35.2K star!双链笔记+知识图谱+本地优先,这款开源知识管理神器绝了!
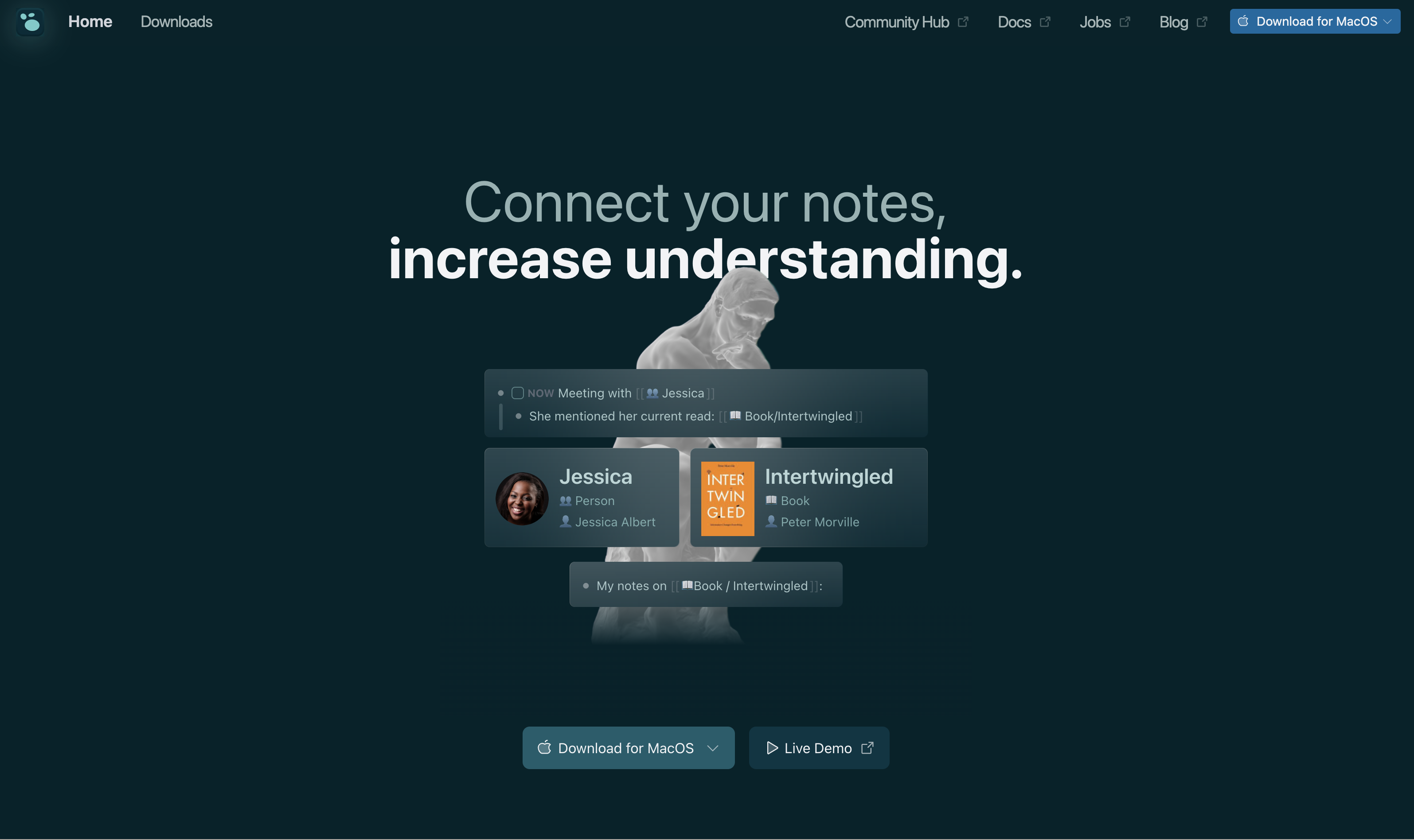

一款融合「双链笔记+知识图谱+本地优先」理念的开源知识管理工具,支持Markdown/Org-mode双格式,打造你的第二大脑!
