SSIS 剖析数据流之:连接和查找转换
在SSIS的数据流组件中,SSIS引擎使用Merge Join组件和 Lookup组件实现TSQL语句中的inner join 和 outer join 功能,Lookup查找组件的功能更类似TSQL的Exists关键字,只检查数据是否存在。在SSIS引擎中,任何流经数据流(Data Flow)组件的数据都会被加载到服务器内存的数据缓冲区中,数据缓冲区能够容纳的数据量决定了转换组件的性能。
一,转换组件的结构
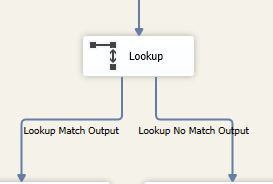
1,Lookup转换组件有一个输入(Input),一个查找表(或叫缓存表,引用表),映射关系和多个输出(Output)
映射关系是指Lookup转换组件的输入(Input)列和查找列之间的相等关系,定义了输入和引用表之间按照什么条件进行匹配,相当于定义Join子句的On条件;在创建映射关系时,用户需要显式指定一个或多个映射关系,就是说,用户需要指定哪些Input列和查找列之间具有相等关系。

Lookup组件查找的过程是:对于输入(Input)中的每一个数据行,根据映射关系,对查找表进行全表查找;如果该数据行能够在查找表中找到相应的键值,那么该数据行匹配成功,从“Lookup Match Output” 路径输出到下游组件;如果不能在查找表中找到相应的键值,那么该数据行匹配失败,从“Lookup No Match Output”路径输出到下游组件。
由于输入中每一个行数据都会查找整个缓存表,因此,如果将查找表数据缓存在内存中,能够提高Lookup组件的查找性能,Lookup转换组件提供三种缓存模式来处理查找表的数据:全部缓存在内存,部分缓存在内存中,每次都从数据源中读取。如果查找表数据量少,请全部缓存在内存中,以提高Lookup组件的转换性能。
Lookup组件在Full Cache模式下是无阻塞转换,只有Lookup转换组件在加载缓存表数据时,它才会阻塞数据流。只有当缓存表数据加载完成之后,查找转换组件才开始运行。一旦缓存数据加载完成,数据以无阻塞的流式来处理数据。
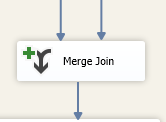
2,Merge Join转换组件有两个有序的输入(Sorted Input,使用Sort组件排序,或者在数据库中使用Order by 子句排序)和一个输出(Output)
在Merge Join转换组件配置联接条件(inner join,left join和full join),执行连接查询之后,输出相应的数据。下游组件可以使用Conditional Split 转换组件,获取匹配成功或匹配失败的数据。Merge Join转换组件没有缓存数据。
二,Lookup 转换
1,流的特性
Lookup 转换是非阻塞转换,具有流式转换的特性,能够边加载数据,边对数据进行转换处理,这意味着,当新的数据行进入Lookup转换组件时,已经被处理完成的数据行会被传递到下游组件,而不会被拦截,就像水流一样,绵绵不绝,直到所有数据处理完成。
当Lookup转换组件处于Full Cache缓存模式时,Lookup转换组件在将缓存表加载到内存中时,会阻塞数据流,直到所有的查找数据都加载到缓冲区后,才开始真正执行数据流任务(Data Flow Task),因此,为了提高查找转换的性能,确保将小表作为缓存表(设置为Full Cache模式),而将大表的数据以流式输入到Lookup转换组件中。
当Lookup转换组件处于Partial Cache或No Cache缓存模式时,Looup 转换组件被识别为基于行(row-based)的转换,流经Lookup转换组件的数据行,需要与一个外部输入进行交互,从而被逐一处理。鉴于基于行的处理过程,在大多数情况下无法跟上数据流处理的速度,因此,缓冲区将被拦截阻塞,直到Lookup转换组件处理完缓冲区中的所有数据,所以,当Lookup转换组件处于Partial Cache或No Cache缓存模式时,通常认为Lookup组件具有半阻塞性。
2,缓存模式(Cache Mode)
Lookup 转换组件有三种缓存模式(Cache Mode):Full Cache,Partial Cache 和 No Cache。
全缓存模式(Full Cache)是指Lookup 转换组件将缓存表中的数据全部加载到内存的数据缓冲区中,另一个输入中的每一行数据都会流经缓冲区,执行联接操作。
