025 Spark中的广播变量原理以及测试(共享变量是spark中第二个抽象)
一:来源
1.说明
为啥要有这个广播变量呢。
一些常亮在Driver中定义,然后Task在Executor上执行。
如果,有多个任务在执行,每个任务需要,就会造成浪费。
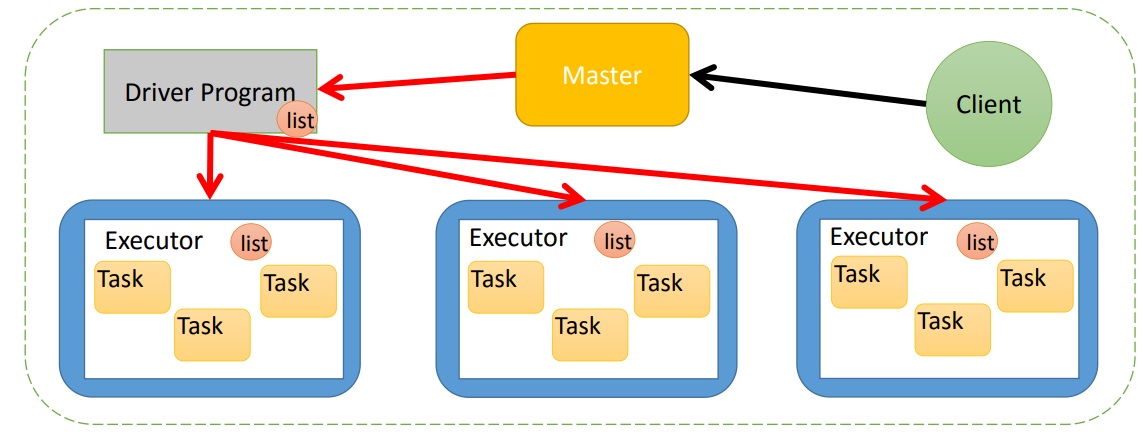
二:共享变量的官网
1.官网
有两种方式。

三:程序实现
1.Accumulators
类似于mapreduce中的用于累加数据的共享变量
这是一个官方的案例。

2.官网上的程序

3.广播变量程序实现
作用:
可以减少网络传输量
可以解决大表join小表的问题(将小表的数据广播出去)
注意:
不能广播RDD,可以广播RDD中的数据。

025 Spark中的广播变量原理以及测试(共享变量是spark中第二个抽象)的更多相关文章
- spark中的广播变量broadcast
Spark中的Broadcast处理 首先先来看一看broadcast的使用代码: val values = List[Int](1,2,3) val broadcastValues = sparkC ...
- 入门大数据---Spark累加器与广播变量
一.简介 在 Spark 中,提供了两种类型的共享变量:累加器 (accumulator) 与广播变量 (broadcast variable): 累加器:用来对信息进行聚合,主要用于累计计数等场景: ...
- Spark大师之路:广播变量(Broadcast)源代码分析
概述 近期工作上忙死了--广播变量这一块事实上早就看过了,一直没有贴出来. 本文基于Spark 1.0源代码分析,主要探讨广播变量的初始化.创建.读取以及清除. 类关系 BroadcastManage ...
- Spark大师之路:广播变量(Broadcast)源码分析
概述 最近工作上忙死了……广播变量这一块其实早就看过了,一直没有贴出来. 本文基于Spark 1.0源码分析,主要探讨广播变量的初始化.创建.读取以及清除. 类关系 BroadcastManager类 ...
- Spark(八)【广播变量和累加器】
目录 一. 广播变量 使用 二. 累加器 使用 使用场景 自定义累加器 在spark程序中,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的 ...
- spark累加器、广播变量
一言以蔽之: 累加器就是只写变量 通常就是做事件统计用的 因为rdd是在不同的excutor去执行的 你在不同excutor中累加的结果 没办法汇总到一起 这个时候就需要累加器来帮忙完成 广播变量是只 ...
- C++晋升之std中vector的实现原理(标准模板动态库中矢量的实现原理)
我们实现的数据结构是为了解决在执行过程中动态的开辟空间使用(比如我们不停的输入,输入的多少我们不确定) 假设当你看到这篇文章的话,就当作是零食咀嚼,营养没有有BUG,能够直接看我博客中文章:CPU对内 ...
- spark 广播变量
Spark广播变量 使用广播变量来优化,广播变量的原理是: 在每一个Executor中保存一份全局变量,task在执行的时候需要使用和这一份变量就可以,极大的减少了Executor的内存开销. Exe ...
- Spark学习之路(六)—— 累加器与广播变量
一.简介 在Spark中,提供了两种类型的共享变量:累加器(accumulator)与广播变量(broadcast variable): 累加器:用来对信息进行聚合,主要用于累计计数等场景: 广播变量 ...
随机推荐
- mysql列类型char,varchar,text,tinytext,mediumtext,longtext的比较与选择
储存不区分大小写的字符数据 TINYTEXT 最大长度是 255 (2^8 – 1) 个字符. TEXT 最大长度是 65535 (2^16 – 1) 个字符. MEDIUMTEXT 最大长度是 16 ...
- BZOJ 4173: 数学
4173: 数学 Time Limit: 10 Sec Memory Limit: 256 MBSubmit: 462 Solved: 227[Submit][Status][Discuss] D ...
- 【BZOJ5281】Talent Show(分数规划)
[BZOJ5281]Talent Show(分数规划) 题面 BZOJ 洛谷 题解 二分答案直接就是裸的分数规划,直接跑背包判断是否可行即可. #include<iostream> #in ...
- coin
Decsription 数据范围:\(n<=3000,m<=300\),保证\(\forall i,\sum\limits_{j}p_{ij}=1000\) Solution 日常期望算不 ...
- centos7搭建ELK Cluster集群日志分析平台
应用场景:ELK实际上是三个工具的集合,ElasticSearch + Logstash + Kibana,这三个工具组合形成了一套实用.易用的监控架构, 很多公司利用它来搭建可视化的海量日志分析平台 ...
- nodejs读取json文件,写入mongodb数据库
最近又一点时间,开始使用mongodb存储json模型文件,然后可以实现模型文件的在线编辑和管理.今天上午实现了json文件入库的代码,如下: var fs=require("fs" ...
- 原始套接字-自定义IP首部和TCP首部
/* ===================================================================================== * * Filenam ...
- ASP.NET MVC学习(一)之路由篇Route
什么是路由 通过[路由]配置,路由可以规定URL的特殊格式,使其达到特殊效果. 在ASP.NET MVC框架中,通过路由配置URL,使用户的URL请求可以映射到Controller下的action方法 ...
- Requests中出现大量ASYNC_NETWORK_IO等待
七夕活动,网页显示异常:504 Gateway Time-out The server didn't respond in time.开发询问数据库是否正常,当时正连接在实例上查询数据,感觉响应确实慢 ...
- 用于阻止缓冲区溢出攻击的 Linux 内核参数与 gcc 编译选项
先来看看基于 Red Hat 与 Fedora 衍生版(例如 CentOS)系统用于阻止栈溢出攻击的内核参数,主要包含两项: kernel.exec-shield 可执行栈保护,字面含义比较“绕”, ...