如何解析SIP报文
SIP协议是一个文本协议,比如下面是话机注册的首次REGISTER请求:
REGISTER sip:10.32.26.25:5070;transport=tcp SIP/2.0
Via: SIP/2.0/TCP 10.32.26.25:51696;rport;branch=z9hG4bKPj8d4db68b24754f539dbf3b563a44fe55;alias
Max-Forwards: 70
From: jimmy<sip:1000@10.32.26.25>;tag=89aefb1f3fc0413283a453eda5407f60
To: <sip:1000@10.32.26.25>
Call-ID: 1e7af0e67a5044658fc7f6716d329642
CSeq: 36850 REGISTER
User-Agent: MicroSIP/3.20.3
Supported: outbound, path
Contact: <sip:1000@10.32.26.25:51696;transport=TCP;ob>;reg-id=1;+sip.instance="<urn:uuid:00000000-0000-0000-0000-000011058e7e>"
Expires: 300
Allow: PRACK, INVITE, ACK, BYE, CANCEL, UPDATE, INFO, SUBSCRIBE, NOTIFY, REFER, MESSAGE, OPTIONS
Content-Length: 0
技术上讲,完全可以逐行按String解析,白手起家,拆解出其中的内容,但是这样做一来有些原始,二来也未必高效,幸好社区里已经类似的开源项目:pkts ,借助这个开源项目,可以很方便的把上述内容快速解析出来,示例代码如下:
先添加pom依赖(目前最新是3.0.11-SNAPSHOT)
<dependency>
<groupId>io.pkts</groupId>
<artifactId>pkts-sip</artifactId>
<version>3.0.11-SNAPSHOT</version>
</dependency>
然后就可以解析了:
@Test
public void testParseRegister() throws IOException {
StringBuilder register = new StringBuilder("REGISTER sip:10.32.26.25:5070;transport=tcp SIP/2.0\r\n" +
"Via: SIP/2.0/TCP 10.32.26.25:51696;rport;branch=z9hG4bKPj8d4db68b24754f539dbf3b563a44fe55;alias\r\n" +
"Max-Forwards: 70\r\n" +
"From: <sip:1000@10.32.26.25>;tag=89aefb1f3fc0413283a453eda5407f60\r\n" +
"To: jimmy<sip:1000@10.32.26.25>\r\n" +
"Call-ID: 1e7af0e67a5044658fc7f6716d329642\r\n" +
"CSeq: 36850 REGISTER\r\n" +
"User-Agent: MicroSIP/3.20.3\r\n" +
"Supported: outbound, path\r\n" +
"Contact: <sip:1000@10.32.26.25:51696;transport=TCP;ob>;reg-id=1;+sip.instance=\"<urn:uuid:00000000-0000-0000-0000-000011058e7e>\"\r\n" +
"Expires: 300\r\n" +
"Allow: PRACK, INVITE, ACK, BYE, CANCEL, UPDATE, INFO, SUBSCRIBE, NOTIFY, REFER, MESSAGE, OPTIONS\r\n" +
"Content-Length: 0\r\n"); SipMessage msgMessage = SipParser.frame(Buffers.wrap(register.toString())); if (msgMessage.isRegisterRequest()) {
System.out.println("This is a REGISTER request");
} Buffer method = msgMessage.getMethod();
System.out.println("方法:" + method + "\n");
Buffer initialLine = msgMessage.getInitialLine();
System.out.println("第一行:" + initialLine + "\n"); List<ViaHeader> viaHeaders = msgMessage.getViaHeaders();
System.out.println("via:");
for (ViaHeader viaHeader : viaHeaders) {
System.out.println("host:" + viaHeader.getHost() + ",branch:" + viaHeader.getBranch() + ",alias:" + viaHeader.getParameter("alias"));
} MaxForwardsHeader maxForwards = msgMessage.getMaxForwards();
System.out.println("\nmaxForwards:" + maxForwards.getMaxForwards()); FromHeader fromHeader = msgMessage.getFromHeader();
System.out.println("\nfrom-tag:" + fromHeader.getTag()); ToHeader toHeader = msgMessage.getToHeader();
System.out.println("\nto:" + toHeader.getAddress().getDisplayName()); CallIdHeader callIDHeader = msgMessage.getCallIDHeader();
System.out.println("\ncallId:" + callIDHeader.getCallId()); CSeqHeader cSeqHeader = msgMessage.getCSeqHeader();
System.out.println("\ncSeq:" + cSeqHeader.getSeqNumber()); Optional<SipHeader> userAgentHeader = msgMessage.getHeader("User-Agent");
System.out.println("\nuserAgent value:" + userAgentHeader.get().getValue()); Optional<SipHeader> supported = msgMessage.getHeader("Supported");
System.out.println("\nsupported name:" + supported.get().getName()); ContactHeader contactHeader = msgMessage.getContactHeader();
