vivo Pulsar 万亿级消息处理实践(3)-KoP指标异常修复
作者:vivo 互联网大数据团队- Chen Jianbo
本文是《vivo Pulsar万亿级消息处理实践》系列文章第3篇。
Pulsar是Apache基金会的开源分布式流处理平台和消息中间件,它实现了Kafka的协议,可以让使用Kafka API的应用直接迁移至Pulsar,这使得Pulsar在Kafka生态系统中更加容易被接受和使用。KoP提供了从Kafka到Pulsar的无缝转换,用户可以使用Kafka API操作Pulsar集群,保留了Kafka的广泛用户基础和丰富生态系统。它使得Pulsar可以更好地与Kafka进行整合,提供更好的消息传输性能、更强的兼容性及可扩展性。vivo在使用Pulsar KoP的过程中遇到过一些问题,本篇主要分享一个分区消费指标缺失的问题。
系列文章:
文章太长?1分钟看图抓住核心观点
一、问题背景
在一次版本灰度升级中,我们发现某个使用KoP的业务topic的消费速率出现了显著下降,具体情况如下图所示:
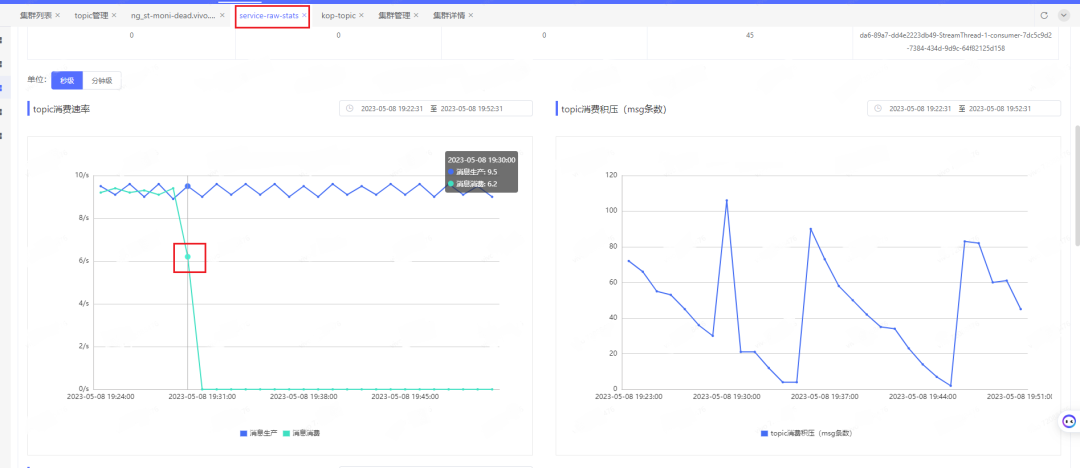
什么原因导致正常的升级重启服务器会出现这个问题呢?直接查看上报采集的数据报文:
kop_server_MESSAGE_OUT{group="",partition="0",tenant="kop",topic="persistent://kop-tenant/kop-ns/service-raw-stats"} 3
kop_server_BYTES_OUT{group="",partition="0",tenant="kop",topic="persistent://kop-tenant/kop-ns/service-raw-stats"} 188我们看到,KoP消费指标kop_server_MESSAGE
_OUT、kop_server_BYTES_OUT是有上报的,但指标数据里的group标签变成了空串(缺少消费组名称),分区的消费指标就无法展示了。是什么原因导致了消费组名称缺失?
二、问题分析
1、找到问题代码
我们去找下这个消费组名称是在哪里获取的,是否逻辑存在什么问题。根据druid中的kop_subscription对应的消费指标kop_server_
MESSAGE_OUT、kop_server_BYTES_OUT,找到相关代码如下:
private void handleEntries(final List<Entry> entries,
final TopicPartition topicPartition,
final FetchRequest.PartitionData partitionData,
final KafkaTopicConsumerManager tcm,
final ManagedCursor cursor,
final AtomicLong cursorOffset,
final boolean readCommitted) {
....
