Node爬虫之初体验
记得之前就听说过爬虫,个人初步理解就是从网页中抓取一些有用的数据,存储到本地,今天就当是小牛试刀,拿来溜溜......
实现需求: 抓取课程数据,输入url后并在浏览器端以一定的数据格式显示出来(如下图所示)
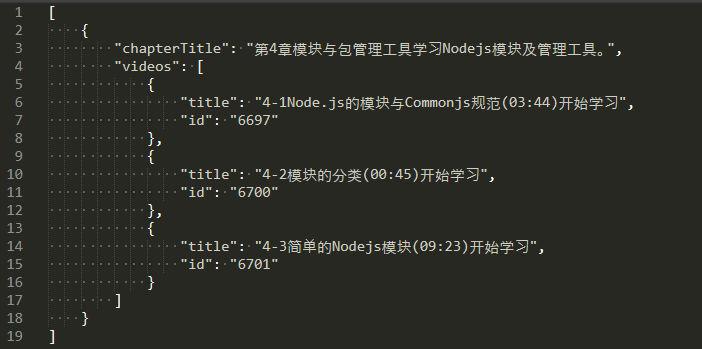
实现需求需用到的Node库介绍
cheerio(https://github.com/cheeriojs/cheerio ) 可以理解成一个 Node.js 版的 jquery,用来从网页中以 css selector 取数据,使用方式跟 jquery 一样一样的。
superagent(http://visionmedia.github.io/superagent/ ) 是个轻量的的 http 方面的库,是nodejs里一个非常方便的客户端请求代理模块,当我们需要进行 get 、 post 、 head 等网络请求时。
express(http://www.expressjs.com.cn/starter/) 是一个基于 Node.js 平台的极简、灵活的 web 应用开发框架,路由、express生成器、静态文件等。
实现需求源代码如下
package.json
npm init生成package.json配置文件
devDependencies、dependencies 依赖组件
{
"name": "package.json",
"version": "1.0.0",
"description": "",
"main": "app.js",
"dependencies": {
"cheerio": "^0.22.0"
},
"devDependencies": {
"express": "^4.15.2",
"superagent": "^3.5.0"
},
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "Avenstar",
"license": "ISC"
}
crawler.js
var express = require('express'),
app = express(),//基于WEB平台的开发框架
superagent = require("superagent"),//处理服务端/客户端的http请求
cheerio=require('cheerio');//一个 Node.js 版的 jquery,用来从网页中以 css selector 取数据,使用方式跟 jquery 一样
var pathUrl='http://www.imooc.com/learn/348';
/*=========================================================================
|抓取data数据结构如下
| var courseData = [{
| chapterTitle:'',
| videos:[{
| title:'',
| id:''
| }]
| }]
*==========================================================================*/
function printCourseInfo(courseData){
courseData.forEach(function(item){
var chapterTitle=item.chapterTitle;
console.log(chapterTitle+'\n');
item.videos.forEach(function(video){
console.log(' 【'+video.id+'】'+video.title+'\n');
})
});
}
/*==========================================================================
| 分析从网页里抓取到的数据
==========================================================================*/
function filterChapter(html){
var courseData=[];
var $=cheerio.load(html);
var chapters=$('.chapter');
chapters.each(function(item){
var chapter=$(this);
var chapterTitle=chapter.find('strong').text().replace(/(\s*)/g,''); //找到章节标题
var videos=chapter.find('.video').children('li');
var chapterData={
chapterTitle:chapterTitle,
videos:[]
};
//videos
videos.each(function(item){
var $that = $(this),
video=$that.find('.J-media-item'),
title=video.text().replace(/(\s*)/g,'');
id=video.attr('href').split('/video')[1].replace(/(\s*)/g,'').replace('/','');
chapterData.videos.push({
title:title,
id:id
})
})
courseData.push(chapterData);
});
return courseData;
}
/*==========================================================================
| GET method route
===========================================================================*/
app.get('/', function(request, respones){
//处理服务端/客户端的http请求
superagent.get(pathUrl).end(function(error, sres){
//error
if(error){
return next(err);
}
//抓取https网址html
var html = sres.text;
var courseData=filterChapter(html);
//打印
printCourseInfo(courseData);
//respones
respones.send((courseData));
})
})
/*==========================================================================
| listening at port
===========================================================================*/
app.listen(9090, function(){
console.log('app is listening at port 9090');
});
资料参考
http://www.imooc.com/video/7965
http://www.cnblogs.com/coco1s/p/4954063.html
https://github.com/alsotang/node-lessons
Node爬虫之初体验的更多相关文章
- node.js + express 初体验【hello world】
[node.js] 一个神奇的XX 呵呵 :) 不知道怎么形容他才好! [express] 是node.js 开发web应用程序的框架 开发环境:XP 大家共同进步吧 :) 一:前期准备: 1:下载 ...