System.out.println("\ncontact reg-id:" + contactHeader.getParameter("reg-id")); ExpiresHeader expiresHeader = msgMessage.getExpiresHeader();
System.out.println("\nexpires:" + expiresHeader.getExpires()); Optional<SipHeader> allowHeader = msgMessage.getHeader("Allow");
System.out.println("\nallow:" + allowHeader.get().getValue()); int contentLength = msgMessage.getContentLength();
System.out.println("\ncontentLength:" + contentLength); }
输出如下:
This is a REGISTER request
方法:REGISTER 第一行:REGISTER sip:10.32.26.25:5070;transport=tcp SIP/2.0 via:
host:10.32.26.25,branch:z9hG4bKPj8d4db68b24754f539dbf3b563a44fe55,alias:null maxForwards:70 from-tag:89aefb1f3fc0413283a453eda5407f60 to:jimmy callId:1e7af0e67a5044658fc7f6716d329642 cSeq:36850 userAgent value:MicroSIP/3.20.3 supported name:Supported contact reg-id:1 expires:300 allow:PRACK, INVITE, ACK, BYE, CANCEL, UPDATE, INFO, SUBSCRIBE, NOTIFY, REFER, MESSAGE, OPTIONS contentLength:0
pkts-sip的解析非常高效,其主要设计思路借鉴了netty的buffer,自定义类似的buffer结构,内部有 readerIndex、writerIndex、markedReaderIndex、lowerBoundary、upperBoundary几个标识,可以快速读取或写入。
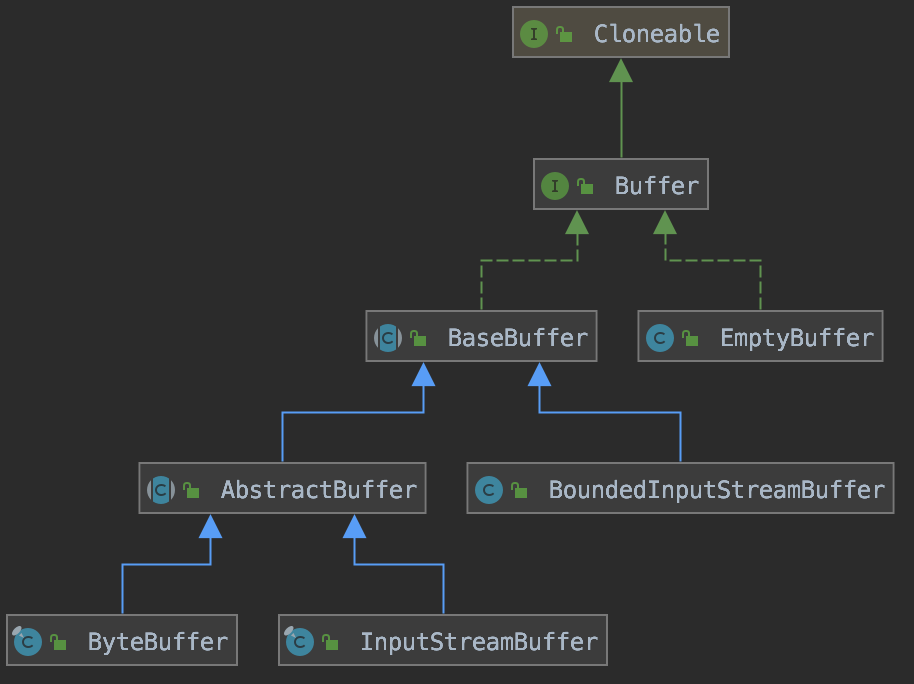
最常用的ByteBuffer内部数据存储于byte[]数组,值类型的变量直接在堆外内存区分配,无需JVM来GC。
SIP中常见的各种Header解析,pkts-sip已经做了实现,类图如下:
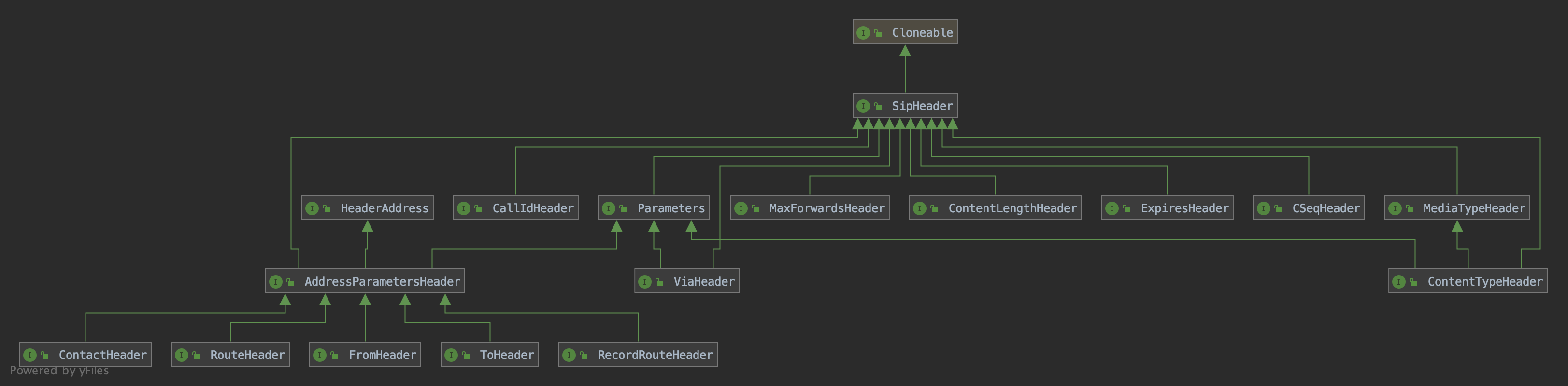
一个完整的SIP报文,正如最开始的解析示例代码,最终会被解析成SipMessage,根据该报文是Request还是Response,又派生出2个子类:

SipMessage中的核心部分,就是各种SIpHeader实例。
除了解析,pkts-sip还可以组装各种SIP报文,仍然以开头这段REGISTER为例,如果服务端收到这个注册请求,可以方便的组装Response进行回应:
@Test
public void testBuildRegisterResponse() throws IOException {
StringBuilder register = new StringBuilder("REGISTER sip:10.32.26.25:5070;transport=tcp SIP/2.0\r\n" +
"Via: SIP/2.0/TCP 10.32.26.25:51696;rport;branch=z9hG4bKPj8d4db68b24754f539dbf3b563a44fe55;alias\r\n" +
"Max-Forwards: 70\r\n" +
"From: <sip:1000@10.32.26.25>;tag=89aefb1f3fc0413283a453eda5407f60\r\n" +
"To: jimmy<sip:1000@10.32.26.25>\r\n" +
"Call-ID: 1e7af0e67a5044658fc7f6716d329642\r\n" +
"CSeq: 36850 REGISTER\r\n" +
"User-Agent: MicroSIP/3.20.3\r\n" +
"Supported: outbound, path\r\n" +
"Contact: <sip:1000@10.32.26.25:51696;transport=TCP;ob>;reg-id=1;+sip.instance=\"<urn:uuid:00000000-0000-0000-0000-000011058e7e>\"\r\n" +
"Expires: 300\r\n" +
"Allow: PRACK, INVITE, ACK, BYE, CANCEL, UPDATE, INFO, SUBSCRIBE, NOTIFY, REFER, MESSAGE, OPTIONS\r\n" +
"Content-Length: 0\r\n");
SipMessage msgMessage = SipParser.frame(Buffers.wrap(register.toString())); SipResponse sipResponse = msgMessage.createResponse(401)
.withHeader(SipHeader.create("User-Agent", "FreeSWITCH-mod_sofia/1.6.18+git~20170612T211449Z~6e79667c0a~64bit"))
.withHeader(SipHeader.create("Allow", "INVITE, ACK, BYE, CANCEL, OPTIONS, MESSAGE, INFO, UPDATE, REGISTER, REFER, NOTIFY, PUBLISH, SUBSCRIBE"))
.withHeader(SipHeader.create("Supported", "timer, path, replaces"))
.withHeader(SipHeader.create("WWW-Authenticate", "Digest realm=\"10.32.26.25\", nonce=\"bee3366b-cf59-476e-bc5e-334e0d65b386\", algorithm=MD5, qop=\"auth\""))
.withHeader(new ContentLengthHeader.Builder(0).build())
.build(); System.out.println(sipResponse); }
输出如下:
SIP/2.0 401 Unauthorized
Call-ID: 1e7af0e67a5044658fc7f6716d329642
CSeq: 36850 REGISTER
WWW-Authenticate: Digest realm="10.32.26.25", nonce="bee3366b-cf59-476e-bc5e-334e0d65b386", algorithm=MD5, qop="auth"
User-Agent: FreeSWITCH-mod_sofia/1.6.18+git~20170612T211449Z~6e79667c0a~64bit
To: jimmy<sip:1000@10.32.26.25>
From: <sip:1000@10.32.26.25>;tag=89aefb1f3fc0413283a453eda5407f60
