Informer架构以及简单使用
Informer架构以及简单使用
介绍
我们知道可以使用 Clientset 来获取所有的原生资源对象,那么如果我们想要去一直获取集群的资源对象数据呢?岂不是需要用一个轮询去不断执行 List() 操作?这显然是不合理的,实际上除了常用的 CRUD 操作之外,我们还可以进行 Watch 操作,可以监听资源对象的增、删、改、查操作,这样我们就可以根据自己的业务逻辑去处理这些数据了。
Watch 通过一个 event 接口监听对象的所有变化(添加、删除、更新):
// staging/src/k8s.io/apimachinery/pkg/watch/watch.go
// Interface 可以被任何知道如何 watch 和通知变化的对象实现
// Interface can be implemented by anything that knows how to watch and report changes.
type Interface interface {
// Stop stops watching. Will close the channel returned by ResultChan(). Releases
// any resources used by the watch.
Stop()
// ResultChan returns a chan which will receive all the events. If an error occurs
// or Stop() is called, the implementation will close this channel and
// release any resources used by the watch.
ResultChan() <-chan Event
}
watch 接口的 ResultChan 方法会返回如下几种事件:
// staging/src/k8s.io/apimachinery/pkg/watch/watch.go
// EventType defines the possible types of events.
// EventType 定义可能的事件类型
type EventType string
const (
Added EventType = "ADDED"
Modified EventType = "MODIFIED"
Deleted EventType = "DELETED"
Bookmark EventType = "BOOKMARK"
Error EventType = "ERROR"
)
var (
DefaultChanSize int32 = 100
)
// Event represents a single event to a watched resource.
// +k8s:deepcopy-gen=true
type Event struct {
Type EventType
// Object is:
// * If Type is Added or Modified: the new state of the object.
// * If Type is Deleted: the state of the object immediately before deletion.
// * If Type is Bookmark: the object (instance of a type being watched) where
// only ResourceVersion field is set. On successful restart of watch from a
// bookmark resourceVersion, client is guaranteed to not get repeat event
// nor miss any events.
// * If Type is Error: *api.Status is recommended; other types may make sense
// depending on context.
Object runtime.Object
}
这个接口虽然我们可以直接去使用,但是实际上并不建议这样使用,因为往往由于集群中的资源较多,我们需要自己在客户端去维护一套缓存,而这个维护成本是非常大的,为此client-go也提供了自己的实现机制,那就是Informers。Informers是这个事件接口和带索引查找功能的内存缓存的组合,这也是目前最常用的用法。
