SQL Server 分析函数和排名函数
分析函数基于分组,计算分组内数据的聚合值,经常会和窗口函数OVER()一起使用,使用分析函数可以很方便地计算同比和环比,获得中位数,获得分组的最大值和最小值。分析函数和聚合函数不同,不需要GROUP BY子句,对SELECT子句的结果集,通过OVER()子句分组。
使用以下脚本插入示例数据:
;with cte_data as
(
select 'Document Control' as Department,'Arifin' as LastName,17.78 as Rate
union all
select 'Document Control','Norred',16.82
union all
select 'Document Control','Kharatishvili',16.82
union all
select 'Document Control','Chai',10.25
union all
select 'Document Control','Berge',10.25
union all
select 'Information Services','Trenary',50.48
union all
select 'Information Services','Conroy',39.66
union all
select 'Information Services','Ajenstat',38.46
union all
select 'Information Services','Wilson',38.46
union all
select 'Information Services','Sharma',32.45
union all
select 'Information Services','Connelly',32.45
union all
select 'Information Services','Berg',27.40
union all
select 'Information Services','Meyyappan',27.40
union all
select 'Information Services','Bacon',27.40
union all
select 'Information Services','Bueno ',27.40
)
select Department
,LastName
,Rate
into #data
from cte_data
go
一,分析函数
分析函数通常和OVER()函数搭配使用,SQL Server中共有4类分析函数。
在OVER()函数中通常会对窗口内的数据进行排序,把有序数据从上向下看作是一个序列,对当前行而言,在序列上方的为后,在序列下方的为前。对当前组而言,第一行在组内的最上面,末尾行在组内的最下面。
注意:distinct子句的执行顺序是在分析函数之后。
1,CUME_DIST 和PERCENT_RANK
CUME_DIST 计算的逻辑是:小于等于当前值的行数/分组内总行数
PERCENT_RANK 计算的逻辑是:(分组内当前行的RANK值-1)/ (分组内总行数-1),排名值是RANK()函数排序的结果值。
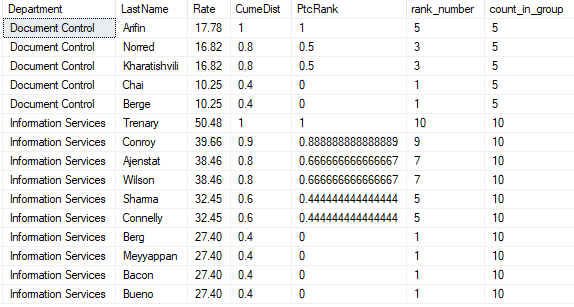
以下代码,用于计算累积分布和排名百分比:
select Department
,LastName
,Rate
,cume_dist() over(partition by Department order by Rate) as CumeDist
,percent_rank() over(partition by Department order by Rate) as PtcRank
,rank() over(partition by Department order by Rate asc) as rank_number
,count(0) over(partition by Department) as count_in_group
from #data
order by DepartMent
,Rate desc
2,PERCENTILE_CONT和PERCENTILE_DISC
PERCENTILE_CONT和PERCENTILE_DISC都是为了计算百分位的数值,比如计算在某个百分位时某个栏位的数值是多少。
PERCENTILE_CONT ( numeric_literal ) WITHIN GROUP ( ORDER BY order_by_expression [ ASC | DESC ] ) OVER ( [ <partition_by_clause> ] )
PERCENTILE_DISC ( numeric_literal ) WITHIN GROUP ( ORDER BY order_by_expression [ ASC | DESC ] ) OVER ( [ <partition_by_clause> ] )