Content-Length: 0
Supported: timer, path, replaces
Via: SIP/2.0/TCP 10.32.26.25:51696;rport;branch=z9hG4bKPj8d4db68b24754f539dbf3b563a44fe55;alias
Allow: INVITE, ACK, BYE, CANCEL, OPTIONS, MESSAGE, INFO, UPDATE, REGISTER, REFER, NOTIFY, PUBLISH, SUBSCRIBE
可能有细心的同学发现了,最终输出的报文,每行的出现顺序好象有点怪,比如Content-Length:0,是在最后添加进去的,但却是在中间出现。可以看下io.pkts.packet.sip.impl.SipMessageBuilder#build的源码:

597行这里,finalHeaders是一个HashMap,众所周知HashMap是不能保证顺序的,对顺序十分在意的同学,可以换成LinkedHashMap,另外从代码可以看出,viaHeaders是放在常规Headers之后组装的,一般我们习惯于把Via放在最开始,大家可以把这2段代码的位置互换一下。
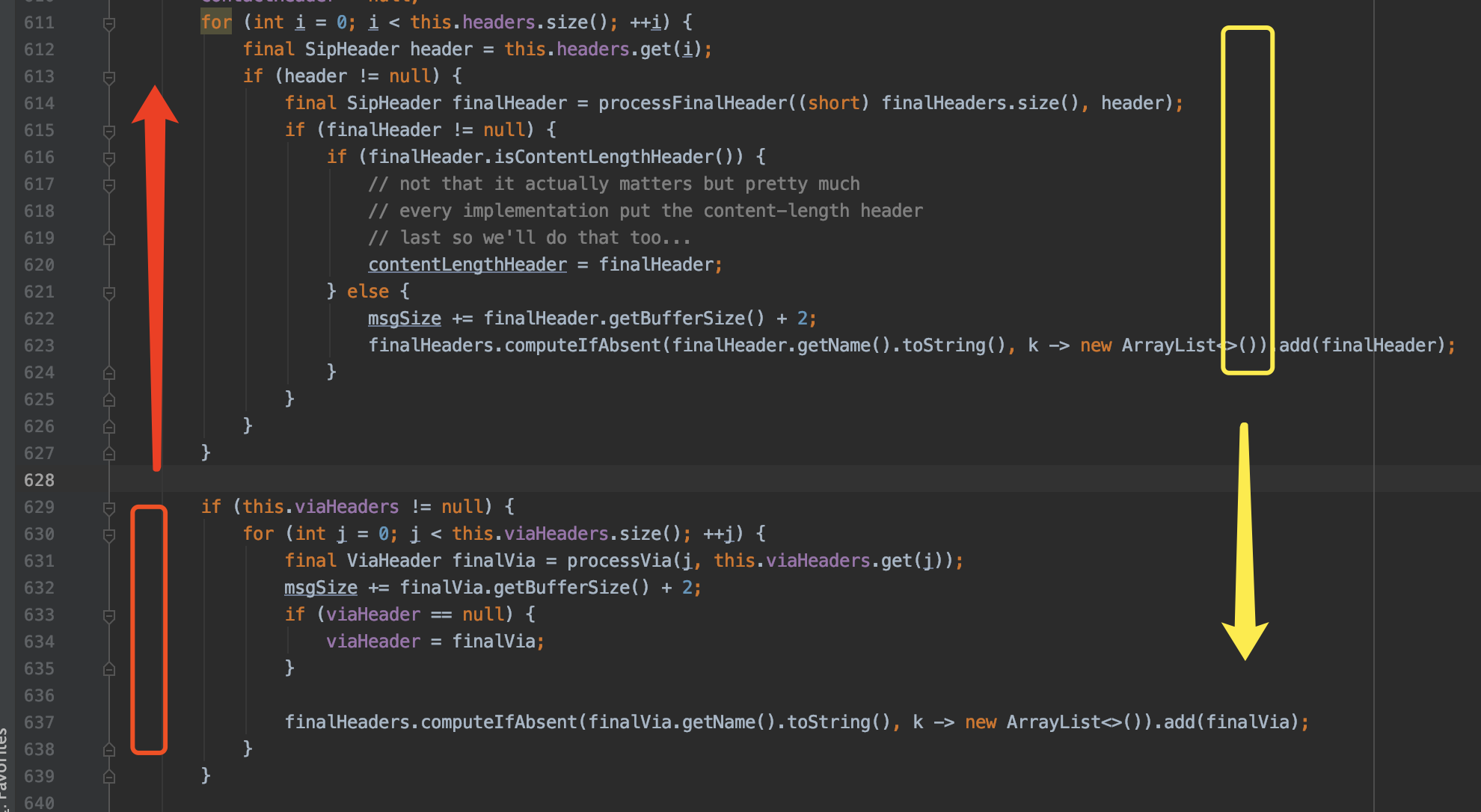
改完之后,再跑一下代码:
SIP/2.0 401 Unauthorized
Via: SIP/2.0/TCP 10.32.26.25:51696;rport;branch=z9hG4bKPj8d4db68b24754f539dbf3b563a44fe55;alias
From: <sip:1000@10.32.26.25>;tag=89aefb1f3fc0413283a453eda5407f60
To: jimmy<sip:1000@10.32.26.25>
CSeq: 36850 REGISTER
Call-ID: 1e7af0e67a5044658fc7f6716d329642
User-Agent: FreeSWITCH-mod_sofia/1.6.18+git~20170612T211449Z~6e79667c0a~64bit
Allow: INVITE, ACK, BYE, CANCEL, OPTIONS, MESSAGE, INFO, UPDATE, REGISTER, REFER, NOTIFY, PUBLISH, SUBSCRIBE
Supported: timer, path, replaces
WWW-Authenticate: Digest realm="10.32.26.25", nonce="bee3366b-cf59-476e-bc5e-334e0d65b386", algorithm=MD5, qop="auth"
Content-Length: 0
看上去顺眼多了,此外从源代码可以看到,ptks-sip在构造各种Header时,大量使用了Builder设计模式(比如下图中的FromHeader.Builder),可以方便的用withXXX(...),得到一个XXXBuilder实例,最后调用build()方法生成想要的XXXHeader实例。

最后来谈下如何扩展ptks未支持的Header,一般情况下,如果ptks不支持的Header,比如:
WWW-Authenticate: Digest realm="10.32.26.25", nonce="bee3366b-cf59-476e-bc5e-334e0d65b386", algorithm=MD5, qop="auth"
解析后,会生成默认的SipHeaderImpl实例列表,参考下图:

这样在使用时,并不方便,最好是希望能看FromHeader类似,只生成1个特定的WWWAuthenticateHeader实例,并且能类似getRealm()、getNonce()...得到相关的属性值。ptks-sip的readme里,告诉了大家扩展的步骤,我把主要部分列了下:
1、先定义一个XXXHeader的接口,比如:WWWAuthenticateHeader
2、XXXHeader接口里,实现static frame()方法(注:jdk 1.8开始,接口可以添加方法实现)
3、XXXHeader接口里,定义copy()方法
4、SipHeader接口中添加isXXX()以及toXXX()方法
5、XXXHeader接口里,定义ensure()方法,并返回this
6、实现XXXHeader,定义一个XXXHeaderImpl类,核心的解析工作,就放在这个类的frame方法中完成
7、SipParser类中,添加XXXHeader的注册信息
8、单元测试
按这个步骤,先来定义一个WWWAuthenticateHeader
package io.pkts.packet.sip.header; import io.pkts.buffer.Buffer;
import io.pkts.buffer.Buffers;
import io.pkts.packet.sip.SipParseException;
import io.pkts.packet.sip.header.impl.WWWAuthenticateHeaderImpl; public interface WWWAuthenticateHeader extends SipHeader { Buffer NAME = Buffers.wrap("WWW-Authenticate"); Buffer getRealm(); Buffer getNonce(); Buffer getAlgorithm(); Buffer getQop(); static WWWAuthenticateHeader frame(final Buffer buffer) throws SipParseException {
try {
return new WWWAuthenticateHeader.Builder(buffer).build();
} catch (final Exception e) {
throw new SipParseException(0, "Unable to frame the WWWAuthenticate header due to IOException", e);
}
} @Override
default WWWAuthenticateHeader toWWWAuthenticateHeader() {
return this;
} class Builder implements SipHeader.Builder<WWWAuthenticateHeader> {
private Buffer value; private Buffer realm;
private Buffer nonce;
private Buffer algorithm;
private Buffer qop; public Builder() { } public Builder(Buffer value) {
this.value = value;
} @Override
public WWWAuthenticateHeader.Builder withValue(Buffer value) {
this.value = value;
return this;
} public WWWAuthenticateHeader.Builder withRealm(Buffer realm) {
this.realm = realm;
return this;
} public WWWAuthenticateHeader.Builder withNonce(Buffer nonce) {
this.nonce = nonce;
return this;
