MongoDB入门实战教程(8)
前面我们学习了模型设计中的内嵌模式与引用模式的使用,本篇我们来看看在模型设计中如何套用常见的设计模式来降低设计难度,提高查询效率。
1 MongoDB也有设计模式?
在使用C#/Java等开发语言的时候,我们通常会学习面向对象和设计模式来提高设计水平,使得开发的应用程序具有较高的可扩展性 和 可读性。
在MongoDB的模型设计中,我们都了解到文档模型是一个无范式和无思维定式的模型,那么,有没有一些设计的套路可以像23种设计模式一样我们可以快速套用呢?
答案是:有的。
基于前人的学习和经验,我们可以适时套用,从而优化我们的文档模型设计。

一个好的设计模式可以显著地:
(1)提升数据读写的效率;
(2)降低资源的需求;
2 组织结构类模式
预聚合
适用场景:
(1)热销榜:某个商品今天卖了多少,这个星期又卖了多少?...
(2)电影排行:观影者、场次统计...
(3)传统解决方案:通过聚合计算...
痛点总结:
消耗资源多,聚合(统计)时间较长。
解决方案:
一句话概括:使用预聚合字段!
即 在模型中直接增加统计字段,每次更新数据时同事更新统计值。这是一种典型的以空间换时间的设计,特别适合需要较长聚合(统计)操作的场景。
示例模型:
{
product: "Bike",
sku: "abc123456",
quantitiy: 20394,
daily_sales: 40,
weekly_sales: 302,
monthly_sales: 1419
}
db.inventory.update({ _id : 123 },{ $inc:
{
quantity: -1,
daily_sales: 1,
weekly_sales: 1,
monthly_sales: 1,
}
})
分桶
适用场景:
物联网场景下的海量监控数据、时序数据
比如:智慧城市、智慧交通场景下的监控数据
痛点总结:
数据点采集频繁,数据量太多,索引也很大!
解决方案:
一句话概括:分桶!
即 利用文档内嵌数组,将一个时间段的数据聚合到一个文档里。
示例模型:
// 分桶前:每分钟一条
{
"_id" : "20160101050000:CA2790",
"icao" : "CA2790",
"callsign" : "CA2790",
"ts" : ISODate("2016-01-01T05:00:00.000+0000"),
"events" : {
"a" : 31418,
"b" : 173,
"p" : [115, -134],
"s" : 91,
"v" : 80
}
} // 分桶后:一小时一条
{
"_id" : "20160101050000:WG9943",
"icao" : "WG9943",
"ts" : ISODate("2016-01-01T05:00:00.000+0000"),
"events" : [
{
"a" : 24293, "b" : 319, "p" : [41, 70], "s" : 56,
"t" : ISODate("2016-01-01T05:00:00.000+0000“)
},
{
"a" : 33663, "b" : 134, "p" : [-38, -30], "s" : 385,
"t" : ISODate("2016-01-01T05:00:01.000+0000“)
},
...
]
}
3 表现形式类模式
列转行
适用场景:
(1)产品(如sku)有很多属性,如 color、size、dimensions等
(2)多语言(多国家)属性等
痛点总结:
文档中有很多类似的字段,且会用于组合查询,需要建立很多的索引。
解决方案:
一句话概括:列转行!
即 将列 转化为 数组,一个索引解决所有查询问题。
示例模型:
{
title: "Dunkirk",
...
release_USA: "2017/07/23", // 需要建立索引
release_UK: "2017/08/01", // 需要建立索引
release_France: "2017/08/01", // 需要建立索引
release_Festival_San_Jose: "2017/07/22" // 需要建立索引
}
// 列转行后
{
title: "Dunkirk",
...
releases: [
{ country: "USA", date:"2017/07/23"},
{ country: "UK", date:"2017/08/01"}
]
}
// 只需要建两个索引即可
db.movies.createIndex({“releases.country”:1, “releases.date”:1})
文档版本
适用场景:
任何有版本衍变的数据库
痛点总结:
文档模型格式多,无法知道其合理性;
升级的时候需要更新太多的文档;
解决方案:
一句话概括:增加一个版本号字段!