无缓存模式(No Cache)是指Lookup 转换组件对上游输入的每个数据行,都会执行一次查询,检查数据是否存在于缓存表中。 在No Cache 模式下,当每个输入行流经Lookup 转换组件时,该组件向数据库中的引用表发送一条请求,查看键值是否匹配,这种方式性能非常低下,速度慢。
部分缓存模式(Partial Cache)是指Lookup转换组件在MaxMemoryUsage属性限制的内存使用量下,将最近使用过的数据缓存到内存中,一旦缓存增长过大,最少使用的缓存数据将会被丢弃。如果引用表数据量太大,而无法将其所有数据全部加载到缓存中,可以选择Partial Cache模式。
当Package启动时,与No Cache模式一样,不会将数据预先加载到Lookup Cache中,当每个输入行进入组件时,该组件使用指定的联接键以及指定的查询来尝试查找匹配的记录。如果找到匹配项,那么及时将查找到的键值添加到缓存中,如果相同的键值再次进行查找,那么就可以从缓存中获取匹配键值,从而节省了访问外部输入源的查询时间。如果在缓存中没有找到匹配的键值,那么组件将访问外部输入源,进行查询,如果外部输入中也没有,那么键值不匹配。
MaxMemoryUsage属性指定Lookup 转换组件在Partial Cache模式下所使用的最大内存。
三,Merge Join 转换
1,Merge Join是半阻塞转换
在向下游组件传递数据之前,Merge Join转换组件需要将数据流拦截在缓冲区中一段时间,直到来自两个输入的键值匹配成功,Merge Join转换组件才将数据行向下游组件传递。
2,Merge Join使用少量的内存
相比于Lookup 转换组件,Merge Join转换组件只使用较少的内存,基本上不会缓存数据,因为只需要维护内存中用来联接两个输入所需要的少量数据。当内存容量有限或者,输入的数据量过大时,Merge Join转换组件是一个非常有用的组件,但是,Merge Join转换组件有一个前提条件,输入的数据流必须是有序的,由于SQL Server数据库引擎的排序功能非常强大,因此,推荐将Merge Join的输入数据流在SQL Server 数据库中进行排序,避免使用Sort组件对数据流进行排序。
四,缓存连接管理器
Lookup 转换组件是唯一使用CCM(Cache Connection Manager,简称CCM)对数据进行缓存的组件,CCM能够从任意数据源中填充 Lookup转换组件的缓存。如果Lookup 转换组件处于Full Cache 模式下,那么使用CCM加载缓存数据将会提高转换性能。在同一Package中,如果多个Lookup 转换组件使用相同的缓存数据集,使用CCM缓存数据,这些Lookup转换组件可以共享相同的缓存,这样,就不需要多次加载相同的缓存数据。
五,在数据源组件中,指定数据流是已排序的
step1,有序的输入
在获取数据时,使用Order By子句对数据进行排序,使数据在进入数据源组件时,是已经排过序的。
from dbo.data_source
order by UserID asc,ProfileID desc
step2,设置IsSorted属性为True
打开OLE DB Source 数据源组件的高级编辑器(Advanced Editor),点击“OLE DB Source Output”,将“Common Properties”列表中的IsSorted属性设置为True。该属性不会对数据进行排序,只是标识数据流是有序的。

Step3,SortKeyPosition属性标识已排序的列和其排序的方向
在SortKeyPosition属性中,正表示升序,负表示降序,绝对值表示位置序号,位置从1开始,依次递增。
打开“Output Columns” 输出列列表,将UserID的SortKeyPosition属性设置为1,ProfileID的SortKeyPosition属性设置为-2。

参考文档:
Sort Data for the Merge and Merge Join Transformations
SSIS 剖析数据流之:连接和查找转换的更多相关文章
- SSIS 数据流的连接和查找转换
在SSIS的数据流组件中,SSIS引擎使用Merge Join组件和 Lookup组件实现TSQL语句中的inner join 和 outer join 功能,Lookup查找组件的功能更类似TSQL ...
- Informatica 常用组件Lookup之九 配置未连接的查找转换
在映射中,未连接的查找转换与管道是分开的.您可以使用 :LKP 引用限定符编写表达式以调用其它转换中的查找.未连接查找的常用用法包括: 测试表达式中某个查找的结果 基于查找结果过滤行 基于查找的结果将 ...
