tensor_scatter_add算子异同点
技术背景
在MindSpore的ops下实现了一个tensor_scatter_add算子。这个算子的作用为,例如给定一个shape为(1,2,3,4)的原始tensor,因为这个tensor有4个维度,所以我们每次去提取一个tensor元素的时候,就需要4个索引。那么假如说我们要提取这个tensor中的5个元素,那么需要用到的索引tensor的shape应该为(5,4)。这样一来就可以提取得到5个元素,然后做一个add的操作,给定一个目标的tensor,它的shape为(5,),我们就可以把这个目标tensor按照索引tensor,加到原始的tensor里面去,这就是tensor_scatter_add算子的作用。但是在PyTorch中没有这个算子的实现,只有scatter_add和index_add,但是这三个算子的作用是完全不一样的,接下来用代码示例演示一下。
代码实现
首先看一个mindspore的tensor_scatter_add算子,其官方文档的介绍是这样的:

以下是一个代码实现的示例:
In [1]: import mindspore as ms
In [2]: arr=ms.numpy.zeros((1,2,3,4),dtype=ms.float32)
In [3]: idx=ms.numpy.zeros((5,4),dtype=ms.int64)
In [4]: src=ms.numpy.ones((5,),dtype=ms.float32)
In [5]: res=ms.ops.tensor_scatter_add(arr,idx,src)
In [6]: res.sum()
Out[6]: Tensor(shape=[], dtype=Float32, value= 5)
In [7]: res
Out[7]:
Tensor(shape=[1, 2, 3, 4], dtype=Float32, value=
[[[[ 5.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00],
[ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00],
[ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00]],