Informers第一次被调用的时候会首先在客户端调用List来获取全量的对象集合,然后通过Watch来获取增量的对象更新缓存。
架构说明
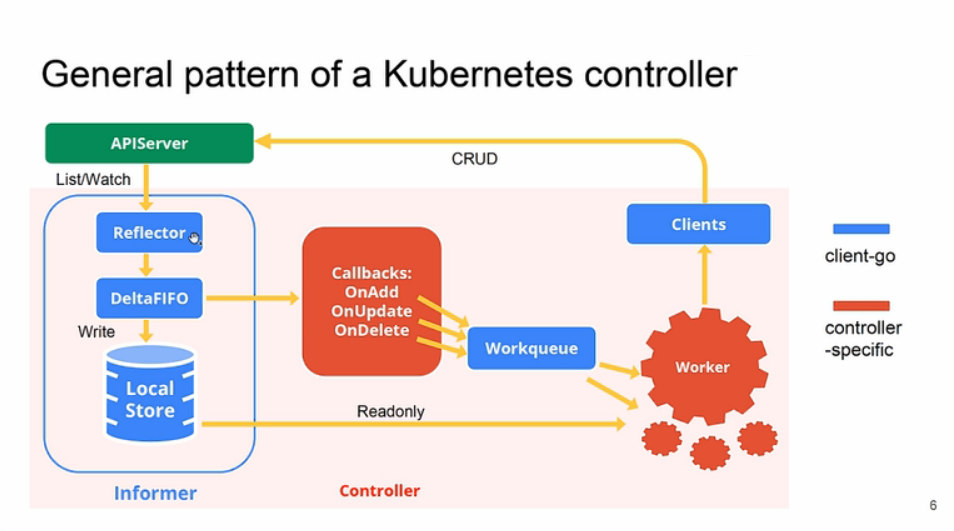
上图是整个 client-go 的完整架构图,或者说是我们要去实现一个自定义的控制器的一个整体流程。
下图是 client-go 的官方实现架构图,其中黄色图标是开发者需要自行开发的部分,而其它的部分是 client-go 已经提供的,直接使用即可。 由于 client-go 实现非常复杂,我们这里先对图中最核心的部分 Informer 进行说明。
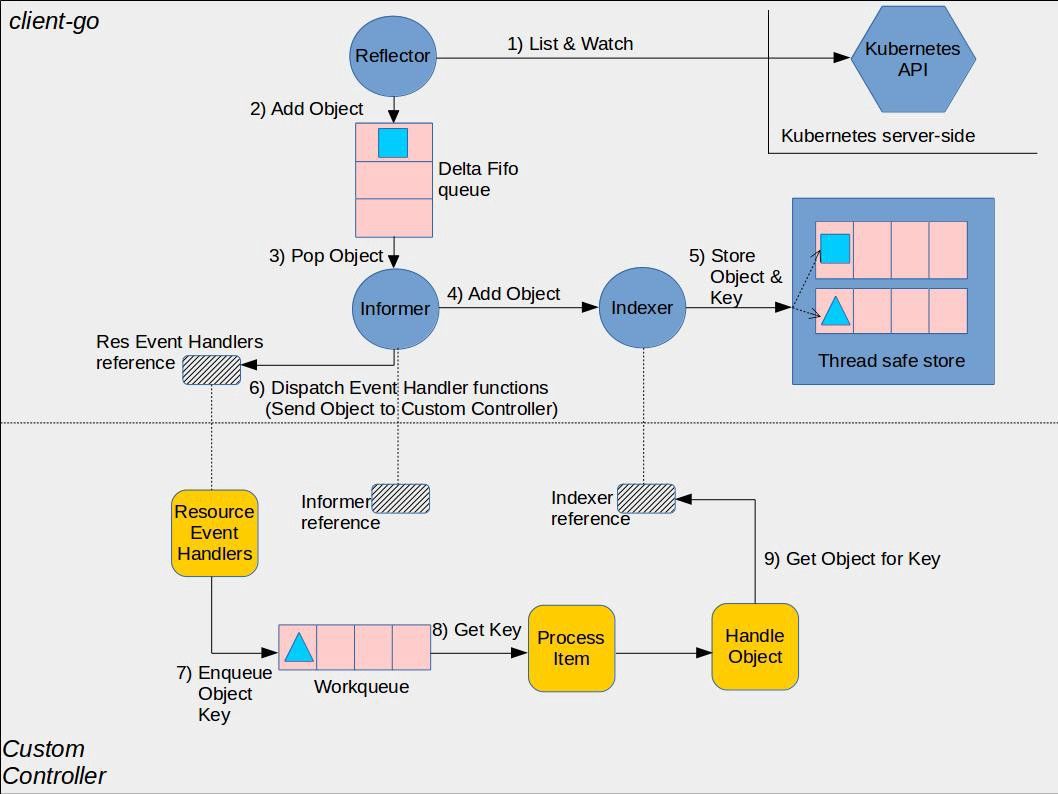
Informers 是 client-go 中非常重要得概念,接下来我们来仔细分析下 Informers 的实现原理:
Reflector(反射器)
Reflector 用于监控(Watch)指定的 Kubernetes 资源,当监控的资源发生变化时,触发相应的变更事件,例如 Add 事件、Update 事件、Delete 事件,并将其资源对象存放到本地缓存 DeltaFIFO 中。
DeltaFIFO
DeltaFIFO 是一个生产者-消费者的队列,生产者是 Reflector,消费者是 Pop 函数,FIFO 是一个先进先出的队列,而 Delta 是一个资源对象存储,它可以保存资源对象的操作类型,例如 Add 操作类型、Update 操作类型、Delete 操作类型、Sync 操作类型等。
Indexer
Indexer 是 client-go 用来存储资源对象并自带索引功能的本地存储,Informer(sharedIndexInformer) 从 DeltaFIFO 中将消费出来的资源对象存储至 Indexer。Indexer 与 Etcd 集群中的数据保持完全一致。这样我们就可以很方便地从本地存储中读取相应的资源对象数据,而无须每次从远程 APIServer 中读取,以减轻服务器的压力。
这里理论知识太多,直接去查看源码显得有一定困难,我们可以用一个实际的示例来进行说明,比如现在我们删除一个 Pod,一个 Informers 的执行流程是怎样的:
- 首先初始化 Informer,Reflector 通过 List 接口获取所有的 Pod 对象
- Reflector 拿到所有 Pod 后,将全部 Pod 放到 Store(本地缓存)中
- 如果有人调用 Lister 的 List/Get 方法获取 Pod,那么 Lister 直接从 Store 中去拿数据
- Informer 初始化完成后,Reflector 开始 Watch Pod 相关的事件
- 此时如果我们删除 Pod1,那么 Reflector 会监听到这个事件,然后将这个事件发送到 DeltaFIFO 中
- DeltaFIFO 首先先将这个事件存储在一个队列中,然后去操作 Store 中的数据,删除其中的 Pod1
- DeltaFIFO 然后 Pop 这个事件到事件处理器(资源事件处理器)中进行处理
- LocalStore 会周期性地把所有的 Pod 信息重新放回 DeltaFIFO 中去
运行原理
一个控制器每次需要获取对象的时候都要访问 APIServer,这会给系统带来很高的负载,Informers 的内存缓存就是来解决这个问题的,此外 Informers 还可以几乎实时的监控对象的变化,而不需要轮询请求,这样就可以保证客户端的缓存数据和服务端的数据一致,就可以大大降低 APIServer 的压力了。
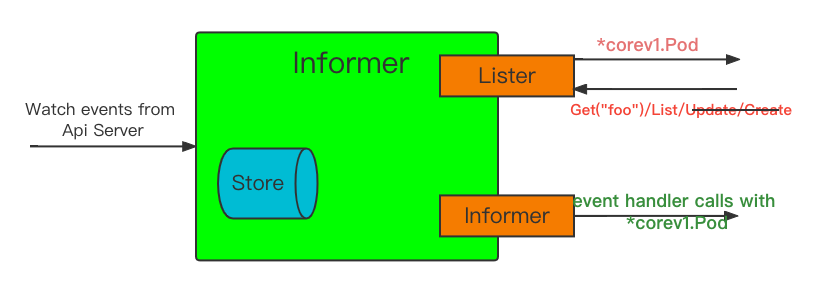
如上图展示的 Informer 的基本处理流程:
1、以 events 事件类型的方式从APIServer获取数据
2、提供了一个类似客户端的Lister接口,从内存缓存中获get和list对象
3、为添加、删除、更新注册事件处理程序
此外 Informers 也有错误处理方式,当长期运行的 watch 连接中断时,它们会尝试使用另一个 watch 请求来恢复连接,在不丢失任何事件的情况下恢复事件流。如果中断的时间较长,而且 APIServer 丢失了事件(etcd 在新的 watch 请求成功之前从数据库中清除了这些事件),那么 Informers 就会重新 List 全量数据。
而且在重新 List 全量操作的时候还可以配置一个重新同步的周期参数,用于协调内存缓存数据和业务逻辑的数据一致性,每次过了该周期后,注册的事件处理程序就将被所有的对象调用,通常这个周期参数以分为单位,比如10分钟或者30分钟。