项目介绍
"Logseq 是一个注重隐私、开源的知识管理平台,采用大纲笔记和双向链接构建个人知识库,支持PDF标注、任务管理、白板协作等场景,数据完全存储在用户本地设备。"
这款由Clojure语言开发的开源工具,正在全球范围内掀起知识管理革命。它不仅完美支持中文,还通过独特的「块引用」设计,让知识碎片像乐高积木般自由重组!
核心功能亮点
知识神经元网络
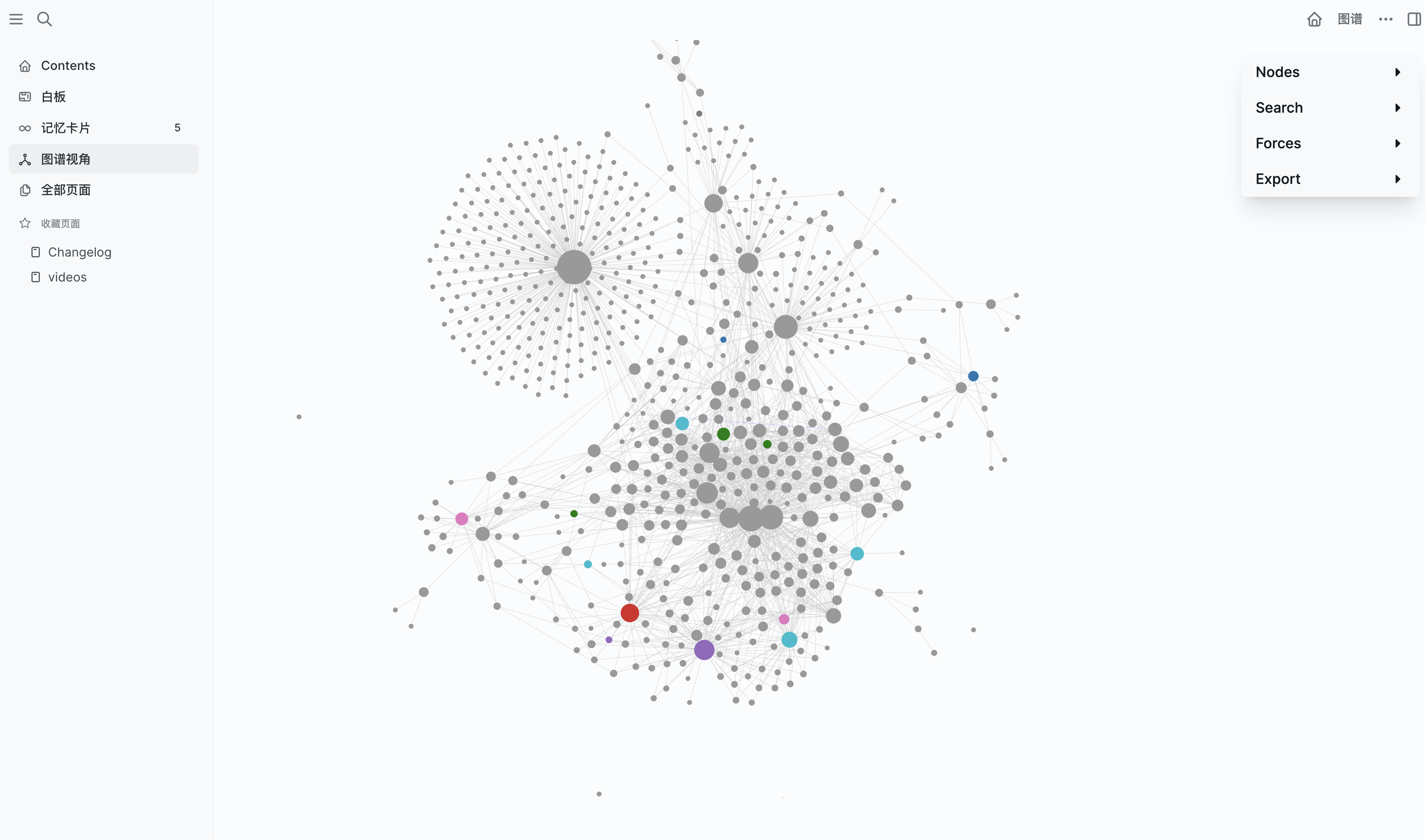

双向链接自动生成知识图谱 块级引用实现知识点精准关联 每日日志自动创建,捕捉灵感不遗漏
数据主权卫士
本地Markdown文件存储 端到端加密同步(可选) Git版本控制支持
学术研究利器
PDF直接标注与批注 文献引用自动生成 Zotero集成支持
智能扩展生态
插件市场自由扩展 API接口开放对接 自定义CSS主题
技术架构解析
| 模块 | 技术栈 | 特性优势 |
|---|---|---|
| 核心引擎 | Clojure/Script | 函数式编程保障稳定性 |