} public WWWAuthenticateHeader.Builder withAlgorithm(Buffer algorithm) {
this.algorithm = algorithm;
return this;
} public WWWAuthenticateHeader.Builder withQop(Buffer qop) {
this.qop = qop;
return this;
} @Override
public WWWAuthenticateHeader build() throws SipParseException {
if (value == null &&
(this.realm == null && this.nonce == null)) {
throw new SipParseException("You must specify the [value] or [realm/nonce] of the WWWAuthenticate-Header");
} if (this.value != null) {
return new WWWAuthenticateHeaderImpl(value);
} else {
return new WWWAuthenticateHeaderImpl(realm, nonce, algorithm, qop);
}
}
} }
SipHeader里添加
default boolean isWWWAuthenticateHeader() {
//WWW-Authenticate
final Buffer m = getName();
try {
if (m.getReadableBytes() == 16) {
return (m.getByte(0) == 'W' || m.getByte(0) == 'w') &&
(m.getByte(1) == 'W' || m.getByte(1) == 'w') &&
(m.getByte(2) == 'W' || m.getByte(2) == 'w') &&
m.getByte(3) == '-' &&
(m.getByte(4) == 'A' || m.getByte(4) == 'a') &&
(m.getByte(5) == 'U' || m.getByte(5) == 'u') &&
(m.getByte(6) == 'T' || m.getByte(6) == 't') &&
(m.getByte(7) == 'H' || m.getByte(7) == 'h') &&
(m.getByte(8) == 'E' || m.getByte(8) == 'e') &&
(m.getByte(9) == 'N' || m.getByte(9) == 'n') &&
(m.getByte(10) == 'T' || m.getByte(10) == 't') &&
(m.getByte(11) == 'I' || m.getByte(11) == 'i') &&
(m.getByte(12) == 'C' || m.getByte(12) == 'c') &&
(m.getByte(13) == 'A' || m.getByte(13) == 'a') &&
(m.getByte(14) == 'T' || m.getByte(14) == 't') &&
(m.getByte(15) == 'E' || m.getByte(15) == 'e');
}
} catch (final IOException e) {
throw new SipParseException(0, UNABLE_TO_PARSE_OUT_THE_HEADER_NAME_DUE_TO_UNDERLYING_IO_EXCEPTION, e);
}
return false;
}
default WWWAuthenticateHeader toWWWAuthenticateHeader() {
throw new ClassCastException(CANNOT_CAST_HEADER_OF_TYPE + getClass().getName()
+ " to type " + WWWAuthenticateHeader.class.getName());
}
然后再来WWWAuthenticateHeaderImpl
package io.pkts.packet.sip.header.impl; import io.pkts.buffer.Buffer;
import io.pkts.buffer.Buffers;
import io.pkts.packet.sip.SipParseException;
import io.pkts.packet.sip.header.WWWAuthenticateHeader;
import io.pkts.packet.sip.impl.SipParser; import java.util.LinkedHashMap;
import java.util.Map; public class WWWAuthenticateHeaderImpl extends SipHeaderImpl implements WWWAuthenticateHeader { private Map<Buffer, Buffer> paramMap = new LinkedHashMap<>(); private Buffer realm;
private Buffer nonce;
private Buffer algorithm;
private Buffer qop; /**
* @param value
*/
public WWWAuthenticateHeaderImpl(Buffer value) {
super(WWWAuthenticateHeader.NAME, value); Buffer original = value.clone();
Buffer params = null;
if (original.hasReadableBytes()) {
params = original.slice("Digest ".length(), original.getUpperBoundary());
} final byte[] VALUE_END_1 = Buffers.wrap("\", ").getArray();
final byte[] VALUE_END_2 = Buffers.wrap(", ").getArray(); //WWW-Authenticate: Digest realm="10.32.26.25",
// nonce="bee3366b-cf59-476e-bc5e-334e0d65b386",
// algorithm=MD5,
// qop="auth" try {
// 思路:
// 1 遇到[=]号是key结束,遇到[,]或[", ]或[\r\n]是value结束
// 2 每次遇"="或”,”标识lastMarkIndex
int lastMarkIndex = params.getReaderIndex();
boolean inKey = true;
Buffer latestKey = Buffers.EMPTY_BUFFER, latestValue;
while (params.hasReadableBytes() && params.getReaderIndex() <= params.getUpperBoundary()) {
if (inKey && SipParser.isNext(params, SipParser.EQ)) {
//遇到[=]认为key结束
latestKey = params.slice(lastMarkIndex, params.getReaderIndex());
