StanFord ML 笔记 第八部分
第八部分内容:
1.正则化Regularization
2.在线学习(Online Learning)
3.ML 经验
1.正则化Regularization
1.1通俗解释
引用知乎作者:刑无刀
解释之前,先说明这样做的目的:如果一个模型我们只打算对现有数据用一次就不再用了,那么正则化没必要了,因为我们没打算在将来他还有用,正则化的目的是为了让模型的生命更长久,把它扔到现实的数据海洋中活得好,活得久。
俗气的解释1:
让模型参数不要在优化的方向上纵欲过度。《红楼梦》里,贾瑞喜欢王熙凤得了相思病,病榻中得到一枚风月宝鉴,可以进入和心目中的女神XXOO,它脑子里的模型目标函数就是“最大化的爽”,所以他就反复去拟合这个目标,多次XXOO,于是人挂掉了,如果给他加一个正则化,让它爽,又要控制爽的频率,那么他可以爽得更久。
俗气的解释2:
假如马化腾心中的商业模型优化目标是让腾讯发展得更好,他的模型只有一个特征,就是张小龙,根据他的目标以及已有样本,它应该给张小龙赋予更大的权重,就可以一直让模型的表现朝这个目标前进,但是,突然有一天马化腾意识到:这样下去不行啊,他的权重大得没边的话,根本不可持续啊,他要是走了,他要是取代我了。于是马化腾就需要在优化这个目标的时候给这个唯一的特征加一个正则化参数,让权重不要过大,从而使得整个模型能够既朝着设定目标走,又不至于无法持续。
俗气的解释3:
我们这群技术男在公司里,如果模型目标是提高自身能力并最终能够在公司有一席之地,理想的优化方法是提高各种牛逼算法,各种高大上的计算平台的熟悉程度,尽量少开无谓的会议,少接领导扯淡的需求,但是如果只是这些的话,很可能在这个公司呆不太久,因为太关注自己的特征权重了,那么如果这个公司其实非常适合提升自己的能力,那么要能在这里呆久点,就得适当限制自己这些特征的权重绝对值,不要那么绝对坚持用到牛逼算法,偶尔也处理处理领导的扯淡需求,平衡一下,你的模型才能泛化得更广。
1.2用协方差解释
引用知乎作者:维吉特伯
其中 和
是列向量,
是矩阵,矩阵的每一行对应一个输入实例。把平方误差和(residual sum of squares, RSS)作为损失函数:
假设要拟合一个线性的模型
写成矩阵形式就是
把 对
求偏导,并令偏导为0,
可以得出最小化损失的解:
然后再对损失添加正则化项(为了简化推导就用岭回归吧,添加 的平方项),下面我就直接写成向量形式啦:
同样,再对 求偏导,并令偏导为0
得出解为:
然后,对 进行奇异值分解(SVD):
再拿训练得到的 再拟合一下训练数据,再套用一下奇异值分解:
对比一下没有正则化项的情况:
发现什么了吗,正则化之后, 和
之间相差了一个系数
。
因为 ,所以
。
这意味着加入正则化项的岭回归拟合的结果被缩小了 倍。那么,这个
的意义是什么呢?
再对输入作进一步假设来简化问题。如果输入 的均值为0,也就是对
进行预处理使得:
那么, 的协方差就可以通过
计算,并且根据之前的奇异值分解
,有
这实际上也可以看作是 的特征分解。
所以 就是
的第
个特征值。
因此系数 可以看作根据协方差矩阵的特征值对不同成分进行收缩(个人理解为进行了一次隐式的特征选择),并且对特征值小的成分收缩更为剧烈(可以理解为通过把那些方差小的成分舍弃掉了,有点类似主成分分析,把那些重要的成分留下,次要的去除掉)。除了
之外,
也会影响收缩的程度。
值越大,收缩的越剧烈(需要更大的
来补偿
),最终模型复杂度越低 。附上来自《The Elements of Statistical Learning》的图。
<span style="font-size: 14pt;">&amp;amp;lt;img src="https://pic2.zhimg.com/50/v2-9408eada5159a960cf75bb3599089409_hd.png" data-rawwidth="689" data-rawheight="613" class="origin_image zh-lightbox-thumb" width="689" data-original="https://pic2.zhimg.com/v2-9408eada5159a960cf75bb3599089409_r.png"&amp;amp;gt;</span>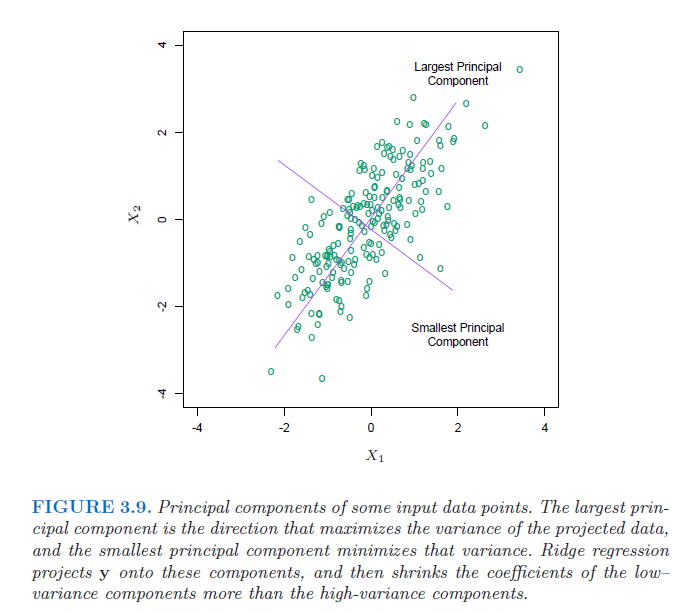
这样通过正则化项,就去减小了那些没用(次要)的特征带来的影响,防止过拟合。
1.3Ng视频的讲解
http://blog.csdn.net/stdcoutzyx/article/details/18500441
1.4个人总结
A.加入先验概率,正如我们都知道骰子每个概率是1/6,但是实验10次都是正面,我们能说正面概率为百分之百吗?加入前面的先验1/6效果就好多了。
B.在似然函数后面加上了aXXT,后面的XXT就是协方差,前面的a是比例,协方差的意思就是太离谱的数据权重就小,a的作用和高斯的均值一样。
2.在线学习
批量学习:一次性给样本
在线学习:多次性给样本
参考:https://www.zhihu.com/question/20700829(正则化的话题,很多知乎大神的回答)
StanFord ML 笔记 第八部分的更多相关文章
- StanFord ML 笔记 第三部分
第三部分: 1.指数分布族 2.高斯分布--->>>最小二乘法 3.泊松分布--->>>线性回归 4.Softmax回归 指数分布族: 结合Ng的课程,在看这篇博文 ...
