Hadoop3集群搭建之——hive安装
现在到hive了。
hive安装比较简单。
下载个包,解压,配置hive-site.xml、hive-env.sh 就好了。
1、下载hive包
官网:http://mirror.bit.edu.cn/apache/hive/hive-2.3.3/
2、解压到hadoop目录
tar -zxvf apache-hive-2.3.-bin.tar.gz #解压
mv apache-hive-2.3.-bin hive2.3.3 #修改目录名,方便使用
3、配置hive环境变量
[hadoop@venn05 ~]$ more .bashrc
# .bashrc # Source global definitions
if [ -f /etc/bashrc ]; then
. /etc/bashrc
fi # Uncomment the following line if you don't like systemctl's auto-paging feature:
# export SYSTEMD_PAGER= # User specific aliases and functions
#jdk
export JAVA_HOME=/opt/hadoop/jdk1.
export JRE_HOME=${JAVA_HOME}/jre
export CLASS_PATH=${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH #hadoop
export HADOOP_HOME=/opt/hadoop/hadoop3
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH #hive
export HIVE_HOME=/opt/hadoop/hive2.3.3
export HIVE_CONF_DIR=$HIVE_HOME/conf
export PATH=$HIVE_HOME/bin:$PATH
4、在hdfs上创建hive目录
hive工作目录如下:
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
<property>
<name>hive.exec.scratchdir</name>
<value>/tmp/hive</value>
<description>HDFS root scratch dir for Hive jobs which gets created with write all () permission. For each connecting user, an HDFS scratch dir: ${hive.exec.scratchdir}/<username> is created, with ${hive.scratch.dir.permission}.</description>
</property>
所以创建如下目录:
hadoop fs -mkdir -p /user/hive/warehouse #hive库文件位置
hadoop fs -mkdir -p /tmp/hive/ #hive临时目录
#授权
hadoop fs -chmod -R 777 /user/hive/warehouse
hadoop fs -chmod -R 777 /tmp/hive
注:必须授权,不然会报错:
Logging initialized using configuration in jar:file:/opt/hadoop/hive2.3.3/lib/hive-common-2.3..jar!/hive-log4j2.properties Async: true
Exception in thread "main" java.lang.RuntimeException: The root scratch dir: /tmp/hive on HDFS should be writable. Current permissions are: rwxr-xr-x
at org.apache.hadoop.hive.ql.session.SessionState.createRootHDFSDir(SessionState.java:)
at org.apache.hadoop.hive.ql.session.SessionState.createSessionDirs(SessionState.java:)
at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:)
at org.apache.hadoop.hive.ql.session.SessionState.beginStart(SessionState.java:)
at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:)
at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:)
at java.lang.reflect.Method.invoke(Method.java:)
at org.apache.hadoop.util.RunJar.run(RunJar.java:)
at org.apache.hadoop.util.RunJar.main(RunJar.java:)
5、修改hive-site.xml
cp hive-default.xml.template hive-site.xml
vim hive-site.xml
修改1: 将hive-site.xml 中的 “${system:java.io.tmpdir}” 都缓存具体目录:/opt/hadoop/hive2.3.3/tmp 4处
修改2: 将hive-site.xml 中的 “${system:user.name}” 都缓存具体目录:root 3处
<property>
<name>hive.exec.local.scratchdir</name>
<value>${system:java.io.tmpdir}/${system:user.name}</value>
<description>Local scratch space for Hive jobs</description>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>${system:java.io.tmpdir}/${hive.session.id}_resources</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>
<property>
<name>hive.querylog.location</name>
<value>${system:java.io.tmpdir}/${system:user.name}</value>
<description>Location of Hive run time structured log file</description>
</property>
<property>
<name>hive.server2.logging.operation.log.location</name>
<value>${system:java.io.tmpdir}/${system:user.name}/operation_logs</value>
<description>Top level directory where operation logs are stored if logging functionality is enabled</description>
</property>
改为:
<property>
<name>hive.exec.local.scratchdir</name>
<value>/opt/hadoop/hive2.3.3/tmp/root</value>
<description>Local scratch space for Hive jobs</description>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/opt/hadoop/hive2.3.3/tmp/${hive.session.id}_resources</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>
<property>
<name>hive.querylog.location</name>
<value>/opt/hadoop/hive2.3.3/tmp/root</value>
<description>Location of Hive run time structured log file</description>
</property>
<property>
<name>hive.server2.logging.operation.log.location</name>
<value>/opt/hadoop/hive2.3.3/tmp/root/operation_logs</value>
<description>Top level directory where operation logs are stored if logging functionality is enabled</description>
配置元数据库mysql:
mysql> CREATE USER 'hive'@'%' IDENTIFIED BY 'hive'; #创建hive用户
Query OK, rows affected (0.00 sec) mysql> GRANT ALL ON *.* TO 'hive'@'%'; #授权
Query OK, rows affected (0.00 sec)
修改数据库配置:
<!-- mysql 驱动 -->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<!-- 链接地址 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://venn05:3306/hive?createDatabaseIfNotExist=true</value>
<description>
JDBC connect string for a JDBC metastore.