params.setReaderIndex(params.getReaderIndex() + 1);
if (SipParser.isNext(params, SipParser.DQUOT)) {
//跳过[="]等号后的第1个双引号
params.setReaderIndex(params.getReaderIndex() + 1);
inKey = false;
}
lastMarkIndex = params.getReaderIndex();
} else if (params.getReadableBytes() == 1 ||
SipParser.isNext(params, VALUE_END_1) ||
SipParser.isNext(params, VALUE_END_2)) {
//遇到[", ]或[, ]视为value结束
if (params.getReadableBytes() == 1 && params.peekByte() != SipParser.DQUOT) {
latestValue = params.slice(lastMarkIndex, params.getReaderIndex() + 1);
} else {
latestValue = params.slice(lastMarkIndex, params.getReaderIndex());
} paramMap.put(latestKey, latestValue); if (params.getReadableBytes() == 1) {
params.setReaderIndex(params.getReaderIndex() + 1);
} else if (SipParser.isNext(params, VALUE_END_1)) {
params.setReaderIndex(params.getReaderIndex() + VALUE_END_1.length);
} else if (SipParser.isNext(params, VALUE_END_2)) {
params.setReaderIndex(params.getReaderIndex() + VALUE_END_2.length);
} lastMarkIndex = params.getReaderIndex(); inKey = true;
} else {
params.setReaderIndex(params.getReaderIndex() + 1);
}
}
} catch (Exception e) {
throw new SipParseException(NAME + " parse error, " + e.getCause());
}
} public WWWAuthenticateHeaderImpl(Buffer realm, Buffer nonce, Buffer algorithm, Buffer qop) {
super(WWWAuthenticateHeader.NAME, Buffers.EMPTY_BUFFER);
this.realm = realm;
this.nonce = nonce;
this.algorithm = algorithm;
this.qop = qop;
} @Override
public Buffer getValue() {
Buffer value = super.getValue();
if (value != null && value != Buffers.EMPTY_BUFFER) {
return value;
}
StringBuilder sb = new StringBuilder("Digest realm=\"" + this.getRealm() + "\", nonce=\"" + this.getNonce() + "\"");
if (this.getAlgorithm() != null) {
sb.append(", algorithm=" + this.getAlgorithm());
}
if (this.getQop() != null) {
sb.append(", qop=\"" + this.getQop() + "\"");
}
value = Buffers.wrap(sb.toString());
return value;
} @Override
public String toString() {
StringBuilder sb = new StringBuilder(NAME.toString());
sb.append(": Digest realm=\"" + this.getRealm() + "\", nonce=\"" + this.getNonce() + "\"");
if (this.getAlgorithm() != null) {
sb.append(", algorithm=" + this.getAlgorithm());
}
if (this.getQop() != null) {
sb.append(", qop=\"" + this.getQop() + "\"");
}
return sb.toString();
} @Override
public WWWAuthenticateHeader.Builder copy() {
return new WWWAuthenticateHeader.Builder(getValue());
} @Override
public WWWAuthenticateHeader ensure() {
return this;
} @Override
public WWWAuthenticateHeader clone() {
final Buffer value = getValue();
return new WWWAuthenticateHeaderImpl(value.clone());
} @Override
public Buffer getRealm() {
if (realm != null) {
return realm;
}
realm = paramMap.get(Buffers.wrap("realm"));
return realm;
} @Override
public Buffer getNonce() {
if (nonce != null) {
return nonce;
}
nonce = paramMap.get(Buffers.wrap("nonce"));
return nonce;
} @Override
public Buffer getAlgorithm() {
if (algorithm != null) {
return algorithm;
}
algorithm = paramMap.get(Buffers.wrap("algorithm"));
return algorithm;
} @Override
public Buffer getQop() {
if (qop != null) {
return qop;
}
qop = paramMap.get(Buffers.wrap("qop"));
return qop;
}
}
SipParser里新增注册
static {
framers.put(CallIdHeader.NAME, header -> CallIdHeader.frame(header.getValue()));
framers.put(CallIdHeader.COMPACT_NAME, header -> CallIdHeader.frameCompact(header.getValue()));
...
