提高数据的安全性和可控性,数栈基于 Ranger 实现的 Spark SQL 权限控制实践之路
在企业级应用中,数据的安全性和隐私保护是极其重要的。Spark 作为数栈底层计算引擎之一,必须确保数据只能被授权的人员访问,避免出现数据泄露和滥用的情况。为了实现Spark SQL 对数据的精细化管理及提高数据的安全性和可控性,数栈基于 Apache Ranger 实现了 Spark SQL 对数据处理的权限控制。
本文基于 Apahce Spark 2.4.8 和 Apache Ranger 2.2 进行原理讲解,和大家聊聊「袋鼠云一站式大数据基础软件数栈」基于 Ranger 在 Spark SQL 权限控制上的实践探索之路。
基于Ranger实现Spark SQL权限控制
Apache Ranger 是一个开源的权限管理框架,可以提供对 Hadoop 生态系统的安全访问控制。Ranger 为开发者提供了一种可扩展的框架,可以进行统一的数据安全管理,内置包括对 Hadoop、Hive、HBase、Kafka 等多个组件的访问控制。
Ranger 内置并没有提供 Spark 的权限控制插件,需要开发者自己实现,基于 Ranger 数栈实现了 Spark SQL 对库、表、列和 UDF 的访问权限控制、行级别权限控制和数据脱敏三方面的权限管理与控制。接下来我们分两部分对其实现原理进行讲解,分别是自定义 Ranger 插件和 Spark SQL Extensions 机制。
自定义 Ranger 插件
在 Ranger 中添加一个新服务的权限校验可分为两部分:第一部分是为 Ranger 增加新服务模块;第二部分是在新服务中增加 Ranger 权限校验插件。
● Ranger 增加新服务模块
Ranger 增加新服务模块是在 Ranger Admin Web UI 界面增加对应服务模块,用来为对应服务添加对应资源的授权策略。新服务模块增加可以分为以下三个步骤:
• 为新服务定义描述文件,文件名为 ranger-servicedef-< serviceName>.json,在描述文件中定义了服务的名字、在 ranger admin web 界面中显示的名称、新服务访问类定义、需要用来进行权限校验的资源列表和需要进行校验的访问类型列表等。
ranger-servicedef-< serviceName>.json 内容主要部分参数解析如下:
{
"id":"服务id,需要保证唯一",
"name":"服务名",
"displayName":"在Ranger Admin Web UI上显示的服务名",
"implClass":"在Ranger Admin内部用于访问新服务的实现类",
// 定义新服务用于权限校验的资源列表,如Hive中的database、table
"resources":[
{
"itemId": "资源id, 从1开始递增",
"name": "资源名",
"type": "资源类型,通常为string和path",
"level": "资源层级,同一层级的会在一个下拉框展示",
"mandatory": "是否为必选",
"lookupSupported": "是否支持检索",
"recursiveSupported": false,
"excludesSupported": true,