// 处理消费数据时,获取消费组名称
CompletableFuture<String> groupNameFuture = requestHandler
.getCurrentConnectedGroup()
.computeIfAbsent(clientHost, clientHost -> {
CompletableFuture<String> future = new CompletableFuture<>();
String groupIdPath = GroupIdUtils.groupIdPathFormat(clientHost, header.clientId());
requestHandler.getMetadataStore()
.get(requestHandler.getGroupIdStoredPath() + groupIdPath)
.thenAccept(getResultOpt -> {
if (getResultOpt.isPresent()) {
GetResult getResult = getResultOpt.get();
future.complete(new String(getResult.getValue() == null
? new byte[0] : getResult.getValue(), StandardCharsets.UTF_8));
} else {
// 从zk节点 /client_group_id/xxx 获取不到消费组,消费组就是空的
future.complete("");
}
}).exceptionally(ex -> {
future.completeExceptionally(ex);
return null;
});
returnfuture;
});
// this part is heavyweight, and we should not execute in the ManagedLedger Ordered executor thread
groupNameFuture.whenCompleteAsync((groupName, ex) -> {
if (ex != null) {
log.error("Get groupId failed.", ex);
groupName = "";
}
.....
// 获得消费组名称后,记录消费组对应的消费指标
decodeResult.updateConsumerStats(topicPartition,
entries.size(),
groupName,
statsLogger);代码的逻辑是,从requestHandler的currentConnectedGroup(map)中通过host获取groupName,不存在则通过MetadataStore(带缓存的zk存储对象)获取,如果zk缓存也没有,再发起zk读请求(路径为/client_group_id/host-clientId)。读取到消费组名称后,用它来更新消费组指标。从复现的集群确定走的是这个分支,即是从metadataStore(带缓存的zk客户端)获取不到对应zk节点/client_group_id/xxx。
2、查找可能导致zk节点/client_group_id/xxx节点获取不到的原因
有两种可能性:一是没写进去,二是写进去但是被删除了。
@Override
protected void handleFindCoordinatorRequest(KafkaHeaderAndRequest findCoordinator,
CompletableFuture<AbstractResponse> resultFuture) {
...
// Store group name to metadata store for current client, use to collect consumer metrics.
storeGroupId(groupId, groupIdPath)
.whenComplete((stat, ex) -> {
if (ex != null) {
// /client_group_id/xxx节点写入失败
log.warn("Store groupId failed, the groupId might already stored.", ex);
}
findBroker(TopicName.get(pulsarTopicName))
.whenComplete((node, throwable) -> {
....
});
});
...从代码看到,clientId与groupId的关联关系是通过handleFindCoordinatorRequest(FindCoordinator)写进去的,而且只有这个方法入口。由于没有找到warn日志,排除了第一种没写进去的可能性。看看删除的逻辑:
protected void close(){
if (isActive.getAndSet(false)) {
...
currentConnectedClientId.forEach(clientId -> {
String path = groupIdStoredPath + GroupIdUtils.groupIdPathFormat(clientHost, clientId);
// 删除zk上的 /client_group_id/xxx 节点
metadataStore.delete(path, Optional.empty())
.whenComplete((__, ex) -> {
if (ex != null) {
if (ex.getCause() instanceof MetadataStoreException.NotFoundException) {
if (log.isDebugEnabled()) {
log.debug("The groupId store path doesn't exist. Path: [{}]", path);
}
return;
}
log.error("Delete groupId failed. Path: [{}]", path, ex);
return;
}
if (log.isDebugEnabled()) {
log.debug("Delete groupId success. Path: [{}]", path);
}
});
});
}
}删除是在requsetHandler.close方法中执行,也就是说连接断开就会触发zk节点删除。
但有几个疑问:
/client_group_id/xxx 到底是干嘛用的?消费指标为什么要依赖它
为什么要在handleFindCoordinatorRequest写入?
节点/client_group_id/xxx为什么要删除,而且是在连接断开时删除,删除时机是否有问题?