| 数据存储 | Datomic + Markdown | 时序数据库+纯文本双保险 |
| 界面框架 | React + Reagent | 高性能虚拟DOM渲染 |
| 同步方案 | Git + 自研同步协议 | 版本控制+实时协作两不误 |
| 扩展体系 | Plugin API + npm | JavaScript生态无缝对接 |
实战应用场景
案例1:程序员知识库搭建

案例2:学术论文管理


导入PDF文献自动解析 高亮重点段落生成知识卡片 通过白板模式构建理论框架 导出LaTeX格式论文草稿
案例3:个人目标管理

使用高级查询语法追踪逾期任务
同类项目对比
| Logseq | Notion | Obsidian | Roam Research | |
|---|---|---|---|---|
| 数据存储 | 本地优先 | 云端存储 | 本地优先 | 云端存储 |
| 知识图谱 | 动态生成 | 有限支持 | 插件实现 | 原生支持 |
| 移动端体验 | 渐进式Web应用 | 原生APP | 混合应用 | 无移动端 |
| 开源协议 | AGPLv3 | 闭源 | 闭源商业 | 闭源商业 |
| 中文支持 | 完整汉化 | 官方汉化 | 社区汉化 | 无官方汉化 |
| 学习曲线 | 中等 | 简单 | 中等 | 陡峭 |
知识管理全家桶推荐
Obsidian(黑曜石笔记):闭源双链笔记,插件生态丰富 Trilium:树状结构知识库,支持自托管 思源笔记:国产开源笔记,支持块级编辑 Joplin:跨平台加密笔记,支持Markdown Heptabase:白板式知识管理,视觉化思考
小贴士:知识工具不在多而在精,建议先深度使用1-2款工具建立个人系统!
项目界面
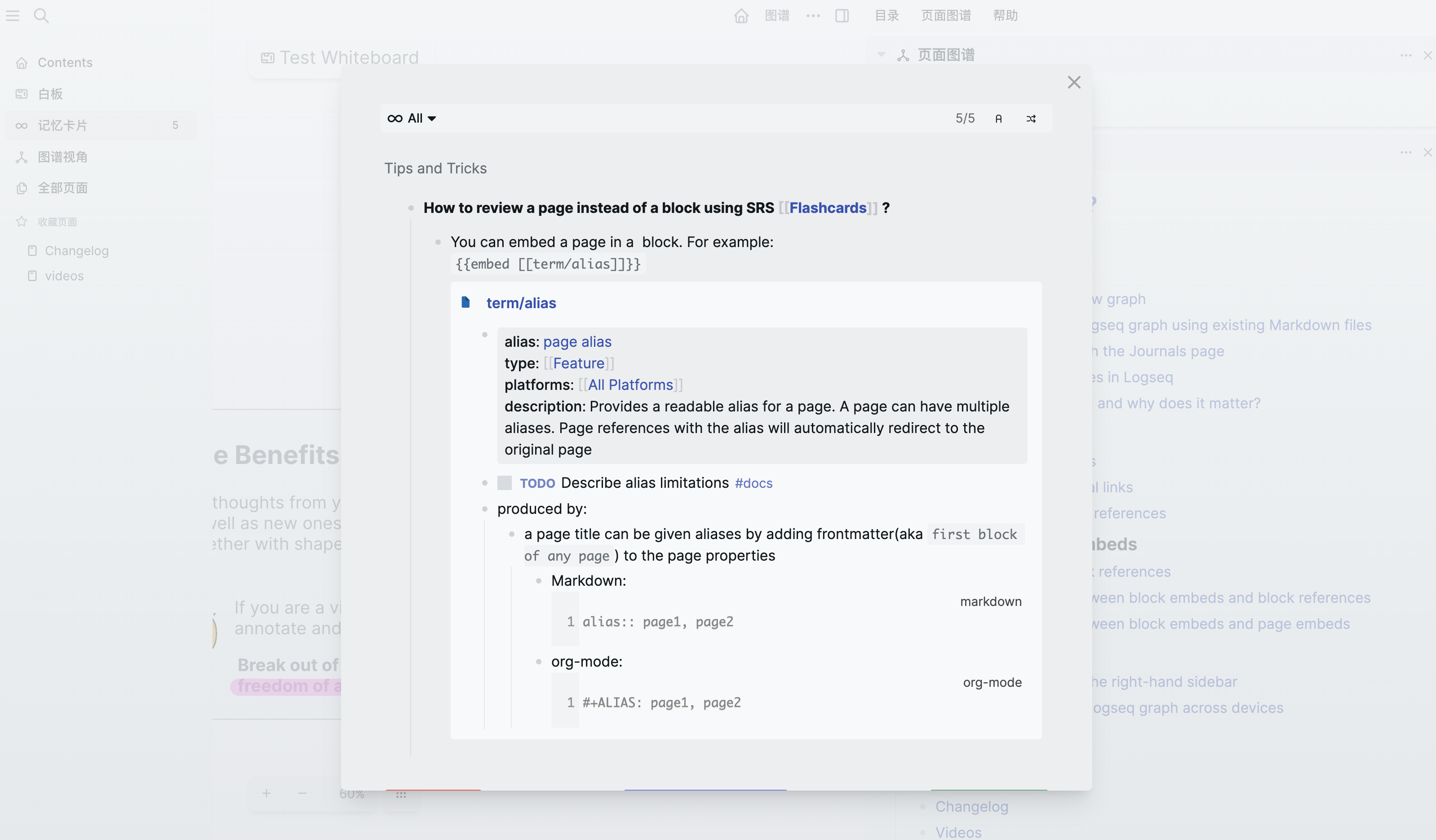
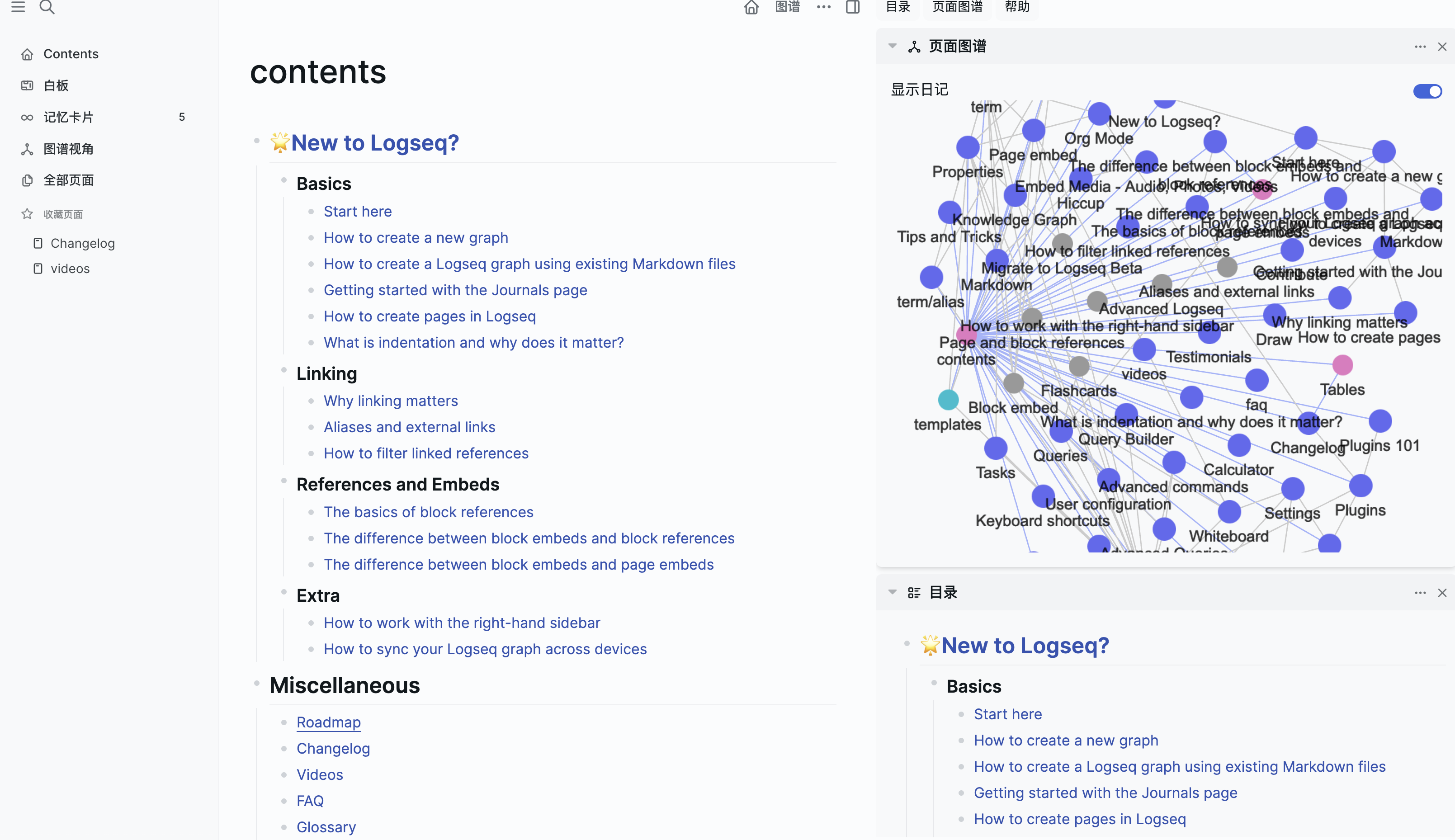
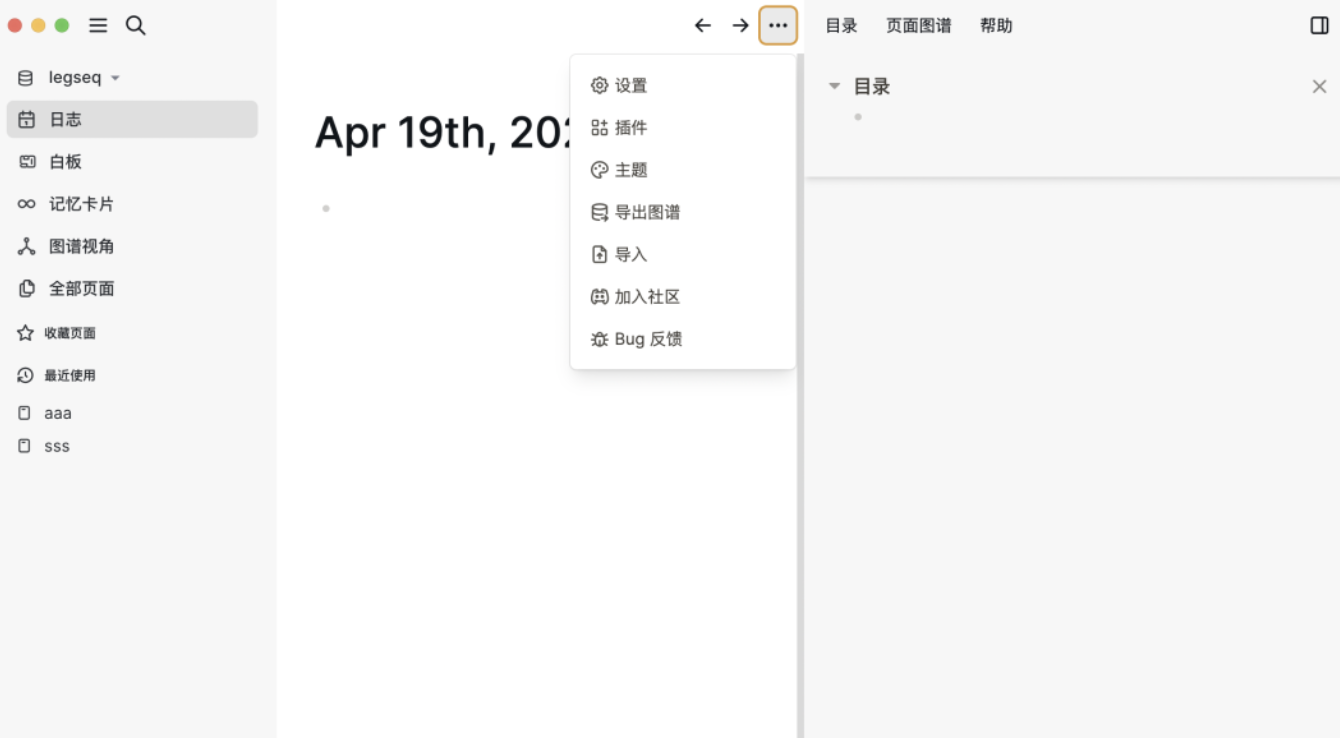