- StanFord ML 笔记 第五部分
1.朴素贝叶斯的多项式事件模型: 趁热打铁,直接看图理解模型的意思:具体求解可见下面大神给的例子,我这个是流程图. 在上篇笔记中,那个最基本的NB模型被称为多元伯努利事件模型(Multivariate ...
- StanFord ML 笔记 第一部分
本章节内容: 1.学习的种类及举例 2.线性回归,拟合一次函数 3.线性回归的方法: A.梯度下降法--->>>批量梯度下降.随机梯度下降 B.局部线性回归 C.用概率证明损失函数( ...
- StanFord ML 笔记 第十部分
第十部分: 1.PCA降维 2.LDA 注释:一直看理论感觉坚持不了,现在进行<机器学习实战>的边写代码边看理论
- StanFord ML 笔记 第九部分
第九部分: 1.高斯混合模型 2.EM算法的认知 1.高斯混合模型 之前博文已经说明:http://www.cnblogs.com/wjy-lulu/p/7009038.html 2.EM算法的认知 ...
- StanFord ML 笔记 第六部分&&第七部分
第六部分内容: 1.偏差/方差(Bias/variance) 2.经验风险最小化(Empirical Risk Minization,ERM) 3.联合界(Union bound) 4.一致收敛(Un ...
- StanFord ML 笔记 第四部分
第四部分: 1.生成学习法 generate learning algorithm 2.高斯判别分析 Gaussian Discriminant Analysis 3.朴素贝叶斯 Navie Baye ...
- StanFord ML 笔记 第二部分
本章内容: 1.逻辑分类与回归 sigmoid函数概率证明---->>>回归 2.感知机的学习策略 3.牛顿法优化 4.Hessian矩阵 牛顿法优化求解: 这个我就不记录了,看到一 ...
- VSTO学习笔记(八)向 Word 2010 中写入表结构
原文:VSTO学习笔记(八)向 Word 2010 中写入表结构 前几天公司在做CMMI 3级认证,需要提交一系列的Word文档,其中有一种文档要求添加公司几个系统的数据库中的表结构.我临时接到了这项 ...
随机推荐
- ubuntu下pycharm调用Hanlp实践分享
前几天看了大快的举办的大数据论坛峰会的现场直播,惊喜的是hanlp2.0版本发布.Hanlp2.0版本将会支持任意多的语种,感觉还是挺好的!不过更多关于hanlp2.0的信息,可能还需要过一段时间才能 ...
- [转] openwrt关闭调试串口
转自: http://wiki.wrtnode.com/index.php?title=Release_UART/zh-cn 由于mt7620n只有一个UART lite接口,在原生的OpenWrt中 ...
- 【转】python文件和目录操作方法大全(含实例)
python文件和目录操作方法大全(含实例) 这篇文章主要介绍了python文件和目录的操作方法,简明总结了文件和目录操作中常用的模块.方法,并列举了一个综合实例,需要的朋友可以参考下一.python ...
- ubuntu如何为获得root权限
在终端中输入:sudo passwd rootEnter new UNIX password: (在这输入你的密码)Retype new UNIX password: (确定你输入的密码)passwd ...
- 关于opcdaauto.dll的注册
关于opcdaauto.dll的注册 无论win7_32还是win7_64位都执行一样的CMD命令,即regsvr32 opcdaauto.dll . 如果从网上下载的opcdaauto.dll 文件 ...
- tomcat源码 分析 Catalina
通过查看分析启动脚本,发现最终调用的入口是org.apache.catalina.startup包下面的Bootstrap#main public static void main(String ar ...
- js 把字符串保存为txt文件,并下载到本地
代码如下 exportRaw('text.txt','123123123') function fakeClick(obj) { var ev = document.createEvent(" ...
- 【mysql】ICP下mysql执行计划的一次解析
mysql版本 [root@xxxx]# mysql --version mysql Ver 15.1 Distrib 5.5.52-MariaDB, for Linux (x86_64) using ...
- 观察者模式之一:java实现观察者模式
<观察者模式之一:java实现观察者模式> <观察者模式之二:JDK自带的观察者模式> 1.初步认识 观察者模式的定义: 在对象之间定义了一对多的依赖,这样一来,当一个对象改变 ...
- YAML配置,spring boot 配置文件
1 概念YAML是一种人们可以轻松阅读的数据序列化格式,并且它非常适合对动态编程语言中使用的数据类型进行编码.YAML是YAML Ain't Markup Language简写,和GNU(" ...