- Informatica 常用组件Lookup之二 已连接和未连接的查找
可以配置一个已连接的查找转换,以从映射管道中直接接收输入:您也可以配置一个未连接的查找转换,以从其它转换的表达式结果中接收输入. 已连接的查找 未连接的查找 直接从管道接收输入值. 从其它转换的 :L ...
- 《BI那点儿事》数据流转换——字词查找转换
字词查找转换将从转换输入列的文本中提取的字词与引用表中的字词进行匹配,然后计算出查找表中的字词在输入数据集中出现的次数,并将计数与引用表中的此字词一并写入转换输出的列中.此转换对于创建基于输入文本并带 ...
- 《BI那点儿事》数据流转换——查找转换
查找转换通过联接输入列中的数据和引用数据集中的列来执行查找.是完全匹配查找.在源表中查找与字表能关联的所有源表记录.准备数据.源表 T_QualMoisture_Middle_Detail字典表 T_ ...
- Informatica 常用组件Lookup之十 创建查找转换
在 Mapping Designer 中选择"转换-创建".选择查找转换.输入转换名称.查找转换的命名惯例是 LKP_TransformationName.单击"确定&q ...
- SSIS之数据流任务
数据流任务主要用于运行数据流以提取.转换.加载源数据.一个包中可以有多个数据流任务,也可以包含零个数据流任务.下面关系图显示含有一个数据流任务的包: 了解数据流任务后,我们就简要的学习一下如何创建数据 ...
- SSIS自定义数据流组件开发(血路)
由于特殊的原因(怎么特殊不解释),需要开发自定义数据流组件处理. 查了很多资料,用了不同的版本,发现各种各样的问题没有找到最终的解决方案. 遇到的问题如下: 用VS2015编译出来的插件,在SSDTB ...
- python中基本类型的连接组合和互相转换
本篇总结了一下字符串,列表,字典,元组的连接组合使用和类型的互相转换小例子,尤其列表中的extend()方法和字典中的 update方法非常的常用. 1.连接两个字符串 a = "hello ...
随机推荐
- Oracle EBS 新增 OAFM 个数
在 $INST_TOP/ora/10.1.3/opmn/conf/opmn.xml中 找到 <process-type id="oafm" module-id="O ...
- Oracle EBS INV 更新状态
使用API改变现有物料状态,改成如下:On-Hand, Subinventory, Locator, Lot & Serial.参数使用如下:H, O, S, Z, L.对应如下: 'H' - ...
- JList动态添加元素
JList动态添加元素 http://www.cnblogs.com/tianguook/archive/2012/01/31/2333992.html https://zhuanlan.zhih ...
- [IDEA_5] IDEA 集成 Scala
0. 说明 在 IDEA 中集成 Scala 1. IDEA 集成 Scala 1.1 安装 Scala 插件 Ctrl + Alt + S 进入设置 依次选中 Settings --> P ...
- 脱壳_01_虚拟机壳_VMP
写在前面的话: 上一篇文章中,带领大家一起分析了简单的压缩壳ASPACK,今天,就和大家一起来揭开VMP这道神秘的面纱: [花指令]:扰乱调试器的,并不执行: [混淆]:对原指令进行拆解或等价替换,会 ...
- MySQL报错:error1130
ERROR (HY000): Host 'ip-172-31-x-x.ec2.internal' is not allowed to connect to this MySQL server 分析,从 ...
- SHGetFileInfo 报错 异常 问题
查看代码是否使用了 ::CoInitializeEx(NULL, COINIT_MULTITHREADED); 如果是,换成在每个线程调用 ::CoInitialize(NULL); 真够蛋疼的,查了 ...
- H.__mro__) MRO- C3算法
- SQL Server:INFORMATION_SCHEMA.columns 与sys.columns 与 syscolumns对比
sys.columns视图 sys.columns是SQL Server从2005版本起引入的新的系统级视图.相关链接如下: Mapping SQL Server 2000 System Tables ...
- SDN2017 第四次实验作业
实验目的 1.使用图形化界面搭建拓扑如下并连接控制器 2.使用python脚本搭建拓扑如下并通过命令行连接控制器 3.使用任一种方法搭建拓扑连接控制器后下发流表 实验步骤 建立以下拓扑,并连接上ODL ...