[[ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00],
[ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00],
[ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00]]]])
在MindSpore中该算子支持的是挺好的,因为在索引里面其实存在重复索引,并行计算的话可能存在race condition的问题,而MindSpore中还是可以做到正确的加和。在PyTorch中有一个scatter_add算子,但是跟MindSpore里面的tensor_scatter_add完全是两个不一样的算子,以下是一个示例:
In [1]: import torch as tc
In [2]: arr=tc.zeros((1,2,3,4),dtype=tc.float32)
In [3]: idx=tc.zeros((5,4),dtype=tc.int64)
In [4]: src=tc.ones((5,),dtype=tc.float32)
In [6]: res=tc.scatter_add(arr,0,idx,src)
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Cell In[6], line 1
----> 1 res=tc.scatter_add(arr,0,idx,src)
RuntimeError: Index tensor must have the same number of dimensions as self tensor
他这个scatter_add算子就不是为了这种场景而设计的。
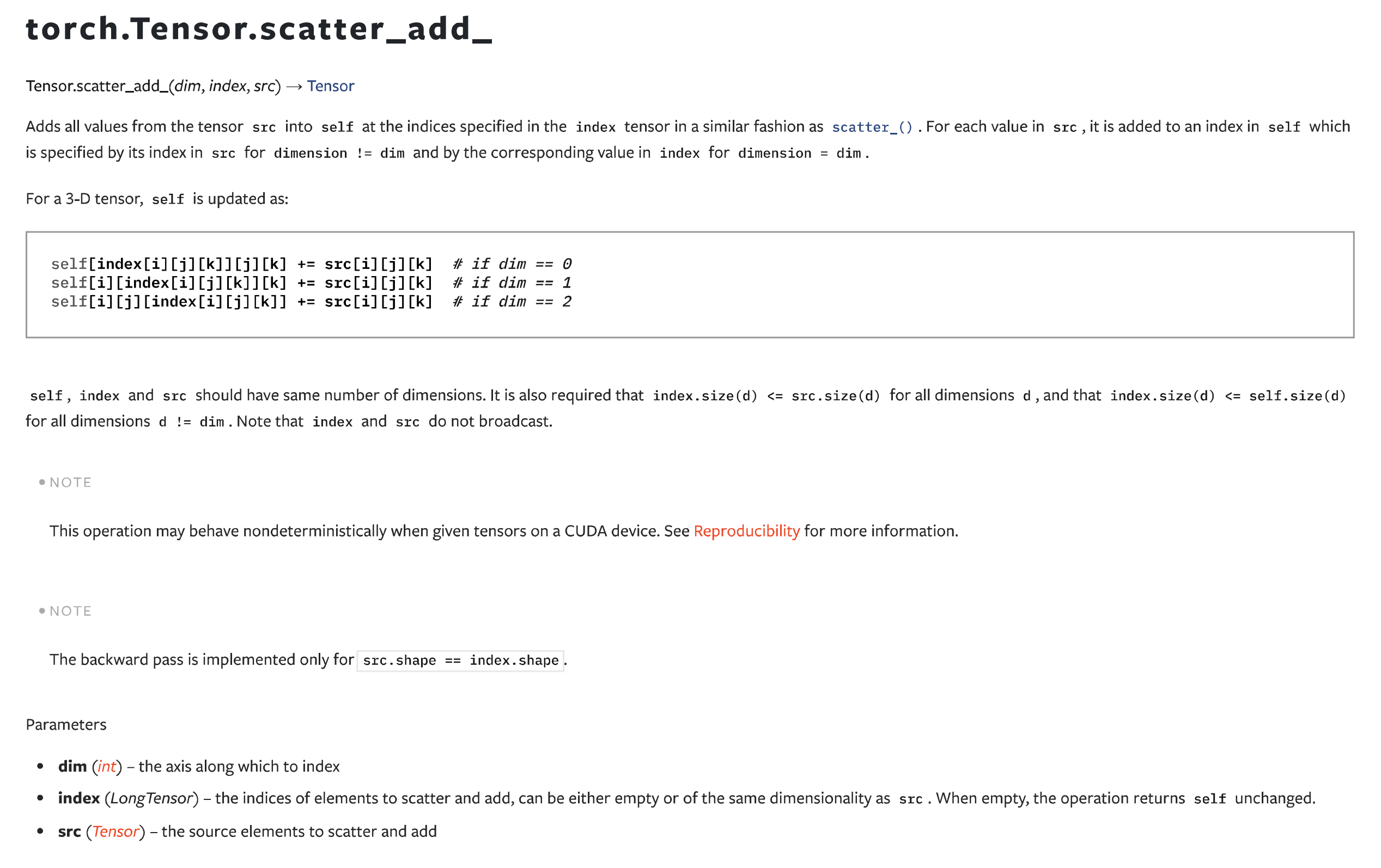
还有另外一个index_add,但是用法也不太相似:
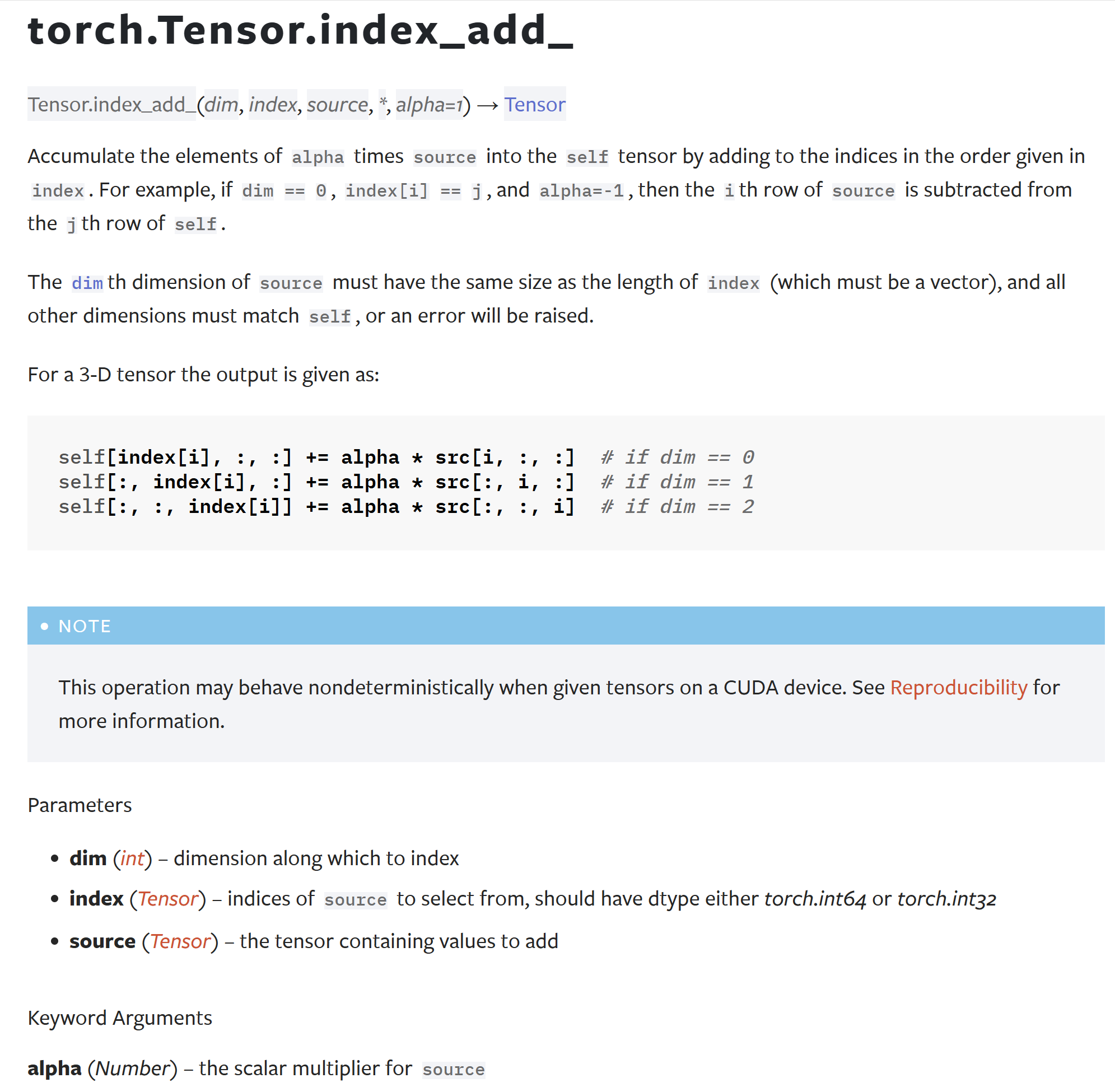
不过如果想要用PyTorch实现这个功能的话,也不是没有办法。还是以这个例子来说,因为原始tensor有4个维度,所以索引到每一个元素需要4个索引编号。在PyTorch中可以直接这样操作(不建议!不建议!不建议!):
In [8]: arr[idx[:,0],idx[:,1],idx[:,2],idx[:,3]]+=src
In [9]: arr.sum()