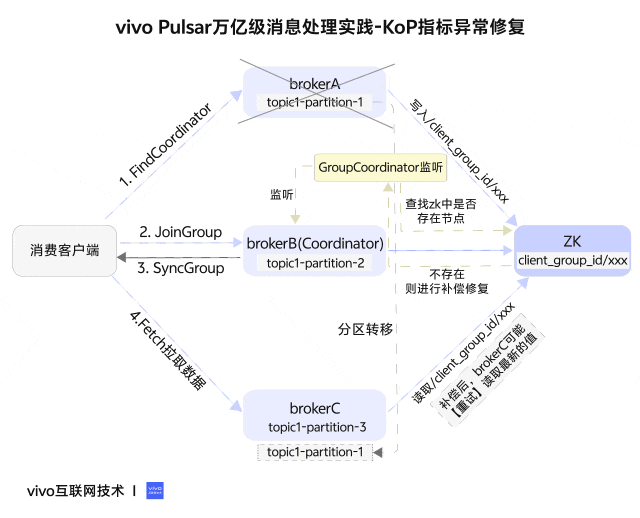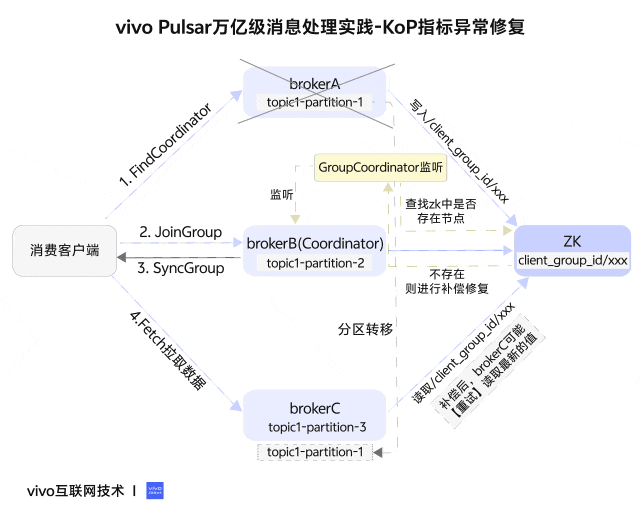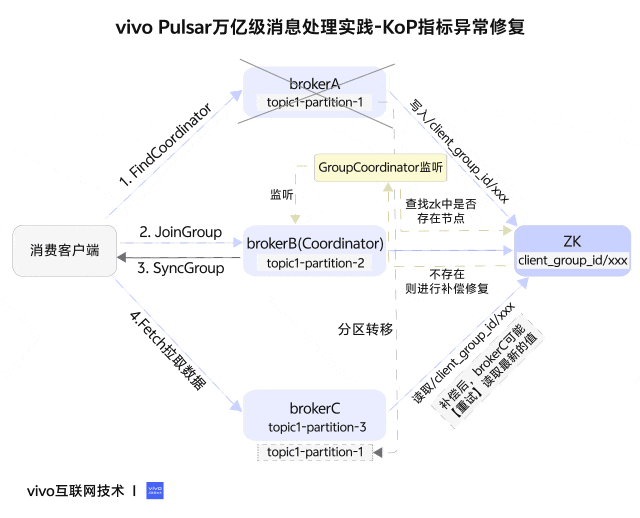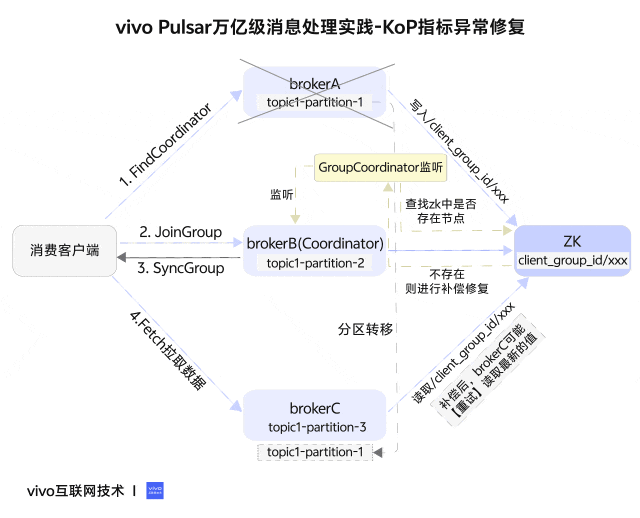
首先回答第1个问题,通过阅读代码可以知道,/client_group_id/xxx 这个zk节点是用于在不同broker实例间交换数据用的(相当redis cache),用于临时存放IP+clientId与groupId的映射关系。由于fetch接口(拉取数据)的request没有groupId的,只能依赖加入Group过程中的元数据,在fetch消费时才能知道当前拉数据的consumer是哪个消费组的。
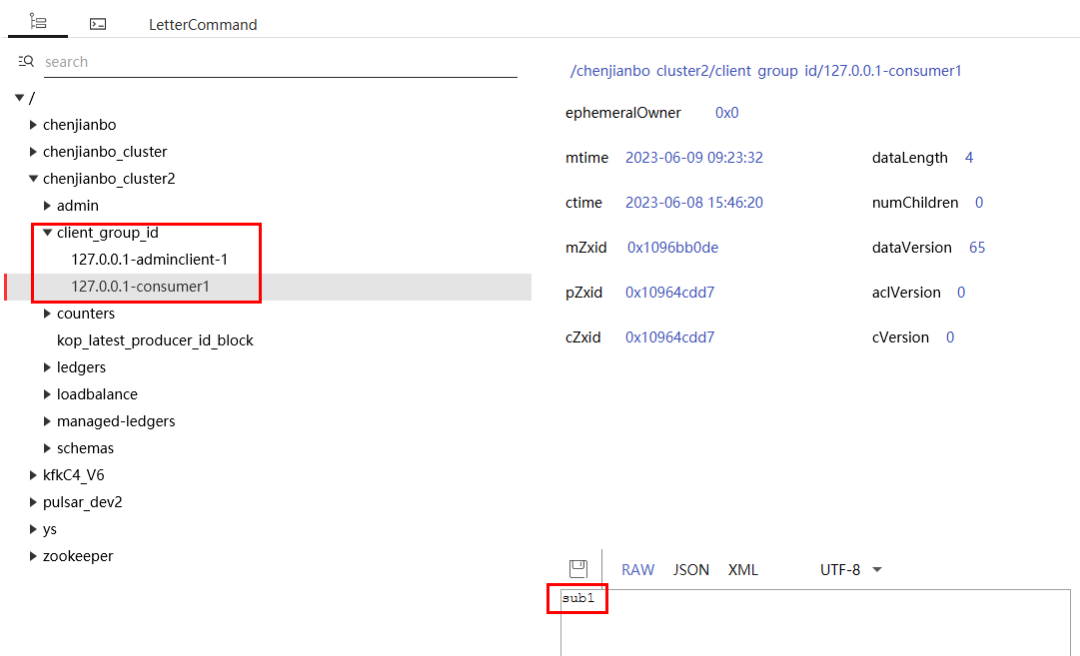
3、复现
若要解决问题,最好能够稳定地复现出问题,这样才能确定问题的根本原因,并且确认修复是否完成。
因为节点是在requsetHandle.close方法中执行删除,broker节点关闭会触发连接关闭,进而触发删除。假设:客户端通过brokerA发起FindCoordinator请求,写入zk节点/client_group