即 快速过滤掉不需要升级的文档,升级的时候对不同版本的文档做不同的处理。
示例模型:
// 优化前:
// v1.0
{
"_id" : ObjectId("5de26f197edd62c5d388babb"),
"name" : "TJ",
"company" : "Tapdata"
} // v2.0
{
"_id" : ObjectId("5de26f197edd62c5d388babb"),
"name" : "TJ",
"company" : "Tapdata",
"wechat": "tjtang826"
} // 优化后的v2.0
{
"_id" : ObjectId("5de26f197edd62c5d388babb"),
"name" : "TJ",
"company" : "Tapdata",
"wechat": "tjtang826",
"schema_version": "2.0"
}
4 数据访问类模式
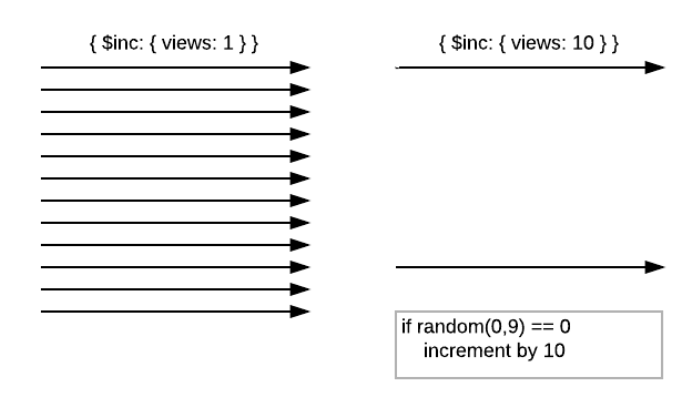
近似处理
适用场景:
(1)网页计数(每次访问一个页面都会产生一次DB计数更新操作)
(2)各种结果不需要准确的排名(统计结果的准确性并不是十分的重要)
痛点总结:
写入太频繁,消耗系统资源
解决方案:
一句话概括:近似处理(计算)!
即 间隔写入,每隔10次 或 100次,大量减少写入需求。
5 总结
本文简单介绍了MongoDB的模型设计中的三大类常用设计模式:表现形式类、数据访问类 和 组织结构类。通过学习这些设计模式,使我们可以在模型设计场景中恰当地套用这些设计模式,从而达到提升数据读写效率 和 降低资源的需求,最终得到一个合适的文档模型。
下一篇,我们会学习MongoDB的索引相关知识,善用索引提高查询效率。
本系列教程目录:
参考资料
唐建法,《MongoDB高手课》(极客时间)
郭远威,《MongoDB实战指南》(图书)

△推荐订阅学习

MongoDB入门实战教程(8)的更多相关文章
- Kafka入门实战教程(7):Kafka Streams
1 关于流处理 流处理平台(Streaming Systems)是处理无限数据集(Unbounded Dataset)的数据处理引擎,而流处理是与批处理(Batch Processing)相对应的.所 ...
- ZooKeeper入门实战教程(一)-介绍与核心概念
1.ZooKeeper介绍与核心概念1.1 简介ZooKeeper最为主要的使用场景,是作为分布式系统的分布式协同服务.在学习zookeeper之前,先要对分布式系统的概念有所了解,否则你将完全不知道 ...
- Node+Express+MongoDB+Socket.io搭建实时聊天应用实战教程(一)--MongoDB入门
前言 本文并不是网上流传的多少天学会MongoDB那种全面的教程,而意在总结这几天使用MongoDB的心得,给出一个完整的Node+Express+MongoDB+Socket.io搭建实时聊天应用实 ...
- Node+Express+MongoDB + Socket.io搭建实时聊天应用实战教程(二)--node解析与环境搭建
前言 本来开始写博客的时候只是想写一下关于MongoDB的使用总结的,后来觉得还不如干脆写一个node项目实战教程实战.写教程一方面在自己写的过程中需要考虑更多的东西,另一方面希望能对node入门者有 ...