注意:重新同步是纯内存操作,不会触发对服务器的调用。
Informers 的这些高级特性,都足以让我们不去直接使用客户端的 Watch() 方法来处理自己的业务逻辑,而且在 Kubernetes 中也有很多地方都有使用到 Informers。但是在使用 Informers 的时候,通常每个 GroupVersionResource(GVR)只实例化一个 Informers,但是有时候我们在一个应用中往往有使用多种资源对象的需求,这个时候为了方便共享 Informers,我们可以通过使用共享 Informer 工厂来实例化一个 Informer。
共享 Informer 工厂允许我们在应用中为同一个资源共享 Informer,也就是说不同的控制器循环可以使用相同的 watch 连接到后台的 APIServer,例如,kube-controller-manager 中的控制器数据量就非常多,但是对于每个资源(比如 Pod),在这个进程中只有一个 Informer。
示例
首先我们创建一个 Clientset 对象,然后使用 Clientset 来创建一个共享的 Informer 工厂,Informer 是通过 informer-gen 这个代码生成器工具自动生成的,位于 k8s.io/client-go/informers 中。
这里我们来创建一个用于获取 Deployment 的共享 Informer,代码如下所示:
package main
import (
"flag"
"fmt"
v1 "k8s.io/api/apps/v1"
"k8s.io/apimachinery/pkg/labels"
"k8s.io/client-go/informers"
"k8s.io/client-go/kubernetes"
"k8s.io/client-go/rest"
"k8s.io/client-go/tools/cache"
"k8s.io/client-go/tools/clientcmd"
"k8s.io/client-go/util/homedir"
"path/filepath"
"time"
)
func main() {
var err error
var config *rest.Config
var kubeconfig *string
if home := homedir.HomeDir(); home != "" {
kubeconfig = flag.String("kubeconfig", filepath.Join(home, ".kube", "config"), "[可选] kubeconfig 绝对路径")
} else {
kubeconfig = flag.String("kubeconfig", "", "kubeconfig 绝对路径")
}
// 初始化 rest.Config 对象
if config, err = rest.InClusterConfig(); err != nil {
if config, err = clientcmd.BuildConfigFromFlags("", *kubeconfig); err != nil {
panic(err.Error())
}
}
// 创建clientSet对象
clientset, err := kubernetes.NewForConfig(config)
if err != nil {
panic(err.Error())
}
// 初始化 informer factory
// 为了测试方便,这里设置没30s重新 List 一次
informerFactory := informers.NewSharedInformerFactory(clientset, time.Second*30)
// 对 deploy 进行监听
deployInformer := informerFactory.Apps().V1().Deployments()
// 创建 Informer
// 相当于注册到工厂中去,这样下面启动的时候就会去 list & watch 对应的资源
informer := deployInformer.Informer()
// 创建 lister
deployLister := deployInformer.Lister()
// 注册事件处理程序
informer.AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: onAdd,
UpdateFunc: onUpdate,