_id/xxx,同时请求返回brokerB作为Coordinator,后续与brokerB进行joinGroup、syncGroup等交互确定消费关系,客户端在brokerA、brokerB、brokerC都有分区消费。这时重启brokerA,分区均衡到BrokerC上,但此时/client_group_id/xxx因关闭broker而断开连接被删除,consumer消费刚转移到topic1-partition-1的分区就无法获取到groupId。
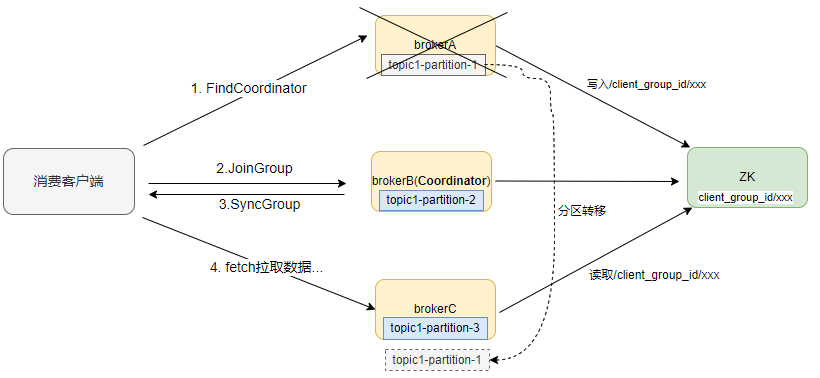
按照假设,有3个broker,开启生产和消费,通过在FindCoordinator返回前获取node.leader()的返回节点BrokerB,关闭brokerA后,brokerC出现断点复现,再关闭brokerC,brokerA也会复现(假设分区在brokerA与brokerC之间转移)。
复现要几个条件:
broker数量要足够多(不小于3个)
broker内部有zk缓存metadataCache默认为5分钟,可以把时间调小为1毫秒,相当于没有cache
findCoordinator返回的必须是其他broker的IP
重启的必须是接收到findCoordinator请求那台broker,而不是真正的coordinator,这时会从zk删除节点
分区转移到其他broker,这时新的broker会重新读取zk节点数据
到此,我们基本上清楚了问题原因:连接关闭导致zk节点被删除了,别的broker节点需要时就读取不到了。那怎么解决?