"matcher": "org.apache.ranger.plugin.resourcematcher.RangerDefaultResourceMatcher",
"validationRegEx":"",
"validationMessage": "",
"uiHint":"提示信息",
"label": "Hive Database",
"description": "资源描述信息"
}
],
// 定义资源需要进行校验的访问类型列表,如select、create
"accessTypes":[
{
"itemId": "访问类型id, 从1开始递增",
"name": "访问类型名称",
"label": "访问类型在Web界面上的显示名称"
}
],
"configs":[
{
"itemId": "配置参数id, 从1开始递增",
"name": "配置参数名称",
"type": "参数类型",
"mandatory": "是否必填",
"validationRegEx":"",
"validationMessage": "",
"uiHint":"提示信息",
"label": "在Web界面上的显示名称"
}
]
}
• 开发 Ranger 中新服务模块对应的实现类,并将该类名填写到 ranger-servicedef-< serviceName>.json 中 implClass 字段上。新服务模块的实现类需要继承抽象类 RangerBaseService,RangerBaseService 是 Ranger 中所有服务的基类,它定义了一组公共方法和属性,以便所有服务都可以共享和继承。RangerBaseService 提供了基本功能,如访问控制,资源管理和审计跟踪等。
开发新服务模块的实现类是比较容易的,通过继承 RangerBaseService 并实现 validateConfig 和 lookupResource 两个方法即可,validateConfig 方法是用来验证服务的配置是否正确,lookupResource 方法定义了加载资源的方法。
• 第一步和第二部完成后分别将配置文件 ranger-servicedef-< serviceName>.json 和新服务模块对应的实现类 jar 包放到 Ranger Admin 的 CLASSPATH 中,并使用 Ranger Admin 提供的 REST API 向 Ranger 注册定义的服务类型,这样就能在 Ranger Admin UI 界面看到新服务的模块并能通过界面配置对应权限控制。
● 新服务中增加 Ranger 权限校验插件
新服务中要实现 Ranger 的权限校验需要开发对应的权限控制插件并注册到新服务中,该插件实现的时候需要在服务中找到一个切入点来拦截资源的访问请求并调用 Ranger API 来授权访问。接下来介绍一下 Ranger 权限校验插件开发中比较重要的4个类:
• RangerBasePlugin:Ranger 权限校验的核心类,主要负责拉取策略、策略缓存更新及完成资源访问的权限校验
• RangerAccessResourceImpl:对鉴权资源进行封装的实现类,调用鉴权接口时需要构造这么一个类
• RangerAccessRequestImpl:请求资源访问的实现类,包含鉴权资源的封装对象、用户、用户组、访问类型等信息,调用鉴权接口 isAccessAllowed 时需要将 RangerAccessRequestImpl 作为参数传入