DeleteFunc: onDelete,
})
stopper := make(chan struct{})
defer close(stopper)
// 启动 informer, List & Watch
informerFactory.Start(stopper)
// 等待所有启动的 Informer 的缓存被同步
informerFactory.WaitForCacheSync(stopper)
// 从本地缓存中获取 default 中所有 deployment 列表
deployments, err := deployLister.Deployments("default").List(labels.Everything())
if err != nil {
panic(err.Error())
}
for idx, deploy := range deployments {
fmt.Printf("%d -> %s\n", idx+1, deploy.Name)
}
<-stopper
}
func onAdd(obj interface{}) {
deploy := obj.(*v1.Deployment)
fmt.Println("add a deployment:", deploy.Name)
}
func onUpdate(old, new interface{}) {
oldDeploy := old.(*v1.Deployment)
newDeploy := new.(*v1.Deployment)
fmt.Println("update deployment:", oldDeploy.Name, newDeploy.Name)
}
func onDelete(obj interface{}) {
deploy := obj.(*v1.Deployment)
fmt.Println("delete a deployment:", deploy.Name)
}
上面的代码运行可以获得 default 命名空间之下的所有 Deployment 信息以及整个集群的 Deployment 数据。
$ kubectl create deployment nginx --image=nginx:1.17.1
$ go run main.go
add a deployment: coredns
add a deployment: nginx
update deployment: nginx nginx
update deployment: nginx nginx
......
这是因为我们首先通过 Informer 注册了事件处理程序,这样当我们启动 Informer 的时候首先会将集群的全量 Deployment 数据同步到本地的缓存中,会触发 AddFunc 这个回调函数,然后我们又在下面使用 Lister() 来获取 default 命名空间下面的所有 Deployment 数据,这个时候的数据是从本地的缓存中获取的,所以就看到了上面的结果,由于我们还配置了每30s重新全量 List 一次,所以正常每30s我们也可以看到所有的 Deployment 数据出现在 UpdateFunc 回调函数下面,我们也可以尝试去删除一个 Deployment,同样也会出现对应的 DeleteFunc 下面的事件。
Informer架构以及简单使用的更多相关文章
- 模糊系统架构和简单实现--AForge.NET框架的使用(四)
原文:模糊系统架构和简单实现--AForge.NET框架的使用(四) 先说一下,为什么题目是简单实现,因为我实在没有弄出好的例子. 我原来用AForge.net做的项目中的模糊系统融入了神经网络和向量 ...
- [MySQL] 高可用架构MMM简单介绍
一.来源及原理: 众所周知,MySQL自身提供了AB复制(主从复制),然后可以很轻松实现master-master双向复制,同时再为其中一个Master节点搭建一个Slave库. 这样就实现了MySQ ...
- .NET 三层架构的简单规划
今天心血来潮简单看了下petshop4.0的源代码,他就是用三层架构来实现的.现在简单的做下总结. 首先我们先看下petshop的三层架构. 1 WEB 表示层 2 Model 业务实体 3 BLL ...
- 微服务架构的简单实现-Stardust
微服务架构,一个当下比较火的概念了.以前也只是了解过这方面的概念,没有尝试过.想找找.NET生态下面是否有现成的实现,可是没找到,就花了大半个月的闲暇时间,遵循着易用和简单,实现了一个微服务框架,我叫 ...