三、问题解决
方案一
既然知道把消费者与FindCoordinator的连接进行绑定不合适的,那么是否应该把FindCoordinator写入zk节点换成由JoinGroup写入,断连即删除。
consumer统一由Coordinator管理,由于FindCoordinator接口不一定是Coordinator处理的,如果换成由Coordinator处理的JoinGroup接口是否就可以了,这样consumer断开与Coordinator的连接就应该删除数据。但实现验证时却发现,客户端在断连后也不会再重连,所以没法重新写入zk,不符合预期。
方案二
还是由FindCoordinator写入zk节点,但删除改为GroupCoordinator监听consumer断开触发。
因为consumer统一由Coordinator管理,它能监听到consumer加入或者离开。GroupCoordinator的removeMemberAndUpdateGroup方法是coordinator对consumer成员管理。
private void removeMemberAndUpdateGroup(GroupMetadata group,
MemberMetadata member) {
group.remove(member.memberId());
switch (group.currentState()) {
case Dead:
case Empty:
return;
case Stable:
case CompletingRebalance:
maybePrepareRebalance(group);
break;
case PreparingRebalance:
joinPurgatory.checkAndComplete(new GroupKey(group.groupId()));
break;
default:
break;
}
// 删除 /client_group_id/xxx 节点
deleteClientIdGroupMapping(group, member.clientHost(), member.clientId());
}调用入口有两个,其中handleLeaveGroup是主动离开,onExpireHeartbeat是超时被动离开,客户端正常退出或者宕机都可以调用removeMemberAndUpdateGroup方法触发删除。
public CompletableFuture<Errors> handleLeaveGroup(
String groupId,
String memberId
) {
return validateGroupStatus(groupId, ApiKeys.LEAVE_GROUP).map(error ->
CompletableFuture.completedFuture(error)
).orElseGet(() -> {
return groupManager.getGroup(groupId).map(group -> {
return group.inLock(() -> {
if (group.is(Dead) || !group.has(memberId)) {
return CompletableFuture.completedFuture(Errors.UNKNOWN_MEMBER_ID);
} else {
...
// 触发删除消费者consumer
removeMemberAndUpdateGroup(group, member);
return CompletableFuture.completedFuture(Errors.NONE);
}
});
})
....
});
}void onExpireHeartbeat(GroupMetadata group,
MemberMetadata member,
long heartbeatDeadline) {
group.inLock(() -> {
if (!shouldKeepMemberAlive(member, heartbeatDeadline)) {
log.info("Member {} in group {} has failed, removing it from the group",
member.memberId(), group.groupId());
// 触发删除消费者consumer
removeMemberAndUpdateGroup(group, member);
}
return null;
});
}但这个方案有个问题是,日志运维关闭broker也会触发一个onExpireHeartbeat事件删除zk节点,与此同时客户端发现Coordinator断开了会马上触发FindCoordinator写入新的zk节点,但如果删除晚于写入的话,会导致误删除新写入的节点。我们干脆在关闭broker时,使用ShutdownHook加上shuttingdown状态防止关闭broker时删除zk节点,只有客户端断开时才删除。