项目地址
https://github.com/logseq/logseq
35.2K star!双链笔记+知识图谱+本地优先,这款开源知识管理神器绝了!的更多相关文章
- 如何系统学习知识图谱-15年+IT老兵的经验分享
一.前言 就IT而言,胖子哥算是老兵,可以去猝死的年纪,按照IT江湖猿龄的规矩,也算是到了耳顺之年:而就人工智能而言,胖子哥还是新人,很老的新人,深度学习.语音识别.人脸识别,知识图谱,逐个的学习了一 ...
- 1. 通俗易懂解释知识图谱(Knowledge Graph)
1. 通俗易懂解释知识图谱(Knowledge Graph) 2. 知识图谱-命名实体识别(NER)详解 3. 哈工大LTP解析 1. 前言 从一开始的Google搜索,到现在的聊天机器人.大数据风控 ...
- 知识图谱+Recorder︱中文知识图谱API与工具、科研机构与算法框架
目录 分为两个部分,笔者看到的知识图谱在商业领域的应用,外加看到的一些算法框架与研究机构. 文章目录 @ 一.知识图谱商业应用 01 唯品金融大数据 02 PlantData知识图谱数据智能平台 03 ...
- ERNIE:知识图谱结合BERT才是「有文化」的语言模型
自然语言表征模型最近受到非常多的关注,很多研究者将其视为 NLP 最重要的研究方向之一.例如在大规模语料库上预训练的 BERT,它可以从纯文本中很好地捕捉丰富的语义模式,经过微调后可以持续改善不同 N ...
- ACL2016信息抽取与知识图谱相关论文掠影
实体关系推理与知识图谱补全 Unsupervised Person Slot Filling based on Graph Mining 作者:Dian Yu, Heng Ji 机构:Computer ...
- 2. 知识图谱-命名实体识别(NER)详解
1. 通俗易懂解释知识图谱(Knowledge Graph) 2. 知识图谱-命名实体识别(NER)详解 3. 哈工大LTP解析 1. 前言 在解了知识图谱的全貌之后,我们现在慢慢的开始深入的学习知识 ...