这两个函数的区别是前者是连续型,后者是离散型。CONT代表continuous,连续值,DISC代表discrete,离散值。PERCENTILE_CONT是连续型,意味它考虑的是区间,所以值是绝对的中间值;而PERCENTILE_DISC是离散型,所以它更多考虑向上或者向下取舍,而不会考虑区间。
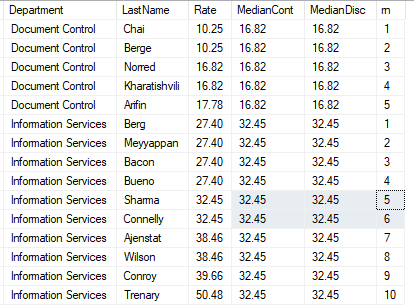
以下脚本用于获得分位数:
select Department
,LastName
,Rate
,PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY Rate) OVER (PARTITION BY Department) AS MedianCont
,PERCENTILE_DISC(0.5) WITHIN GROUP (ORDER BY Rate) OVER (PARTITION BY Department) AS MedianDisc
,row_number() over(partition by Department order by Rate) as rn
from #data
order by DepartMent
,Rate asc
3,LAG和LEAD
在一次查询中,对数据表进行排序,把已排序的数据从上向下看作是一个序列,对当前行而言,在序列上方的为后,在序列下方的为前。
在同一分组内,对于当前行,Lag()函数用于获取从当前行开始向后(或向上)计数的第N行,Lead()函数用于获取从当前行开始向前(或向下)计数的第N行。
LAG (scalar_expression [,offset] [,default])
OVER ( [ partition_by_clause ] order_by_clause )
LEAD ( scalar_expression [ ,offset ] , [ default ] )
OVER ( [ partition_by_clause ] order_by_clause )
参数注释:
- sclar_expression:标量表达式
- offset:默认值是1,必须是正整数,对于LAG()函数表示从当前行(current row)回退的行数,对于LEAD()表示从当前行向前进的行数。
- default :当offset超出分区范围时要返回的值。 如果未指定默认值,则返回NULL。 default可以是列,子查询或其他表达式,但必须跟sclar_expression类型兼容。
结果日期,这两个函数特别适合用于计算同比和环比。
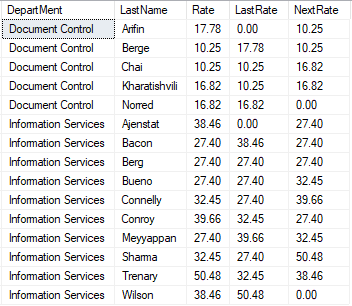
select DepartMent
,LastName
,Rate
,lag(Rate,1,0) over(partition by Department order by LastName) as LastRate
,lead(Rate,1,0) over(partition by Department order by LastName) as NextRate
from #data
order by Department
,LastName
按照DepartMent进行分组,对Document Control这一小组进行分析:
- 第一行,对于LastRate字段,向后不存在数据行,返回参数Default的值,字段NextRate的值是第二行的Rate字段的值。
- 第二行,LastRate是第一行的Rate字段的值,NextRate是第三行的Rate字段的值。对于中间行,依次类推。
- 最后一行,LastRate是倒数第二行的Rate字段的值,对于NextRate字段,由于最后一行向前不存在数据行,返回参数Default的值。
4,FIRST_VALUE和LAST_VALUE
获取分组内排在最末尾的行和排在第一位的行:
LAST_VALUE ( [scalar_expression ) OVER ( [ partition_by_clause ] order_by_clause rows_range_clause )
FIRST_VALUE ( [scalar_expression ] ) OVER ( [ partition_by_clause ] order_by_clause [ rows_range_clause ] )
二,排名函数
SQL Server的排名函数是对查询的结果进行排名和分组,TSQL共有4个排名函数,分别是:RANK、NTILE、DENSE_RANK和ROW_NUMBER,和OVER()函数搭配使用,按照特定的顺序排名。
1,ROW_NUMBER函数
ROW_NUMBER函数实际上是一个序列,每个分组内都会创建一个序列,序列从1开始,按照顺序依次 +1 递增。