这个方案修改上线半个月后,还是出现了一个客户端的消费指标无法上报的情况。后来定位发现,如果客户端因FullGC出现卡顿情况,客户端可能会先于broker触发超时,也就是先超时的客户端新写入的数据被后监听到超时的broker误删除了。因为写入与删除并不是由同一个节点处理,所以无法在进程级别做并发控制,而且也无法判断哪次删除对应哪次的写入,所以用zk也是很难实现并发控制。
方案三
其实这并不是新的方案,只是在方案二基础上优化:数据一致性检查。
既然我们很难控制好写入与删除的先后顺序,我们可以做数据一致性检查,类似于交易系统里的对账。因为GroupCoordinator是负责管理consumer成员的,维护着consumer的实时状态,就算zk节点被误删除,我们也可以从consumer成员信息中恢复,重新写入zk节点。
private void checkZkGroupMapping(){
for (GroupMetadata group : groupManager.currentGroups()) {
for (MemberMetadata memberMetadata : group.allMemberMetadata()) {
String clientPath = GroupIdUtils.groupIdPathFormat(memberMetadata.clientHost(), memberMetadata.clientId());
String zkGroupClientPath = kafkaConfig.getGroupIdZooKeeperPath() + clientPath;
// 查找zk中是否存在节点
metadataStore.get(zkGroupClientPath).thenAccept(resultOpt -> {
if (!resultOpt.isPresent()) {
// 不存在则进行补偿修复
metadataStore.put(zkGroupClientPath, memberMetadata.groupId().getBytes(UTF\_8), Optional.empty())
.thenAccept(stat -> {
log.info("repaired clientId and group mapping: {}({})",
zkGroupClientPath, memberMetadata.groupId());
})
.exceptionally(ex -> {
log.warn("repaired clientId and group mapping failed: {}({})",
zkGroupClientPath, memberMetadata.groupId());
return null;
});
}
}).exceptionally(ex -> {
log.warn("repaired clientId and group mapping failed: {} ", zkGroupClientPath, ex);
return null;
});
}
}
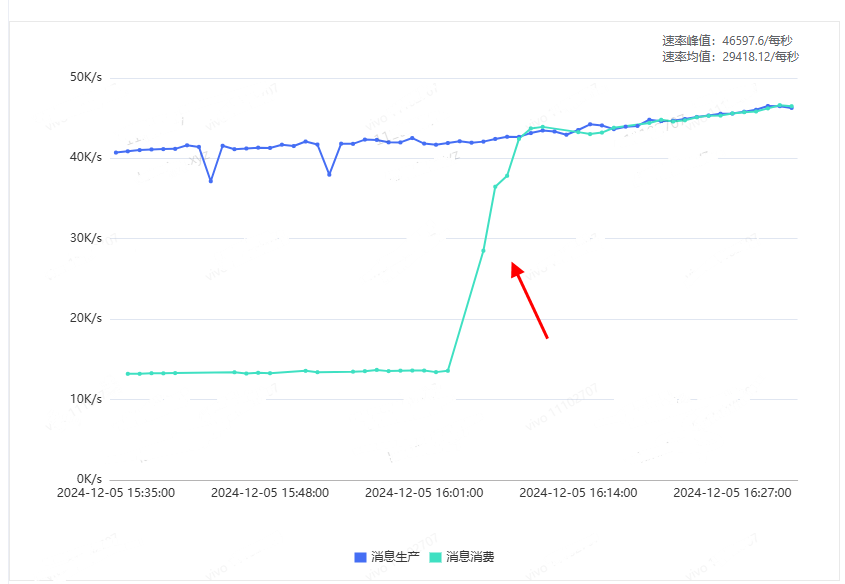
}经过方案三的优化上线,即使是历史存在问题的消费组,个别分区消费流量指标缺少group字段的问题也得到了修复。具体效果如下图所示:
四、总结
经过多个版本的优化和线上验证,最终通过方案三比较完美的解决了这个消费指标问题。在分布式系统中,并发问题往往难以模拟和复现,我们也在尝试多个版本后才找到有效的解决方案。如果您在这方面有更好的经验或想法,欢迎提出,我们共同探讨和交流。
vivo Pulsar 万亿级消息处理实践(3)-KoP指标异常修复的更多相关文章
- Kafka 万亿级消息实践之资源组流量掉零故障排查分析
作者:vivo 互联网服务器团队-Luo Mingbo 一.Kafka 集群部署架构 为了让读者能与小编在后续的问题分析中有更好的共鸣,小编先与各位读者朋友对齐一下我们 Kafka 集群的部署架构及服 ...
- 腾讯自研万亿级消息中间件TubeMQ为什么要捐赠给Apache?
导语 | 近日,云+社区技术沙龙“腾讯开源技术”圆满落幕.本次沙龙邀请了多位腾讯技术专家围绕腾讯开源与各位开发者进行探讨,深度揭秘了腾讯开源项目TencentOS tiny.TubeMQ.Kona J ...
- Kafka万亿级消息实战
一.Kafka应用 本文主要总结当Kafka集群流量达到 万亿级记录/天或者十万亿级记录/天 甚至更高后,我们需要具备哪些能力才能保障集群高可用.高可靠.高性能.高吞吐.安全的运行. 这里总结内容主 ...