Out[9]: tensor(1.)
In [10]: arr
Out[10]:
tensor([[[[1., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]],
[[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]]]])
这个例子就可以看出来,直接使用索引进行加和的话,结果是不对的。存在相同索引的情况下,不同的操作之间有可能相互覆盖。所以,非常的不建议这么操作,除非能够确保索引tensor都是唯一的。
总结概要
本文介绍了MindSpore中的tensor_scatter_add算子的用法,可以对一个多维的tensor在指定的index上面进行加和操作。在PyTorch中虽然也有一个叫scatter_add的算子,但是本质上来说两者是完全不一样的操作。
版权声明
本文首发链接为:https://www.cnblogs.com/dechinphy/p/tensor-scatter-add.html
作者ID:DechinPhy
更多原著文章:https://www.cnblogs.com/dechinphy/
请博主喝咖啡:https://www.cnblogs.com/dechinphy/gallery/image/379634.html
tensor_scatter_add算子异同点的更多相关文章
- 13. 用Roberts、Sobel、Prewitt和Laplace算子对一幅灰度图像进行边缘检测。观察异同。
#include <opencv2/opencv.hpp> #include<opencv2/highgui/highgui.hpp> #include<opencv2/ ...
- (转) 开运算opening_circle和闭运算closing_circle的异同
从去除毛刺的策略看开运算opening_circle和闭运算closing_circle的异同 例一:毛刺在往外凸的面上 策略1:分割出黑色部分,然后通过开运算去掉毛刺,再通过原黑色部分区域减去开运算 ...
- 常见的transformation算子
RDD:RDD分区数,若从HDFS创建RDD,RDD的分区就是和文件块一一对应,若是集合并行化形式创建,RDD分区数可以指定,一般默认值是CPU的核数. task:task数量就是和分区数量对应. 一 ...