• RangerDefaultAuditHandler:审计日志的处理类
实现 Ranger 权限校验插件分为以下步骤:
• 编写目标类继承 RangerBasePlugin,通常只需要在目标类实现的构造方法中调用父类的构造函数并填入对应的服务类型名称和重写 RangerBasePlugin 的 init 方法并在重写的 init 方法中调用父类的 init 方法。
RangerBasePlugin 的 init 方法中实现了策略的拉取并会启动一个后台线程定时更新本地缓存的策略。
• 编写承上启下的类,用于配置在目标服务中能够拦截目标服务所有的资源请求并能调用 RangerBasePlugin 的 isAccessAllowed 方法进行资源请求鉴权。对于 Spark SQL 实现 Ranger 的权限校验来说我们基于 Spark SQL 的 Extensions 机制(后文会进行讲解),通过自定义一个 Spark Extensions注册到 Spark 中来在 SQL 语法解析阶段通过遍历生成的抽象语法树完成资源访问的权限校验。
Spark SQL Extensions 机制
Spark SQL Extensions 是在 SPARK-18127 中被引入,提供了一种灵活的机制,使得 Spark 用户可以在 SQL 解析的 Parser、Analyzer、Optimizer 以及 Planner 等阶段进行自定义扩展,包括自定义 SQL 语法解析、新增数据源等等。
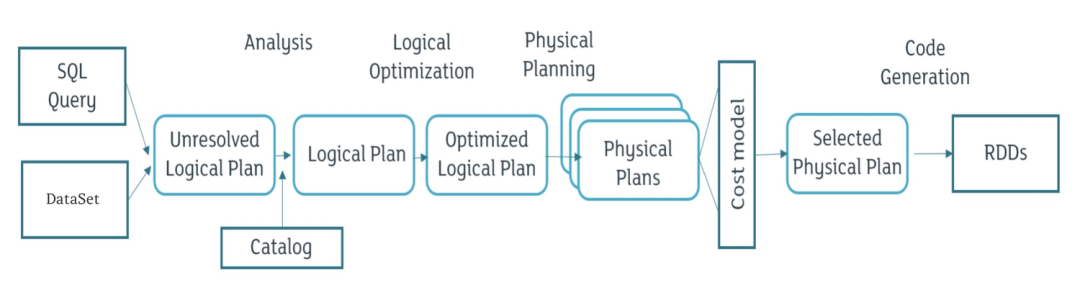
SparkSessionExtensions 为 Spark SQL Extensions 机制的核心类,SparkSessionExtensions 保存了用户自定义的扩展规则,包含以下方法:
• buildResolutionRules:构建扩展规则添加到 Analyzer 的 resolution 阶段
• injectResolutionRule:向 Analyzer 的 resolution 阶段注册扩展规则生成器
• buildPostHocResolutionRules:构建扩展规则添加到 Analyzer 的 post-hoc resolution 阶段
• injectPostHocResolutionRule:向 Analyzer 的 post-hoc resolution 阶段注册扩展规则生成器
• buildCheckRules:构建扩展检查规则,该规则将会在 analysis 阶段之后运行,用于检查 LogicalPlan 是否存在问题
• injectCheckRule:注册扩展检查规则生成器
• buildOptimizerRules:构建扩展优化规则,将在 optimizer 阶段被调用执行
• injectOptimizerRule:注册扩展优化规则生成器
• buildPlannerStrategies:构建扩展物理执行计划策略,用于将 LogicalPlan 转换为可执行文件
• injectPlannerStrategy:注册扩展物理执行计划策略生成器
• buildParser:构建扩展解析规则
• injectParser:注册扩展解析规则生成器