To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.
For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.
</description>
</property>
<!-- 用户名 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>Username to use against metastore database</description>
</property>
<!-- 密码 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>
6、修改hive-env.sh
cp hive-env.sh.template hive-env.sh
vim hive-env.sh
在末尾添加如下内容:
export HADOOP_HOME=/opt/hadoop/hadoop3
export HIVE_CONF_DIR=/opt/hadoop/hive2.3.3/conf
export HIVE_AUX_JARS_PATH=/opt/hadoop/hive2.3.3/lib
7、上传mysql驱动包

上传到:$HIVE_HOME/lib

8、初始化hive
schematool -initSchema -dbType mysql
9、启动hive
hive
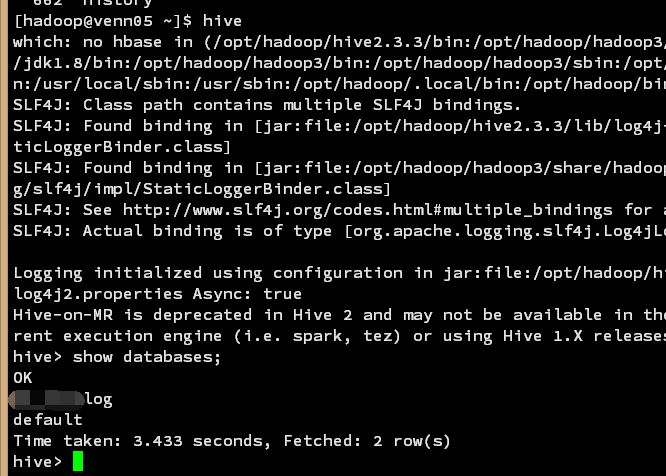
搞定
Hadoop3集群搭建之——hive安装的更多相关文章
- Hadoop3集群搭建之——hbase安装及简单操作
折腾了这么久,hbase终于装好了 ------------------------- 上篇: Hadoop3集群搭建之——虚拟机安装 Hadoop3集群搭建之——安装hadoop,配置环境 Hado ...
- Hadoop3集群搭建之——hive添加自定义函数UDTF (一行输入,多行输出)
上篇: Hadoop3集群搭建之——虚拟机安装 Hadoop3集群搭建之——安装hadoop,配置环境 Hadoop3集群搭建之——配置ntp服务 Hadoop3集群搭建之——hive安装 Hadoo ...
- Hadoop3集群搭建之——hive添加自定义函数UDTF
上篇: Hadoop3集群搭建之——虚拟机安装 Hadoop3集群搭建之——安装hadoop,配置环境 Hadoop3集群搭建之——配置ntp服务 Hadoop3集群搭建之——hive安装 Hadoo ...