- MongoDB入门必读(概念与实战并重)
MongoDB入门必读(概念与实战并重) 一.概述 MongoDB是一个基于分布式文件存储的数据库开源项目.由C++语言编写.旨在为WEB应用提供可护展的高性能数据存储解决方案. MongoDB是一个 ...
- mybatis实战教程(mybatis in action),mybatis入门到精通
转自:http://www.yihaomen.com/article/java/302.htm (读者注:其实这个应该叫做很基础的入门一下下,如果你看过hibernate了那这个就非常的简单) (再加 ...
- mybatis实战教程(mybatis in action),mybatis入门到精通(转)
转自:http://www.yihaomen.com/article/java/302.htm (读者注:其实这个应该叫做很基础的入门一下下,如果你看过Hibernate了那这个就非常的简单) (再加 ...
- mongodb入门教程二
title: mongodb入门教程二 date: 2016-04-07 10:33:02 tags: --- 上一篇文章说了mongodb最基本的东西,这边博文就在深入一点,说一下mongo的一些高 ...
- mongodb入门教程
title: mongodb入门教程 date: 2016-04-06 14:47:18 tags: --- 为什么要认识呢,因为这玩意就一傻逼 借用一下百科的介绍 MongoDB 是一个介于关系数据 ...
- MongoDb 入门教程
MongoDb 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的. 它是可扩展的高性能数据存储解决方案,经常被用于非关系型数据的存储,能存储海量的数据. 常 ...
随机推荐
- 冒泡排序--java进阶day06
1.冒泡排序 https://kdocs.cn/l/ciMkwngvaWfz?linkname=150996835 我们会发现上图排序的样子非常像之前打印的倒三角,所以,冒泡排序也需要使用循环嵌套 2 ...
- 【Linux】3.8 Linux磁盘分区、挂载
Linux磁盘分区.挂载 1. 分区方式 mbr分区 最多支持四个主分区 系统只能安装在主分区 扩展分区要占一个主分区 MBR最大只支持2TB,但拥有最好的兼容性 gpt分区 支持无限多个主分区(但操 ...
- 【Guava】集合工具类-Immutable&Lists&Maps&Sets
Immutable 如<Effective Java>Item1)所述,在设计类的时候,倾向优先使用静态工厂方法(static factory method)而非构造函数(construc ...
- Codeforces Round 952 (Div. 4)
知识点模块 1.一个正方体x,y,z里面可以放多少个边长为a,b,c的长方体 ans=(x-a+1)*(y-b+1)*(z-c+1) 题解模块 A.Creating Words 交换两个字母的首字母即 ...
- docker发布简单python服务
进入机器创建一个目录mkdir dockerbuild1.编写简单flask代码vi flaskapp.pyfrom flask import Flaskimport os app = Flask(_ ...
- QT 可绑定属性 QProperty QObjectBindableProperty QObjectComputedProperty,简化信号、槽(SIGNAL、SLOT)机制的方法
QT提供的可绑定属性是指这些属性可以绑定到其他值或表达式上(通常是 C++ lambda 表达式).如果属性是通过表达式进行绑定,该属性会跟随表达式自动更新.可绑定属性由 QProperty 类和 Q ...
- eolinker响应预处理/规则校验:js正则写法注意事项
JS的正则表达式的写法,需要对原有正则表达式进行适当加工才可正常使用 如:(正则表达式规则取到"/did1280064/Login") 常规的正则表达式为"did(\d+ ...
- JVM 的 TLAB(Thread-Local Allocation Buffer)是什么?
JVM 的 TLAB(Thread-Local Allocation Buffer)是什么? TLAB(Thread-Local Allocation Buffer)简介 TLAB(Thread-Lo ...
- 极客时间上新 .NET + AI 体系课
课程特色 1️⃣ 全网首个.NET+AI体系化课程(没有之一!) 2️⃣ Semantic Kernel + Kernel Memory 核心知识全覆盖 3️⃣ 每课时基于Polyglot Noteb ...
- Ubuntu堡垒机搭建与设备管理指南
以下是基于Ubuntu系统搭建堡垒机并集成设备管理的详细步骤和注意事项: 一.堡垒机搭建步骤 系统准备 sudo apt update && sudo apt upgrade -y s ...