方法的,最近发现还可以使用 Http 请求调用 WebService.这里还想说一句,还是 web api 的调用 ...
- 字符串方法 split() & replace()
split() 语法:stringObject.split(separator) 功能:把一个字符串分割成字符串数组 返回值:Array 说明:separator 是必须的,分隔符. var str= ...