基于 Spark SQL Extensions 机制实现自定义规则会很容易,首先编写类实现 Function1[SparkSessionExtensions, Unit] ,SparkSessionExtensions 作为函数入参,调用 SparkSessionExtensions 对应方法将自定义的解析规则注册到对应的 SQL 解析阶段执行,然后将编写的类通过参数 spark.sql.extensions 指定注册到 Spark 中。
Spark SQL权限控制在数栈中的实践
Spark 在数栈中主要应用于离线数仓的场景,对离线数据进行批处理。大多数场景下数据大多都是存在业务库中的如 MySQL、Oracle 等,在数栈上会先使用 ChunJun 进行数据采集将数据从业务库同步到 Hive 库的 ODS 层,然后通过 Hive 或者 Spark 引擎进行数据的批处理计算,最后再通过 ChunJun 将结果数据同步到对应业务库中。
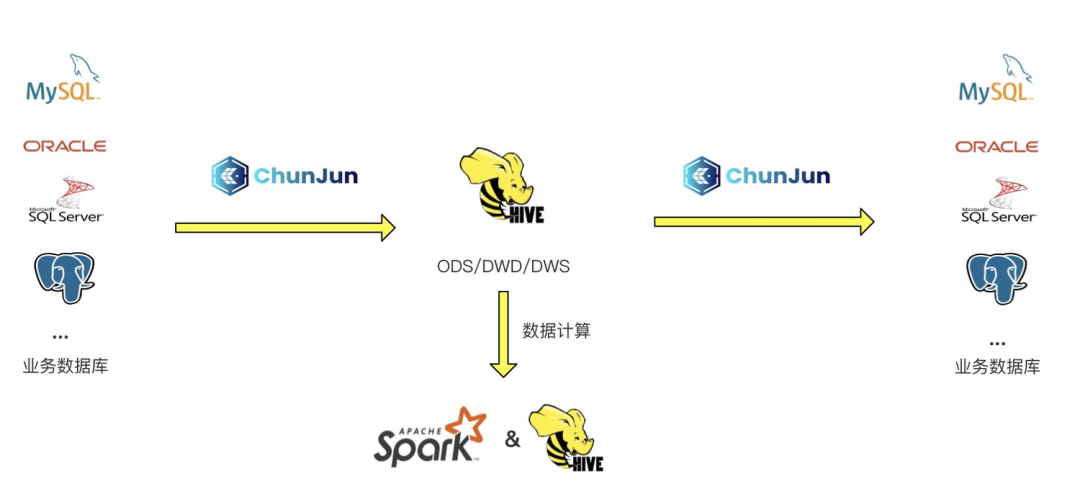
对应的业务库大多都是关系型数据库,每个关系型数据库也都已经具有非常完善的权限管理机制,在早期的数栈中是缺少对 Hive 上数据的安全管控的,这也就导致 Hive 上的数据可以被每个用户获取查看,缺少了数据隐私保护。
为了解决 Hive 数据安全的问题,我们选择了使用 Ranger 来对 Hive 进行权限控制。
Ranger 是一个非常全面的数据安全管理框架,它提供了 Web UI 供用户进行权限策略设置,使得 Ranger 更加易用。Ranger 安全相关的功能也十分丰富,管控力度更细,支持数据库表级别权限管理,也支持行级别过滤和数据脱敏等非常实用的功能。对 Ranger 进行扩展也比较灵活,在 Ranger 上能够很轻松实现一个新服务的权限管控。
在数栈上 Spark 用来处理 Hive 中的数据,Hive 使用 Ranger 进行了数据的权限管控,所以为了保证数据安全数栈基于 Ranger 自研了 Spark SQL 的权限管控插件。
上文我们提到为一个新服务自定义 Ranger 权限管控插件分为两部分来完成,第一部分是在 Ranger Admin Web UI 界面增加对应的服务模块,考虑到 Spark 只用来处理 Hive 中的数据所以在权限策略这个地方应该要和 Hive 保持一致,所以在 Spark SQL 基于 Ranger 实现权限控制插件时没有重复造轮子而是直接复用 HADOOP SQL 服务模块,和 Hive 共同使用同一套策略,所以我们只需要在 Spark 端开发 Ranger 的权限管理插件。
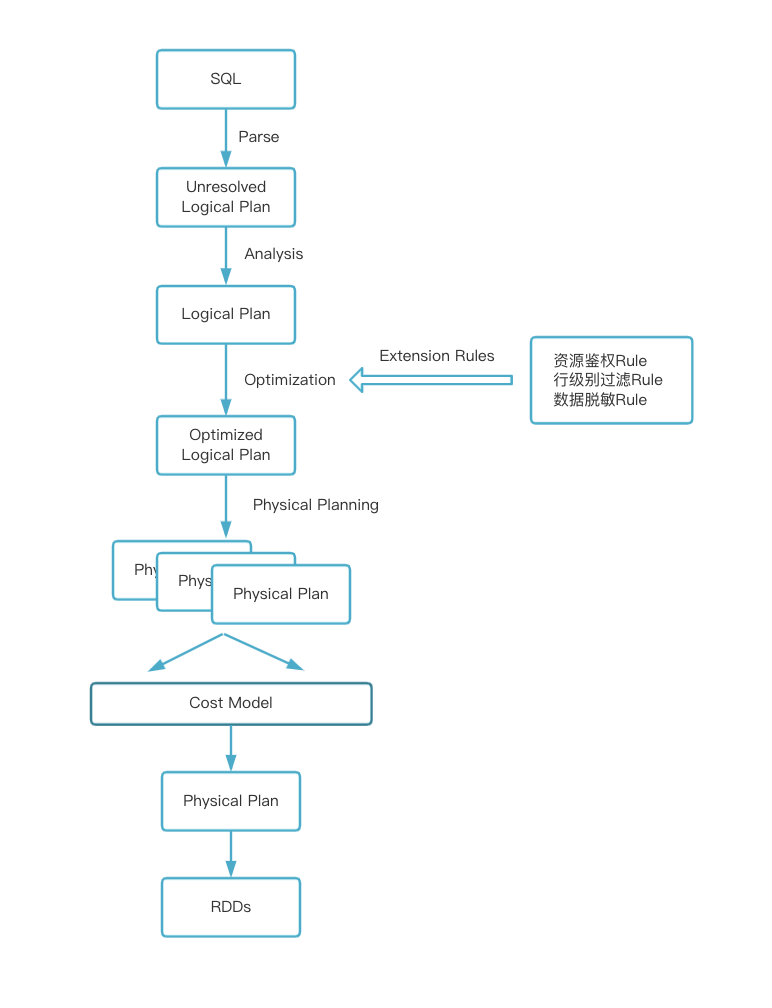
基于 Spark SQL Extensions 机制,我们编写了类 RangerSparkSQLExtension,并在该类中将实现好的鉴权 Rule、行级过滤 Rule 和数据脱敏 Rule 通过调用 SparkSessionExtensions.injectOptimizerRule 方法注册将到 SQL 解析的 Optimizer 阶段。
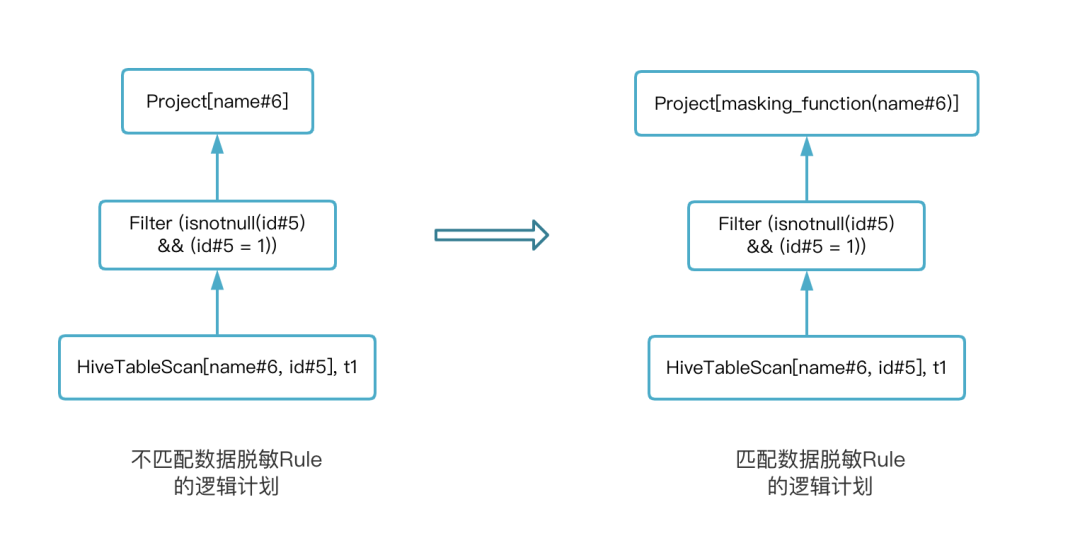