- Node.js入门初体验
今天有一个类似网络爬虫的需求,本来打算用我还算熟悉的asp或者asp.NET来做这个事情,但是写了这么长时间js,asp的语法实在不喜欢,VS又早被我卸掉了,思来想去打算用一下最近比较火的Node.j ...
- node+express+mongodb初体验
从去年11月份到现在,一直想去学习nodejs,在这段时间体验了gulp.grunt.yeomen,fis,但是对于nodejs深入的去学习,去开发项目总是断断续续. 今天花了一天的时间,去了解整理整 ...
- Node.js 安装 初体验(1)
1.安装nodejs http://nodejs.org/download/ 自动根据系统下载自己的版本node.js 2.环境变量 windows 安装,不需要配置环境变量 mac安装后,会提 ...
- 【Node.js】初体验之安装和HelloWorld
听说Node.js是个蛮吊的东东.中午休息时间有限,暂时看了下知道怎么安装和初步使用了. 1.安装: 到Node.js官网下载就可以了,才5M多点,双击后按步骤安装就可以了. 2."Hell ...
- Node.js 的初体验
例子1: 1.首先第一步 :要 下载 node.js. 官网 上可以下载 下载完后,是这个玩意. 2. 打开 node.js ,然后输入 // 引入http模块 var http = require( ...
- 【Python3爬虫】爬取美女图新姿势--Redis分布式爬虫初体验
一.写在前面 之前写的爬虫都是单机爬虫,还没有尝试过分布式爬虫,这次就是一个分布式爬虫的初体验.所谓分布式爬虫,就是要用多台电脑同时爬取数据,相比于单机爬虫,分布式爬虫的爬取速度更快,也能更好地应对I ...
- 【Python3爬虫】学习分布式爬虫第一步--Redis分布式爬虫初体验
一.写在前面 之前写的爬虫都是单机爬虫,还没有尝试过分布式爬虫,这次就是一个分布式爬虫的初体验.所谓分布式爬虫,就是要用多台电脑同时爬取数据,相比于单机爬虫,分布式爬虫的爬取速度更快,也能更好地应对I ...
- Node.js 网页瘸腿爬虫初体验
延续上一篇,想把自己博客的文档标题利用Node.js的request全提取出来,于是有了下面的初哥爬虫,水平有限,这只爬虫目前还有点瘸腿,请看官你指正了. // 内置http模块,提供了http服务器 ...
随机推荐
- Python字典小结
字典(dict)结构是Python中常用的数据结构,笔者结合自己的实际使用经验,对字典方面的相关知识做个小结,希望能对读者一些启发~ 创建字典 常见的字典创建方法就是先建立一个空字典,然后逐一 ...
- [android] 短信的广播接收者
比较重要的一个广播事件,短信 界面布局,比如播放视频,默认是横屏全屏的,清单文件中进行设置, 在<activity/>节点设置屏幕朝向属性,android:screenOrientatio ...
- linux内核里的字符串转换 ,链表操作常用函数(转)
1.对双向链表的具体操作如下: list_add ———向链表添加一个条目 list_add_tail ———添加一个条目到链表尾部 __list_del_entry ———从链表中删除相应的条目 l ...
- JavaWeb学习日记----XML基础
1.XML基础: XML全称为eXtensible Markup Language;即可扩展标记型语言,同HTML一样使用标签来操作.它的可扩展性体现在标签可以由自己定义,可以是中文标签. XML用途 ...
- 浅谈spring中AOP以及spring中AOP的注解方式
AOP(Aspect Oriented Programming):AOP的专业术语是"面向切面编程" 什么是面向切面编程,我的理解就是:在不修改源代码的情况下增强功能.好了,下面在 ...
- 快速排序 and 拉格朗日插值查找
private static void QuictSort(int[] zu, int left, int right) { if (left < right) { ; ; ]; while ( ...
- 我是这样搞懂一个神奇的BUG
摘要: 通过分析用户的行为,才想得到为什么会出现这种情况! 前两天在BearyChat收到这样的一个报警消息: 409 ?Conflict ? 平时很少遇到这样的错误,貌似很严重的样子,吓得我赶紧查看 ...
- MySQL添加新用户、为用户创建数据库、为新用户分配权限
登录MySQL [root@VM_0_2_33_centos /]#mysql -u root -p 添加新用户 允许本地 IP 访问 localhost, 127.0.0.1 mysql>'; ...
- PHP7.27: pdf
http://www.fpdf.org/ https://github.com/Setasign/FPDF https://www.ntaso.com/fpdf-and-chinese-charact ...
- CSS网页中导入特殊字体@font-face属性详解
@font-face是CSS3中的一个模块,他主要是把自己定义的Web字体嵌入到你的网页中. 语法规则 首先我们一起来看看@font-face的语法规则: @font-face { font-fami ...