- Hadoop3集群搭建之——hive添加自定义函数UDF
上篇: Hadoop3集群搭建之——虚拟机安装 Hadoop3集群搭建之——安装hadoop,配置环境 Hadoop3集群搭建之——配置ntp服务 Hadoop3集群搭建之——hive安装 Hadoo ...
- Hadoop3集群搭建之——虚拟机安装
现在做的项目是个大数据报表系统,刚开始的时候,负责做Java方面的接口(项目前端为独立的Java web 系统,后端也是Java web的系统,前后端系统通过接口传输数据),后来领导觉得大家需要多元化 ...
- Hadoop3集群搭建之——安装hadoop,配置环境
接上篇:Hadoop3集群搭建之——虚拟机安装 下篇:Hadoop3集群搭建之——配置ntp服务 Hadoop3集群搭建之——hive安装 Hadoop3集群搭建之——hbase安装及简单操作 上篇已 ...
- Hadoop3集群搭建之——配置ntp服务
上篇: Hadoop3集群搭建之——虚拟机安装 Hadoop3集群搭建之——安装hadoop,配置环境 下篇: Hadoop3集群搭建之——hive安装 Hadoop3集群搭建之——hbase安装及简 ...
- Hadoop集群搭建-03编译安装hadoop
Hadoop集群搭建-05安装配置YARN Hadoop集群搭建-04安装配置HDFS Hadoop集群搭建-03编译安装hadoop Hadoop集群搭建-02安装配置Zookeeper Hado ...
- BigData--hadoop集群搭建之hbase安装
之前在hadoop-2.7.3 基础上搭建hbase 详情请见:https://www.cnblogs.com/aronyao/p/hadoop.html 基础条件:先配置完成zookeeper 准备 ...
随机推荐
- 微信小程序——过滤器的模拟
>> 编写wxs文件——filter.wxs //1. 价格格式化 function getPriceFormat(value) { return parseFloat(isNaN(val ...
- selenium学习一
chrome版本和chromedriver的对应关系 chromedriver版本 支持的Chrome版本 v2.40 v66-68 v2.39 v66-68 v2.38 v65-67 v2.37 v ...
- swift语言版本选择 - 解决XCode报错:The “Swift Language Version” (SWIFT_VERSION) build setting must be set to a supported valu
转发链接:https://blog.csdn.net/nathan1987_/article/details/79757368 The “Swift Language Version” (SWIFT_ ...
- iOS 开发实用工具
史蒂芬的博客 (各种软件) http://www.sdifen.com/ 产品原型设计工具 -- 1.墨刀 2.Axure RP 检测接口工具 ---- 1.Charles 2. postman607 ...
- [BX]指令
mov ax,[bx] 功能:bx中存放的数据作为一个偏移地址EA,段地址SA默认在ds中,将SA:EA处的数据送入ax中.即(ax)=((ds)*16+(bx)). mov [bx],ax 功能:b ...
- c#dev tabcontrol 切换页面时注意的问题
先加一个代码 public void SetXtraTabPageVisible(DevExpress.XtraTab.XtraTabControl xtraTabControl, bool iIsV ...
- (转)Android中Parcelable接口用法
1. Parcelable接口 Interface for classes whose instances can be written to and restored from a Parcel. ...
- mybatis入门--#{}和${}的区别
我们知道,在mybatis中,sql语句是需要我们自己写的.跟在普通的sql不一样的是,我们在使用mybatis框架的时候,使用的占位符不是 ? 而是 #{} 有时候还会出现这个符号 ${} 这些符号 ...
- Zookeeper简介与使用
1. Zookeeper概念简介: Zookeeper是一个分布式协调服务:就是为用户的分布式应用程序提供协调服务 A.zookeeper是为别的分布式程序服务的 B.Zookeeper本身就是一 ...
- hdu 1072(BFS) 有炸弹
http://acm.hdu.edu.cn/showproblem.php?pid=1072 题目大意是在一个n×m的地图上,0表示墙,1表示空地,2表示人,3表示目的地,4表示有定时炸弹重启器. 定 ...