Python下Tesseract Ocr引擎及安装介绍
1、Tesseract介绍
tesseract 是一个google支持的开源ocr项目,其项目地址:https://github.com/tesseract-ocr/tesseract,目前最新的源码可以在这里下载。
实际使用tesseract ocr也有两种方式:1- 动态库方式 libtesseract 2 - 执行程序方式 tesseract.exe
由于本人也是python菜鸟一个,所以方式1暂时不会,只好采取方式2。
2、Tesseract安装包下载
Tesseract的release版本下载地址:https://github.com/tesseract-ocr/tesseract/wiki/Downloads,这里需要注意这一段话:
Currently, there is no official Windows installer for newer versions.
意思就是官方不提供最新版windows平台安装包,只有相对略老的3.02.02版本,其下载地址:https://sourceforge.net/projects/tesseract-ocr-alt/files/。
最新版3.03和3.05版本,都是三方维护和管理的安装包,有好几个发行机构,分别是:
3rd party Windows exe's/installer
binaries compiled by @egorpugin (ref issue # 209)https://www.dropbox.com/s/8t54mz39i58qslh/tesseract-3.05.00dev-win32-vc19.zip?dl=1
You have to install VC2015 x86 redist from microsoft.com in order to run them. Leptonica is built with all libs except for libjp2k.
- http://domasofan.spdns.eu/tesseract/
总结一下:
2、德国曼海姆大学发行的3.05版本下载地址,http://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-setup-3.05.00dev.exe
3、Simon Eigeldinger (@DomasoFan) 维护的另一个版本:http://3.onj.me/tesseract/,值得称道的是,这个网址里还有一个比较详细的说明。
以上版本如果在下载时发现无法下载,可以首先试试迅雷,其次,可能就需要翻墙了。
本人使用的是官方发布的3.02版本,也就是链接1.
3、Tesseract ocr使用说明
安装之后,默认目录C:\Program Files (x86)\Tesseract-OCR,你需要把这个路径放到你操作系统的path搜索路径中,否则后面使用起来会不方便。
在安装目录C:\Program Files (x86)\Tesseract-OCR下可以看到 tesseract.exe这个命令行执行程序。
tesseract语法如下:
例如:tesseract 1.png output-l eng -psm 7 ,表示采取单行文本方式,使用英语字库识别1.png这个图片文件,识别结果输出到当前目录output.txt文件中。
D:\python\lnypcg\test>tesseract
Usage:tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...] pagesegmode values are:
0 = Orientation and script detection (OSD) only.
1 = Automatic page segmentation with OSD.
2 = Automatic page segmentation, but no OSD, or OCR
3 = Fully automatic page segmentation, but no OSD. (Default)
4 = Assume a single column of text of variable sizes.
5 = Assume a single uniform block of vertically aligned text.
6 = Assume a single uniform block of text.
7 = Treat the image as a single text line. #-psm 7 表示用单行文本识别
8 = Treat the image as a single word.
9 = Treat the image as a single word in a circle.
10 = Treat the image as a single character.
-l lang and/or -psm pagesegmode must occur before anyconfigfile. #-l eng 代表使用英语识别 Single options:
-v --version: version info
--list-langs: list available languages for tesseract engine
4、Tesseract ocr使用实例
现在有一个经过灰度处理之后的验证码文件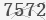 ,在命令行中调用tesseract.exe实现默认,并把识别出来的文本输出到output.txt文本文件中。
,在命令行中调用tesseract.exe实现默认,并把识别出来的文本输出到output.txt文本文件中。
(如何灰度处理,在python里可以使用PIL库,先挖个坑,下次写。)
D:\python\lnypcg\test>dir
驱动器 D 中的卷没有标签。
卷的序列号是 36D9-CDC7 D:\python\lnypcg\test 的目录 2016-06-02 23:28 <DIR> .
2016-06-02 23:28 <DIR> ..
2016-06-02 22:02 462 1.png
1 个文件 462 字节
2 个目录 25,733,357,568 可用字节 D:\python\lnypcg\test>tesseract 1.png output -l eng
Tesseract Open Source OCR Engine v3.02 with Leptonica D:\python\lnypcg\test>type output.txt
7572 D:\python\lnypcg\test>
总结,tesseract是一个挺不错的OCR引擎,目前的问题是最新的中文资料相对较少,过时、不准确的信息偏多,把这几天的琢磨的结果分享给大家,希望对大家有所帮助。
Python下Tesseract Ocr引擎及安装介绍的更多相关文章
- Tesseract Ocr引擎
Tesseract Ocr引擎 1.Tesseract介绍 tesseract 是一个google支持的开源ocr项目,其项目地址:https://github.com/tesseract-ocr/t ...