- 分布式通讯架构RPC简单实现
什么是RPC: RPC(Remote Procedure Call,远程过程调用),一般用来实现部署在不同机器上的系统之间的方法调用,使得程序能够像访问本地系统资源一样,通过网络传输去访问远端系统资源 ...
- 用Spring.Services整合 thrift0.9.2生成的wcf中间代码-复杂的架构带来简单的代码和高可维护性
最近一直在看关于thrift的相关文章,涉及到的内容的基本都是表层的.一旦具体要用到实际的项目中的时候就会遇到各种问题了! 比如说:thrift 的服务器端载体的选择.中间代码的生成options(a ...
- 一:【nopcommerce系列】Nop整体架构的简单介绍,在看nop代码之前,你需要懂哪些东西
首先,我看的是Nop 3.80,最新版 百度资料很多,Nop用到的主要的技术有: 1.Mvc,最新版用的是 5.2.3.0 2.entity framework 3.autofac 4.插件化 5.( ...
- MVC思想架构的简单自定义UITableViewCell
在iOS的开发过程中,架构思想是很重要的一部分,目前的主流应该分为MVC与MVVM两种,在这里不做过多的区分,有兴趣的同学可以看看唐巧大神的一篇文章<被误解的MVC和被神化的MVVM& ...
- 传统应用、服务器集群、分布式、SOA各种架构的简单解释
传统架构:无论是SE应用还是WEB应用,传统架构都是表现层---业务层---持久层---数据库 1000并发(tomcat单台500并发,tomcat一般做集群的话,节点数量不能太多,5个左右): ...
- Openstack架构概念图-简单汇总
OpenStack是一个云平台管理的项目,它不是一个软件.这个项目由几个主要的组件组合起来完成一些具体的工作.想要了解openstack,第一步我们可以观察他的概念图: 针对上图的翻译+解释: 上图主 ...
随机推荐
- docker批量删除容器或镜像
删除容器 停止所有容器 删除所有容器,需要先停止所有运行中的容器 docker stop `docker ps -a -q` docker ps -a -q,意思是列出所有容器(包括未运行的),只显示 ...
- linux clickhouse 密码设置
默认密码 clickhouse 安装好之后,系统默认的登录账号密码是 /etc/clickhouse-server/users.d/default-password.xml 文件中配置的,默认密码是 ...
- Win32控制台获取可执行程序的快捷方式的目标位置、起始位置、快捷键、备注等
Win32控制台获取可执行程序的快捷方式的目标位置.起始位置.快捷键.备注等,示例如下图: #include <iostream> #include <atlstr.h> #i ...
- MySQL函数-根据子节点查询所有父节点名称
背景 公司的一个业务系统中有区域表,整个区域是一个树结构,为了方便根据某一父节点查询所有叶子节点,提供了一个额外的字段path,按照分隔符存储了从根节点到当前节点的总路径. 表结构如下: create ...
- Next.js中间件权限绕过漏洞分析(CVE-2025-29927)
本文代码版本为next.js-15.2.2 本篇文章首发在先知社区:https://xz.aliyun.com/news/17403 一.漏洞概述 CVE-2025-29927是Next.js框架中存 ...
- 解决 Maven 打包项目中 Excel 文件乱码问题
在 Java 项目开发过程中,我们常常会使用 Maven 来管理项目依赖和进行项目打包.当涉及到使用 Freemarker 导出 Excel 文件时,不少开发者可能会遇到一个让人头疼的问题 --Exc ...
- 2024 (ICPC) Jiangxi Provincial Contest -- Official Contest
L. Campus 1.首先考虑时间复杂度,因为最多只会有2*k的时间点,所以我们采取的策略是,对这每个时刻,判断有多少扇门是开的,并且考虑这些门到其他点的最短路之和. 2.输入完数据以后,使用dij ...
- .net WorkFlow 流程定义
WikeFlow官网:www.wikesoft.com WikeFlow学习版演示地址:workflow.wikesoft.com WikeFlow学习版源代码下载:https://gitee.com ...
- 等待元素加载出来后再执行下一步的方法(execute javascript指令的用法)
上图,会员修改参数后,提示修改成功,弹出层会暂时冻结页面,导致"会员"菜单不可点击 除了使用sleep加等待时间的方法解决,本教程用"execute javascript ...
- 康谋分享 | 数据隐私和匿名化:PIPL与GDPR下,如何确保数据合规?(二)
在上期数据隐私和匿名化系列文章中,我们主要分享了<中国个人信息保护法>(PIPL)和<欧盟通用数据保护条例>(GDPR)在涵盖范围.定义.敏感信息等方面的异同点,今天,我们将重 ...