以数据脱敏 Rule 为例,当匹配到数据脱敏的 Rule 后,该 Rule 会为 Logical Plan 增加一个 Project 节点并增加 masking_function 函数调用的逻辑。通过下图展示匹配数据脱敏 Rule 前后的变化,以 select name from t1 where id = 1 为例:
总结
数栈一直致力于数据的安全和隐私保护,实现 Spark SQL 基于 Ranger 的权限控制是数栈在数据安全探索的其中一点。本文讲述了基于 Ranger 实现 Spark SQL 权限校验的原理,基于 Ranger 赋予了 Spark SQL 在权限管控方面,更强的管控力度、更丰富的能力。
未来在保证安全的前提下数栈将对性能进行进一步的优化,比如将权限校验 Rule 注册到 SQL 优化器上,可能会被执行多次增加,这样就会增加一些不必要的鉴权。期待大家对数栈的持续关注。
《数栈产品白皮书》:https://www.dtstack.com/resources/1004?src=szsm
《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001?src=szsm
想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szbky
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术qun」,交流最新开源技术信息,qun号码:30537511,项目地址:https://github.com/DTStack
提高数据的安全性和可控性,数栈基于 Ranger 实现的 Spark SQL 权限控制实践之路的更多相关文章
- python 全栈开发,Day108(客户管理之权限控制,客户管理之动态"一级"菜单,其他应用使用rbac组件,django static文件的引入方式)
一.客户管理之权限控制 昨天的作业,有很多不完善的地方 下载代码,基本实现权限验证 https://github.com/987334176/luffy_permission/archive/v1.2 ...
- 大数据技术之_19_Spark学习_03_Spark SQL 应用解析 + Spark SQL 概述、解析 、数据源、实战 + 执行 Spark SQL 查询 + JDBC/ODBC 服务器
第1章 Spark SQL 概述1.1 什么是 Spark SQL1.2 RDD vs DataFrames vs DataSet1.2.1 RDD1.2.2 DataFrame1.2.3 DataS ...
- 袋鼠云研发手记 | 开源·数栈-扩展FlinkSQL实现流与维表的join
作为一家创新驱动的科技公司,袋鼠云每年研发投入达数千万,公司80%员工都是技术人员,袋鼠云产品家族包括企业级一站式数据中台PaaS数栈.交互式数据可视化大屏开发平台Easy[V]等产品也在迅速迭代.在 ...
- 袋鼠云研发手记 | 数栈·开源:Github上400+Star的硬核分布式同步工具FlinkX
作为一家创新驱动的科技公司,袋鼠云每年研发投入达数千万,公司80%员工都是技术人员,袋鼠云产品家族包括企业级一站式数据中台PaaS数栈.交互式数据可视化大屏开发平台Easy[V]等产品也在迅速迭代.在 ...
- 数栈运维实例:Oracle数据库运维场景下,智能运维如何落地生根?