- halcon基础算子介绍(窗口创建,算子运行时长,是否启用更新函数)
前言 halcon有有大约1500个算子,我总结一些简单大家用得到的算子,比如创建窗口的方式有3种,接下来结束这方式,及其异同点等! 1.窗口创建的三种方式 1.1使用dev_open_window算 ...
- Java 堆内存与栈内存异同(Java Heap Memory vs Stack Memory Difference)
--reference Java Heap Memory vs Stack Memory Difference 在数据结构中,堆和栈可以说是两种最基础的数据结构,而Java中的栈内存空间和堆内存空间有 ...
- Atitit 会话层和表示层的异同
Atitit 会话层和表示层的异同 会话层 这一层也称为会晤层或对话层.在会话层及以上的更高层次中,数据传送的单位没有另外再取名字,一般都可称为报文. 会话层虽然不参与具体的数据传输,但它却对数据传输 ...
- (八)map,filter,flatMap算子-Java&Python版Spark
map,filter,flatMap算子 视频教程: 1.优酷 2.YouTube 1.map map是将源JavaRDD的一个一个元素的传入call方法,并经过算法后一个一个的返回从而生成一个新的J ...
- Linux知识:/root/.bashrc与/etc/profile的异同
Linux知识:/root/.bashrc与/etc/profile的异同 要搞清bashrc与profile的区别,首先要弄明白什么是交互式shell和非交互式shell,什么是login shel ...
- opencv中的SIFT,SURF,ORB,FAST 特征描叙算子比较
opencv中的SIFT,SURF,ORB,FAST 特征描叙算子比较 参考: http://wenku.baidu.com/link?url=1aDYAJBCrrK-uk2w3sSNai7h52x_ ...
- 特征描述算子-sift
特征描述算子-sift http://boche.github.io/download/sift/Introduction%20to%20SIFT.pdf
随机推荐
- docker 版本号说明
17.03 版本以前 Docker CE 在 17.03 版本之前叫 Docker Engine, 版本说明参考这里 => Docker Engine release notes, 可以看到 D ...
- nacos(八): sentinel——基本使用
一.概要 在微服务的架构中,流控是一个重要的任务.sentinel是阿里开源的流量治理组件,针对访问的"资源"或服务路径进行流控,内置了限流.熔断及系统负载保护等功能. senti ...
- 【DXP】如何在原理图中批量修改
零.问题 想要修改所有电阻的封装,怎么解决? 一.解决 以修改所有电阻封装为例,可举一反三. 在电阻上右键,选择"查找相似对象". 注意在右键的时候鼠标应该是放在元器件图标上的,而 ...
- Nodejs与管道和信号
Nodejs与管道 Linux的其中一个设计哲学就是小而精,一个程序只做一件事情,然后通过管道将多个程序连接起来完成复杂的任务. 比如如下的命令: ps -ef | grep node cat aaa ...
- C 图上的遍历算法
图上的遍历算法 广度优先搜索 BFS 概念 广度优先搜索(Breadth-First Search)是一种图遍历算法,用于在图或树中按层次逐层访问节点.它从源节点(起始节点)开始,首先访问源节点的所有 ...
- luat编程MQTT的自动重连失败分析
正确用法 查看代码 --- 模块功能:MQTT客户端处理框架 -- @author openLuat -- @module mqtt.mqttTask -- @license MIT -- @copy ...
- Spring框架中的单例bean是线程安全的吗?
1.介绍两个概念 有状态的bean:对象中有实例变量(成员变量),可以保存数据,是非线程安全的 无状态的bean:对象中没有实例变量(成员变量),不能保存数据,可以在多线程环境下共享,是线程安全的 2 ...
- 【doctrine/orm】findBy用法
用法: //$condition array('表字段对应的entity的属性'=>'值') //$orderBy array('表字段'=>'ASC/DESC') //$count in ...
- 【解决方法】edge浏览器不小心删除收藏夹怎么办?
C:\Users\用户名\AppData\Local\Microsoft\Edge\User Data\Default 进入该目录,找到名为Bookmarks或Bookmarks.bak或Bookma ...
- EF core番外——EF core 输出生成的SQL 到控制台
----------------版权声明:本文为CSDN博主「爱睡觉的程序员」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明.原文链接:https://blog.cs ...