framers.put(ViaHeader.NAME, header -> ViaHeader.frame(header.getValue()));
framers.put(ViaHeader.COMPACT_NAME, header -> ViaHeader.frame(header.getValue()));
//新增WWWAuthenticateHeader注册
framers.put(WWWAuthenticateHeader.NAME, header -> WWWAuthenticateHeader.frame(header.getValue()));
}
frame方法里,也要新增判断:
public static SipMessage frame(final Buffer buffer) throws IOException {
...
// Move along as long as we actually can consume an header and
...
SipHeader contactHeader = null;
SipHeader wwwAuthenticateHeader = null;
...
while (consumeCRLF(buffer) != 2 && (headerName = SipParser.nextHeaderName(buffer)) != null) {
final List<Buffer> values = readHeaderValues(headerName, buffer).values;
for (final Buffer value : values) {
header = new SipHeaderImpl(headerName, value);
// The headers that are most commonly used will be fully
// parsed just because no stack can really function without
// looking into these headers.
if (header.isContentLengthHeader()) {
final ContentLengthHeader l = header.ensure().toContentLengthHeader();
contentLength = l.getContentLength();
header = l;
}
...
} else if (recordRouteHeader == null && header.isRecordRouteHeader()) {
header = header.ensure();
recordRouteHeader = header;
} else if (wwwAuthenticateHeader == null && header.isWWWAuthenticateHeader()) {
header = header.ensure();
wwwAuthenticateHeader = header;
}
...
}
另外有1个小坑,readme里没提到,类似
WWW-Authenticate: Digest realm="10.32.26.25", nonce="bee3366b-cf59-476e-bc5e-334e0d65b386", algorithm=MD5, qop="auth"
这种header解析时,还要修改SipParser里的isHeaderAllowingMultipleValues方法
private static boolean isHeaderAllowingMultipleValues(final Buffer headerName) {
final int size = headerName.getReadableBytes();
if (size == 7) {
return !isSubjectHeader(headerName);
} else if (size == 5) {
return !isAllowHeader(headerName);
} else if (size == 4) {
return !isDateHeader(headerName);
} else if (size == 1) {
return !isAllowEventsHeaderShort(headerName);
} else if (size == 12) {
return !isAllowEventsHeader(headerName);
} else if (size == 16) {
# 新增判断,防止被解析成多行
return !isWWWAuthenticateHeader(headerName);
}
return true;
}
为了方便判断Buffer接下来几个位置是否为指定字符,SipParser里的isNext也做了扩展
public static boolean isNext(final Buffer buffer, final byte[] bytes) throws IOException {
boolean hasReadableBytes = buffer.hasReadableBytes();
if (!hasReadableBytes) {
return false;
}
int readableBytes = buffer.getReadableBytes();
int length = bytes.length;
if (readableBytes < length) {
return false;
}
boolean match = true;
for (int i = 0; i < length; i++) {
int readIndex = buffer.getReaderIndex() + i;
byte aByte = buffer.getByte(readIndex);
if (aByte != bytes[i]) {
match = false;
break;
}
}
return match;
}
还可以在ImmutableSipMessage类中添加以下方法,这样用起来更顺手
@Override
public WWWAuthenticateHeader getWWWAuthenticateHeader() throws SipParseException{
final SipHeader header = findHeader(WWWAuthenticateHeader.NAME.toString());
return header != null ? header.ensure().toWWWAuthenticateHeader() : null;
}
这些做完后,再来跑先前的测试
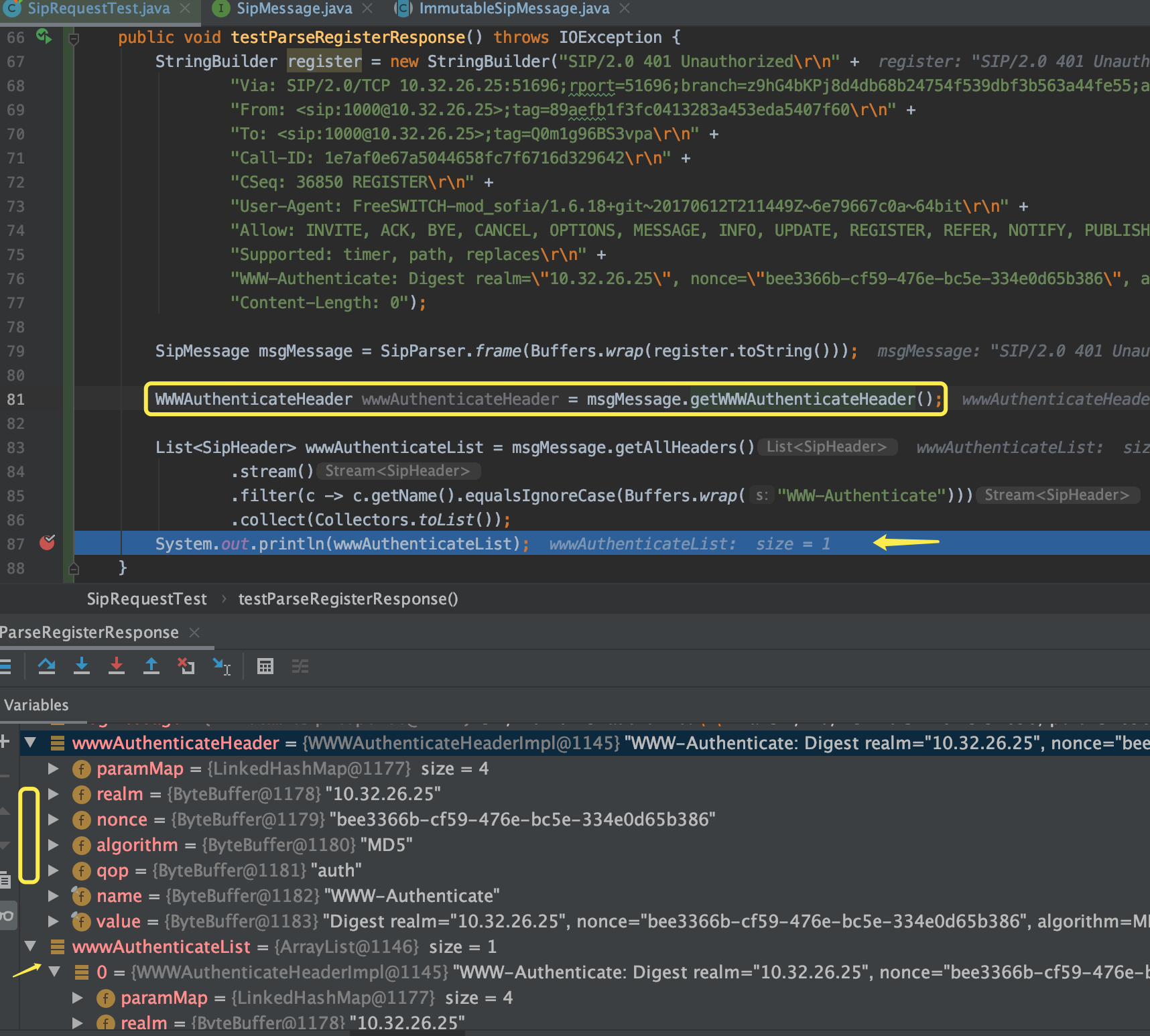
从上图可以看到,realm\nonce\algorithm\qop这些属性已经正确提取出来了,最后可以再测试下Builder
package io.pkts.packet.sip.header.impl; import io.pkts.buffer.Buffer;
import io.pkts.buffer.Buffers;
import io.pkts.packet.sip.SipParseException;
import io.pkts.packet.sip.header.ViaHeader;
import io.pkts.packet.sip.header.WWWAuthenticateHeader;