- CCKS 2018 | 最佳论文:南京大学提出DSKG,将多层RNN用于知识图谱补全
作者:Lingbing Guo.Qingheng Zhang.Weiyi Ge.Wei Hu.Yuzhong Qu 2018 年 8 月 14-17 日,主题为「知识计算与语言理解」的 2018 全国 ...
- 百度大脑UNIT3.0详解之知识图谱与对话
如今,越来越多的企业想要在电商客服.法律顾问等领域做一套包含行业知识的智能对话系统,而行业或领域知识的积累.构建.抽取等工作对于企业来说是个不小的难题,百度大脑UNIT3.0推出「我的知识」版块专门为 ...
- 知识图谱与Bert结合
论文题目: ERNIE: Enhanced Language Representation with Informative Entities(THU/ACL2019) 本文的工作也是属于对BERT锦 ...
- 哈工大知识图谱(Knowledge Graph)课程概述
一.什么是知识图谱 知识(Knowledge)可以理解为 精炼的数据,知识图谱(Knowledge Graph)即是对知识的图形化表示,本质上是一种大规模语义网络 (semantic network) ...
随机推荐
- JMeter调用python脚本
JMeter调用python脚本 前提 具备python环境 具备jdk环境 一.编写python脚本 python脚本如下: import random # 随机一个 1~100 的随机数 prin ...
- Java 将 RTF 转换为Word、PDF、HTML、图片
RTF文档因其跨平台兼容性而广泛使用,但有时在不同的应用场景可能需要特定的文档格式.例如,Word文档适合编辑和协作,PDF文档适合打印和分发,HTML文档适合在线展示,图片格式则适合社交媒体分享.因 ...
- Linux驱动---设备驱动模型
目录 一.简介 二.驱动模型 2.1.总线 2.2.设备 2.3.驱动 三.设备树 3.1.设备树简介 3.2.设备树格式 3.3.节点格式 3.4.节点属性 四.设备树API函数 4.1获取设备节点 ...
- flutter-真机调试ios Traceback (most recent call last)
1 Traceback (most recent call last): 2 File "/tmp/C5FDB25B-C7F4-462E-8AC9-7FF9D1A50F21/fruitstr ...
- 《Vue2 框架第二课:组件结构与模板语法详解》
写在开头:Vue.js 是一个流行的前端框架,广泛应用于构建用户界面和单页应用(SPA).然而,需要注意的是,Vue2 已经于 2023 年底 正式停止维护.这意味着官方团队将不再为 Vue2 提供功 ...
- 【FAQ】HarmonyOS SDK 闭源开放能力 —Live View Kit (1)
1.问题描述: 客户端创建实况窗后,通过Push kit更新实况窗内容,这个过程是自动更新的还是客户端解析push消息数据后填充数据更新?客户端除了接入Push kit和创建实况窗还需要做什么工作? ...
- redis - [07] 数据类型
redis是一个开源(BSD许可)的,内存中的数据结构存储系统,可以用作数据库.缓存和消息中间件MQ.它支持多种类型的数据结构,如字符串(String).散列(Hash).列表(List).集合( ...
- DOCKER20231217: 容器引擎Docker
1.1 Docker简介 1.1.1 什么是Docker? 一种轻量级的操作系统虚拟化技术,基于Go语言实现的开源容器项目,诞生于2013年,最初发起者是dotCloud公司(现 Docker Inc ...
- c++常量引用,通过被引用变量修改数据无法同步到引用
正常情况下被引用的对象改变,常量引用的值也跟着改变.i和j是同一个对象,所以是同步的: int i = 42; const int& j = i; i = 43; cout << ...
- Vue2/Vue3 项目生产环境开启 vue devtools 插件线上调试 vue 组件
说到 vue 项目的调试工具,必然少不了 "vue devtools 插件",此插件就像"手术刀"一样,是开发环境下的一个利器,生产环境一般情况没办法使用. 要 ...