ROW_NUMBER ( )
OVER ( [ PARTITION_BY_clause ] order_by_clause )
分组内序列的最大值就是该分组内的行的数目。
2,RANK函数
RANK函数用于排名时,不会返回连续的整数。RANK函数的语法是:在分组内,按照特定的顺序排名,序号从1依次递增,排名函数以tie为单位,每个tie中的所有行的排名是相同的,排名可能是不连续的。
RANK ( ) OVER ( [ partition_by_clause ] order_by_clause )
排名的算法是:
- step1:按照指定的分区字段分组,在每个分组内按照指定的字段排序。
- step2:在每个分组内,如果相邻的两行或多行相同在排序字段上的值相同,那么这些行称作一个tie,每个tie中的所有行都会获得相同的排名。
- step3:后面的排名会计算每个tie中的行数,RANK函数不总是返回连续的整数,例如,班级中,A,B分数都是100分,C的分数是90分,那么A和B的排名是1,C的排名是3。
3,DENSE_RANK
DENSE_RANK函数用于排名时,会返回连续的整数。每个tie占用一个排名,每个tie中的所有行的排名是相同的。排名值是连续的
DENSE_RANK ( ) OVER ( [ <partition_by_clause> ] < order_by_clause > )
排名的算法是:
- step1:按照指定的分区字段分组,在每个分组内按照指定的字段排序。
- step2:在每个分组内,如果相邻的两行或多行相同在排序字段上的值相同,那么这些行称作一个tie,每个tie中的所有行都会获得相同的排名。
- step3:后面的排名会计算每个tie中的行数,RANK函数总是返回连续的整数,例如,班级中,A,B分数都是100分,C的分数是90分,那么A和B的排名是1,C的排名是2。
4,NTILE
在每个分组中,NTILE按照指定的顺序,把数据行分为N个小组(tile),NTILE返回小组编号。在每个分组内,具有相同的小组编号的数据行,位于同一个小组。注意:小组的编号是按照行数,而不是按照列值。在同一分组内,存在两行的列值相同,而小组编号不同。
NTILE (integer_expression) OVER ( [ <partition_by_clause> ] < order_by_clause > )
如果分区中的行数不能被integer_expression整除,那么会导致小组相差一个成员:较大的小组按OVER子句指定的顺序位于较小的小组之前。 例如,如果把8行分为3个小组,前2个小组有3行,后一个小组有2行。
如果分区中的中行数能被integer_expression整除,那么每个小组具有相同的行数。
特别地,NTILE(4) 把一个分组分成4份,叫做Quartile。例如,以下脚本显示各个排名函数的执行结果:
select Department
,LastName
,Rate
,row_number() over(order by Rate) as [row number]
,rank() over(order by rate) as rate_rank
,dense_rank() over(order by rate) as rate_dense_rank
,ntile(4) over(order by rate) as quartile_by_rate
from #data

参考文档:
Analytic Functions (Transact-SQL)
Ranking Functions (Transact-SQL)
SQL Server 分析函数和排名函数的更多相关文章
- SQL Server 中的排名函数与使用场景
1.RowNumber() Over (oder by.....) 在需要对某个不连续ID的表进行排序时使用 2.ROW_NUMBER() over(PARTITION by ...... ord ...
- SQL Server 进制转换函数
一.背景 前段时间群里的朋友问了一个问题:“在查询时增加一个递增序列,如:0x00000001,即每一个都是36进位(0—9,A--Z),0x0000000Z后面将是0x00000010,生成一个像下 ...
- sql server 2012 自定义聚合函数(MAX_O3_8HOUR_ND) 计算最大的臭氧8小时滑动平均值
采用c#开发dll,并添加到sql server 中. 具体代码,可以用visual studio的向导生成模板. using System; using System.Collections; us ...
- ylb:SQL Server中的时间函数
ylbtech-SQL Server:SQL Server-SQL Server中的时间函数 SQL Server中的时间函数. 1,SQL Server中的时间函数 返回顶部 1. 当前系统日期 ...