import org.junit.Test; import static org.hamcrest.CoreMatchers.is;
import static org.hamcrest.CoreMatchers.nullValue;
import static org.junit.Assert.*; public class WWWAuthenticateHeaderImplTest { @Test
public void testBuild1() throws Exception {
final WWWAuthenticateHeader wwwAuthenticateHeader = new WWWAuthenticateHeader.Builder()
.withAlgorithm(Buffers.wrap("MD5"))
.withNonce(Buffers.wrap("bee3366b-cf59-476e-bc5e-334e0d65b386"))
.withQop(Buffers.wrap("auth"))
.withRealm(Buffers.wrap("10.32.26.25"))
.build(); assertEquals(wwwAuthenticateHeader.getAlgorithm(), Buffers.wrap("MD5"));
assertEquals(wwwAuthenticateHeader.getNonce(), Buffers.wrap("bee3366b-cf59-476e-bc5e-334e0d65b386"));
assertEquals(wwwAuthenticateHeader.getQop(), Buffers.wrap("auth"));
assertEquals(wwwAuthenticateHeader.getRealm(), Buffers.wrap("10.32.26.25")); Buffer value = Buffers.wrap("Digest realm=\"10.32.26.25\", nonce=\"bee3366b-cf59-476e-bc5e-334e0d65b386\", algorithm=MD5, qop=\"auth\"");
assertTrue(wwwAuthenticateHeader.getValue().equalsIgnoreCase(value));
} @Test
public void testBuild2() throws Exception {
final WWWAuthenticateHeader wwwAuthenticateHeader = new WWWAuthenticateHeader.Builder()
.withNonce(Buffers.wrap("bee3366b-cf59-476e-bc5e-334e0d65b386"))
.withRealm(Buffers.wrap("10.32.26.25"))
.build(); assertEquals(wwwAuthenticateHeader.getAlgorithm(), null);
assertEquals(wwwAuthenticateHeader.getNonce(), Buffers.wrap("bee3366b-cf59-476e-bc5e-334e0d65b386"));
assertEquals(wwwAuthenticateHeader.getQop(), null);
assertEquals(wwwAuthenticateHeader.getRealm(), Buffers.wrap("10.32.26.25")); Buffer value = Buffers.wrap("Digest realm=\"10.32.26.25\", nonce=\"bee3366b-cf59-476e-bc5e-334e0d65b386\"");
assertTrue(wwwAuthenticateHeader.getValue().equalsIgnoreCase(value));
} @Test
public void testFrame1() throws Exception {
Buffer value = Buffers.wrap("Digest realm=\"10.32.26.25\", nonce=\"bee3366b-cf59-476e-bc5e-334e0d65b386\", algorithm=MD5, qop=\"auth\"");
final WWWAuthenticateHeader wwwAuthenticateHeader = new WWWAuthenticateHeaderImpl(value);
assertEquals(wwwAuthenticateHeader.getAlgorithm(), Buffers.wrap("MD5"));
assertEquals(wwwAuthenticateHeader.getNonce(), Buffers.wrap("bee3366b-cf59-476e-bc5e-334e0d65b386"));
assertEquals(wwwAuthenticateHeader.getQop(), Buffers.wrap("auth"));
assertEquals(wwwAuthenticateHeader.getRealm(), Buffers.wrap("10.32.26.25"));
} @Test
public void testFrame2() throws Exception {
Buffer realm = Buffers.wrap("10.32.26.25");
Buffer nonce = Buffers.wrap("bee3366b-cf59-476e-bc5e-334e0d65b386");
final WWWAuthenticateHeader wwwAuthenticateHeader = new WWWAuthenticateHeaderImpl(realm, nonce, null, null); assertEquals(wwwAuthenticateHeader.getAlgorithm(), null);
assertEquals(wwwAuthenticateHeader.getNonce(), Buffers.wrap("bee3366b-cf59-476e-bc5e-334e0d65b386"));
assertEquals(wwwAuthenticateHeader.getQop(), null);
assertEquals(wwwAuthenticateHeader.getRealm(), Buffers.wrap("10.32.26.25")); Buffer value = Buffers.wrap("Digest realm=\"10.32.26.25\", nonce=\"bee3366b-cf59-476e-bc5e-334e0d65b386\"");
assertTrue(wwwAuthenticateHeader.getValue().equalsIgnoreCase(value));
} }
以上代码,均已提交到 https://github.com/yjmyzz/pkts/tree/master/pkts-sip,供大家参考
如何解析SIP报文的更多相关文章
- Java 发送SOAP请求调用WebService,解析SOAP报文
https://blog.csdn.net/Peng_Hong_fu/article/details/80113196 记录测试代码 SoapUI调用路径 http://localhost:8082/ ...