- 【整理】Linux下中文检索引擎coreseek4安装,以及PHP使用sphinx的三种方式(sphinxapi,sphinx的php扩展,SphinxSe作为mysql存储引擎)
一,软件准备 coreseek4.1 (包含coreseek测试版和mmseg最新版本,以及测试数据包[内置中文分词与搜索.单字切分.mysql数据源.python数据源.RT实时索引等测 ...
- c/c++语言实现tesseract ocr引擎编程实例
编译下面的程序操作系统必须在安装了tesseract库和leptonica库才可以 Basic example c++ code: #include <tesseract/baseapi.h&g ...
- linux系统CentOS6.5下tokudb数据库引擎的安装
tokuDB是一个关于mysql数据引擎的开源项目,官网对其特点的描述主要有三点: 1.高压缩比,官方宣称可以达到1:12. 2.高insert性能,官方称至少比innodb高9倍. 3.可以在线添加 ...
- python下以api形式调用tesseract识别图片验证码
一.背景 之前在博文中介绍在python中如何调用tesseract ocr引擎,当时主要介绍了shell模式,shell模式需要安装tesseract程序,并且效率相对略低. 今天介绍api形式的调 ...
- 神器XPath在Python下的使用
1.在python下使用xpath,需安装第三方库lxml 2.安装后,导入from lxml import etree selector=etree.HTML(html) Selector.xpat ...
- [PyImageSearch] Ubuntu16.04下针对OCR安装Tesseract
今天的博文是安装和使用光学字符识别(OCR)的Tesseract库的两部分系列的第一部分. 本系列的第一部分将着重于在您的机器上安装和配置Tesseract,然后使用tesseract命令将OCR应用 ...
- ubuntu下tesseract 4.0安装及参数使用
tesseract是一个开源的OCR引擎,最初是由惠普公司开发用来作为其平板扫描仪的OCR引擎,2005年惠普将其开源出来,之后google接手负责维护.目前稳定的版本是3.0.4.0版本加入了基 ...
- Tesseract OCR使用介绍
#Tesseract OCR使用介绍 ##目录[TOC] ##下载地址及介绍 官网介绍:http://code.google.com/p/tesseract-ocr/wiki/TrainingTess ...
随机推荐
- redis 从入门到遗忘
Key操作 keys * *: 通配任意多个字符 ?: 通配单个字符 []: 通配括号内的某1个字符 exists key 存在返回1,不存在返回0 type key rename oldkey ne ...
- yd的汇总
因为是我这只蒟蒻个人的汇总嘛,可能有些奇♂怪的东西或者不规范的语言出现啦,见谅见谅 搬了一些到知识汇总里,删了一些过时和无用的,少了好多=.= 1.STL_queue 经实践验证,!qs.empty( ...
- vue2.0获取自定义属性的值
最近在项目中使用了vue.js.在爬坑的路上遇到了很多问题.这里都会给记录下来,今天要说的是怎么获取自定义属性的值. HTML <!DOCTYPE html> <html> & ...
- (转)MySQL中In与Exists的区别
背景:总结mysql相关的知识点. 如果A表有n条记录,那么exists查询就是将这n条记录逐条取出,然后判断n遍exists条件. select * from user where exists s ...
- POJ3734Blocks(递推+矩阵快速幂)
题目链接:http://poj.org/problem?id=3734 题意:给出n个排成一列的方块,用红.蓝.绿.黄四种颜色给它们染色,求染成红.绿的方块个数同时为偶数的方案数模10007的值. 题 ...
- plink提取指定样本的数据(keep函数)
提取样本见命令行: plink --bfile file --noweb --keep sampleID.txt --recode --make-bed --out sample 其中,sampleI ...
- 使用vcftools或者gcta计算群体间固定指数(Fixation index,FST)
下列所用到的数据均为千人基因组数据库 1.通过vcftools计算FST 命令行如下: ./vcftools --vcf input_data.vcf --weir-fst-pop populatio ...
- Unity 摄像机跟随
方式一:将摄像机直接拖到游戏对象的下面: 方式二:脚本实现 using System.Collections; using System.Collections.Generic; using Unit ...
- noi.openjudge 1.12.6
http://noi.openjudge.cn/ch0112/06/ 总时间限制: 2000ms 内存限制: 65536kB 描述 传说很遥远的藏宝楼顶层藏着诱人的宝藏.小明历尽千辛万苦终于找到传 ...
- Go数据类型和变量
一:Go数据类型 1.1 Go语言按照分类有以下几种数据类型 布尔型 布尔型的是一个常量true或者false 数字类型 整型int和浮点型 float32, float64 字符串类型 字符串就是一 ...