- SQL Server中的DATEPART函数的使用
下面文章来自:http://blog.csdn.net/hello_world_wusu/article/details/4632049 定义和用法 DATEPART() 函数用于返回日期/时间的单独 ...
- SQL Server中的CLR编程——用.NET为SQL Server编写存储过程和函数
原文:SQL Server中的CLR编程--用.NET为SQL Server编写存储过程和函数 很早就知道可以用.NET为SQL Server2005及以上版本编写存储过程.触发器和存储过程的,不过之 ...
- 刷新SQL Server所有视图、函数、存储过程
刷新SQL Server所有视图.函数.存储过程 更多 sql 此脚本用于在删除或添加字段时刷新相关视图,并检查视图.函数.存储过程有效性. [SQL]代码 --视图.存储过程.函数名称 DE ...
- 刷新SQL Server所有视图、函数、存储过程 更多 sql 此脚本用于在删除或添加字段时刷新相关视图,并检查视图、函数、存储过程有效性。 [SQL]代码 --视图、存储过程、函数名称 DECLARE @NAME NVARCHAR(255); --局部游标 DECLARE @CUR CURSOR --自动修改未上状态为旷课 SET @CUR=CURSOR SCROLL DYNAMIC FO
刷新SQL Server所有视图.函数.存储过程 更多 sql 此脚本用于在删除或添加字段时刷新相关视图,并检查视图.函数.存储过程有效性. [SQL]代码 --视图.存储过程.函数名称 DE ...
- SQL Server ->> FIRST_VALUE和LAST_VALUE函数
两个都是SQL SERVER 2012引入的函数.用于返回在以分组和排序后取得最后一行的某个字段的值.很简单两个函数.ORDER BY字句是必须的,PARITION BY则是可选. 似乎没什么好说的. ...
随机推荐
- 简易付XP版本无法获取server.xml配置文件处理方案
博客地址:https://blog.csdn.net/zdw_wym/article/details/40892535 把它添加到C:/WINDOWS/Microsoft.NET/Framework/ ...
- java笔记----线程状态转换函数
注意:stop().suspend()和 resume()方法现在已经不提倡使用,这些方法在虚拟机中可能引起“死锁”现象.suspend()和 resume()方法的替代方法是 wait()和 sle ...
- [20190321]smem的显示缺陷.txt
[20190321]smem的显示缺陷.txt1.smem 加入-m参数显示存在缺陷,map的信息不全:# smem -tk -m -U oracle -P "oraclepeis|ora_ ...
- Sqlserver分区表
1. 分区表简介 分区表在逻辑上是一个表,而物理上是多个表.从用户角度来看,分区表和普通表是一样的.使用分区表的主要目的是为改善大型表以及具有多个访问模式的表的可伸缩性和可管理性. 分区表是把数据按设 ...
- django重定向
return HttpResponseRedirect('/index/')# 重定向返回url格式:http://127.0.0.1:8000/index/会去掉前期的所有路由重新写入/index/ ...
- 【公众号系列】SAP S/4 HANA 1809请查收
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[公众号系列]SAP S/4 HANA 1809 ...
- windows下安装mysql
windows 下安装mysql 1.先下载好 mysql5.7 版本的安装包,可以去官网自己下载,也可以从我的百度云分享 里面下载: 链接: https://pan.baidu.com/s/1VXk ...
- windows入侵
一, ping 用来检查网 络是否通畅或者网络连接速度的命令.作为一个生 活在网络上的管理员或者黑 客来说, ping 命令是第一个必须掌握的 DOS 命令,所利用的原理是这样的网络上的机器都有唯一确 ...
- Java序列化(含transient)
什么是序列化? 我们创建的对象只有在Java虚拟机保持运行时,才会存在于内存中.如果想要超出Java虚拟机的生命周期,就可以将对象序列化,将对象状态转换为字节序列,写入文件(或socket传输),后面 ...
- 02.Python网络爬虫第二弹《http和https协议》
一.HTTP协议 1.官方概念: HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文 ...