从马车到汽车是为了提升运输效率,而随着时代的发展,如今我们又希望用自动驾驶把驾驶员从开车这项体力劳动中解放出来,增加运行效率,同时也可减少交通事故发生率,这也是企业对于智能运维的诉求. 从人工运维到自 ...
- Molecule实现数栈至简前端开发新体验
Keep It Simple, Stupid. 这是开发人耳熟能详的 KISS 原则,也像是一句有调侃意味的善意提醒,提醒每个前端人,简洁易懂的用户体验和删繁就简的搭建逻辑就是前端开发的至简大道. 这 ...
- mysqldump 导出统一限制每张数据表导出的记录数
mysqldump 导出统一限制每张数据表导出的记录数 在工作过程中,需要将生产的数据导出到本地开发环境,我希望可以导出部分数据.而服务器数据量比较大(上千万),如果选择直接从服务器导出数据, 正在运 ...
- JVM 专题八:运行时数据区(三)虚拟机栈
2.虚拟机栈 1. 概述 1.1 虚拟机栈出现背景 由于跨平台性的设计,java的指令都是根据栈来设计的.不同平台CPU架构不同,所以不能设计为基于寄存器的. 优点是跨平台,指令集小,编译器容易实现, ...
- 袋鼠云出品!数栈UI 5.0全新体验升级,设计背后的故事
我们是袋鼠云数栈 UED 团队,致力于打造优秀的一站式数据中台产品.我们始终保持工匠精神,探索前端道路,为社区积累并传播经验价值. 前言 数栈作为云原⽣⼀站式⼤数据开发平台,从2016年发布第⼀个版本 ...
- 【资源】NOIP2013测试数据senior/junior 普及/提高 数据
https://yunpan.cn/cRSepfcG4XX3V 访问密码 48e1 NOIP2013测试数据senior/junior 普及/提高 数据都在了
随机推荐
- BUUCTF---Cipher1(playfair)
playfair Playfair密码原理以及该题解题步骤 Playfair密码(Playfair cipher 或 Playfair square)一种替换密码,1854年由查尔斯·惠斯通(Char ...
- [源码系列:手写spring] IOC第四节:Bean属性注入
主要内容 添加PropertyValue类表示Bean的属性. 为Bean定义对象BeanDefinition添加PropertyValues列表用来存储Bean的各种属性. Bean实例化时根据Pr ...
- verilog实现32位有符号流水乘法器
verilog实现32位有符号流水乘法器 1.4bit乘法流程 1.无符号X无符号二进制乘法器 以下为4bit乘法器流程(2X6) 0 0 0 0 0 0 1 0 (2) X 0 0 0 0 0 1 ...
- 如何使用 OpenAI Agents SDK 构建 MCP
1.概述 OpenAI Agents SDK 现已支持 MCP(模型上下文协议),这是 AI 互操作性的重大变革.这使开发人员能够高效地将 AI 模型连接到外部工具和数据源.本篇博客,笔者将指导使用 ...
- 实现Android键盘自适应
实现Android键盘自适应 unit Unit13; interface uses System.SysUtils, System.Types, System.UITypes, System.Cla ...
- springboot接口接收xml
对xml文件的操作也可以借助hutool的XmlUtil. 1. xml格式 <root> <deviceStatInfo onlineCount="64" of ...
- Metasploit(MSF)渗透测试之永恒之蓝实验
实验环境 前提:对方的445端口必须开放,首先要保证是能够访问到目标机器的,那么我们先ping一下目标机器,看网络是否连通 如果无法ping的话,对方机器必须要关闭防火墙,或许有其他方法在对方开启防火 ...
- should contain指令的用法,校验结果
上图案例 商品添加后,匹配"商品名称","现价","库存" 首先获取"商品名称","现价",&quo ...
- 探秘Transformer系列之(28)--- DeepSeek MLA
探秘Transformer系列之(28)--- DeepSeek MLA 目录 探秘Transformer系列之(28)--- DeepSeek MLA 0x00 概述 0x01 原理 1.1 问题 ...
- 经典常用SQL查询语句和常见问题
一.基础 1.常用sql: ------------------------ // mysql改root密码 mysqladmin -u用户名 -p旧密码 password 新密码 # ---more ...