- 详解http报文(2)-web容器是如何解析http报文的
摘要 在详解http报文一文中,详细介绍了http报文的文本结构.那么作为服务端,web容器是如何解析http报文的呢?本文以jetty和undertow容器为例,来解析web容器是如何处理http报 ...
- 第14.12节 Python中使用BeautifulSoup解析http报文:使用select方法快速定位内容
一. 引言 在<第14.10节 Python中使用BeautifulSoup解析http报文:html标签相关属性的访问>和<第14.11节 Python中使用BeautifulSo ...
- 第14.11节 Python中使用BeautifulSoup解析http报文:使用查找方法快速定位内容
一. 引言 在<第14.10节 Python中使用BeautifulSoup解析http报文:html标签相关属性的访问>介绍了BeautifulSoup对象的主要属性,通过这些属性可以访 ...
- java 写webservice接口解析xml报文
1 <!--解析xml报文--> 2 <dependency> 3 <groupId>dom4j</groupId> 4 <artifactId& ...
- 音频和视频流最佳选择?SRT 协议解析及报文识别
我们所知道 SRT 是由 Haivision 和 Wowza 开发的开源视频流协议.很多人会认为在不久的将来,它被是 RTMP 的替代品.因为 RTMP 协议安全性稍低,延迟相对较高 ,而相对于 SR ...
- 解析HTTP报文——C#
目前没有找到.Net框架内置的解析方法,理论上HttpClient等类在内部应该已经实现了解析,但不知为何没有公开这些处理方法.(亦或是我没找到)那么只能自己来解析这些数据了. public enum ...
- 解析IPV4报文 和IPV6 报文的 checksum
解析IPV4报文和IPV6报文的checksum的算法: 校验和(checksum)算法,简单的说就是16位累加的反码运算: 计算函数如下: 我们在计算时是主机字节序,计算的结果封装成IP包时是网络字 ...
- httpClient调用接口的时候,解析返回报文内容
比如我httpclient调用的接口返回的格式是这样的: 一:data里是个对象 { "code": 200, "message": "执行成功&qu ...
- 第14.10节 Python中使用BeautifulSoup解析http报文:html标签相关属性的访问
一. 引言 在<第14.8节 Python中使用BeautifulSoup加载HTML报文>中介绍使用BeautifulSoup的安装.导入和创建对象的过程,本节介绍导入后利用Beauti ...
随机推荐
- heapdump敏感信息提取工具-heapdump_tool(二),附下载链接。
heapdump敏感信息查询工具,例如查找 spring heapdump中的密码明文,AK,SK等 下载链接: heapdump_tool下载链接:heapdump_tool下载 声明: 此工具 ...
- 【BUG】Hexo|GET _MG_0001.JPG 404 (Not Found),hexo博客搭建过程图片路径正确却找不到图片
我的问题 我查了好多资料,结果原因是图片名称开头是_则该文件会被忽略...我注意到网上并没有提到这个问题,遂补了一下这篇博客并且汇总了我找到的所有解决办法. 具体检查方式: hexo生成一下静态资源: ...
- 作业时间之"最早时间和最晚时间"
一.从左往右(小到大)算最早时间 0+2=2 0+3=3 因为3比2大所以选择3(早大晚小),需活动无时间所以不用加 3+4=7 7+3=10 因为13号点有两个 2+5=7 和 11号点的10(虚活 ...
- 解决uniapp实现ios系统中低功耗蓝牙通讯失败问题
UniApp 实现 App 连接低功耗蓝牙(BLE)通讯 手头上有一个 uniapp 实现低功耗蓝牙通讯设备的项目,本来 Android 版本没问题已经上线,到了发布测试 iOS 出问题了,连接上了设 ...
- 【Java持久层技术演进全解析】从JDBC到MyBatis再到MyBatis-Plus
从JDBC到MyBatis再到MyBatis-Plus:Java持久层技术演进全解析 引言 在Java企业级应用开发中,数据持久化是核心需求之一.本文将系统性地介绍Java持久层技术的演进过程,从最基 ...
- 解决git clone 速度慢问题比较赞的方法
使用国内镜像,目前已知的GitHub国内镜像网站有github.com.cnpmjs.org和git.sdut.me. 在clone 某项目时候可将github.com替换为github.com.cn ...
- DataFrame.iterrows的一种用法
import pandas as pd import numpy as np help(pd.DataFrame.iterrows) Help on function iterrows in modu ...
- codeup之复制字符串中的元音字母
Description 写一个函数,将一个字符串中的元音字母复制到另一个字符串中.在主函数中输入一个字符串,通过调用该函数,得到一个有该字符串中的元音字母组成的一个字符串,并输出. Input 一个字 ...
- dify+MCP多应用,构建灵活的AI应用生态系统
一.概述 前面几篇文章写很多MCP应用,基本上一个dify工作流使用一个MCP应用. 那么一个dify工作流,同时使用多个MCP应用,是否可以呢?答案是可以的. 先来看一下效果图 说明: 这里使用了问 ...
- 「Note」CF 套题
最后一次添加的题目:CF1572C CF *2000-*2100 \(\color{blueviolet}{CF771C}\) 非常好题目啊. 首先考虑题目让你求的到底是个什么东西,不难看出 \(f( ...