- 杂文笔记《Redis在万亿级日访问量下的中断优化》
杂文笔记<Redis在万亿级日访问量下的中断优化> Redis在万亿级日访问量下的中断优化 https://mp.weixin.qq.com/s?__biz=MjM5ODI5Njc2MA= ...
- 如何基于MindSpore实现万亿级参数模型算法?
摘要:近来,增大模型规模成为了提升模型性能的主要手段.特别是NLP领域的自监督预训练语言模型,规模越来越大,从GPT3的1750亿参数,到Switch Transformer的16000亿参数,又是一 ...
- 万亿级KV存储架构与实践
一.KV 存储发展历程 我们第一代的分布式 KV 存储如下图左侧的架构所示,相信很多公司都经历过这个阶段.在客户端内做一致性哈希,在后端部署很多的 Memcached 实例,这样就实现了最基本的 KV ...
- 腾讯万亿级分布式消息中间件TubeMQ正式开源
TubeMQ是腾讯在2013年自研的分布式消息中间件系统,专注服务大数据场景下海量数据的高性能存储和传输,经过近7年上万亿的海量数据沉淀,目前日均接入量超过25万亿条.较之于众多明星的开源MQ组件,T ...
- js万亿级数字转汉字的封装方法
要求如图: 实现方法: function changeBillionToCN(c) { // 对传参进行类型处理,非字符串进行转换 if(typeof(c) != "string" ...
- 万亿级日志与行为数据存储查询技术剖析(续)——Tindex是改造的lucene和druid
五.Tindex 数果智能根据开源的方案自研了一套数据存储的解决方案,该方案的索引层通过改造Lucene实现,数据查询和索引写入框架通过扩展Druid实现.既保证了数据的实时性和指标自由定义的问题,又 ...
- 【HBase调优】Hbase万亿级存储性能优化总结
背景:HBase主集群在生产环境已稳定运行有1年半时间,最大的单表region数已达7200多个,每天新增入库量就有百亿条,对HBase的认识经历了懵懂到熟的过程.为了应对业务数据的压力,HBase入 ...
随机推荐
- BotSharp 5.0 MCP:迈向更开放的AI Agent框架
一.引言 在人工智能快速发展的时代,AI Agent(人工智能代理)作为一种能够自主感知环境.决策并执行动作的实体,在众多领域展现出了巨大的潜力.BotSharp 是一个功能强大的开源项目,由 Sci ...
- Linux终端居然也可以做文件浏览器?
大家好,我是良许. 在抖音上做直播已经整整 5 个月了,我很自豪我一路坚持到了现在[笑脸] 最近我在做直播的时候,也开始学习鱼皮大佬,直播写代码.当然我不懂 Java 后端,因此就写写自己擅长的 Sh ...
- Java8 Lambda Collection 的常见用法
import cn.hutool.core.collection.CollUtil; import cn.hutool.core.collection.ListUtil; import cn.huto ...
- Unity中检查重复的资源
目的:检查Unity中资源是否重复,例如有两张贴图,明明是一张,却被复制为两份放在工程中,名字或者所在目录位置不同,这对于资源管理来说是很浪费的.因此需要写一个检查工具来检查项目中是否存在重复的资源. ...
- unity prefab
1.修改prefab原始资源某组件为enabled或disabled,实例如果起初和原始资源是一样的状态那么修改原始资源会作用到实例上,如果发现不一样那么原始资源的修改不会作用到实例上,而且以后都不会 ...
- MySQL 中 varchar 和 char 有什么区别?
MySQL 中 varchar 和 char 的区别 在 MySQL 中,VARCHAR 和 CHAR 是两种常用的字符串类型,它们在存储方式.长度限制和使用场景等方面存在显著区别. 1. 定义与存储 ...
- react-router-dom嵌套路由实践
想要通过react-router-dom实现类似vue的router-view的嵌套路由效果,在点击导航菜单时切换页面,官方文档是真的没找到相关内容,现做个总结: 在createBrowserRout ...
- SSM整合3
目录 数据库 父工程 父工程目录结构 父工程pom.xml dao层 dao层目录结构 pom.xml domain dao 配置文件 mapper配置文件 applicationContext-da ...
- Join 实现 2 表数据联动
最近在做一个简单的报表, 用的工具是帆软报表, 一开始觉得有点low, 现在看看还行, 除了界面真的太丑外, 其它还要, 这种大量要使用 sql 的方式, 我觉得是非常灵活高效的, I like . ...
- 基于libwchnet&Mbedtls实现HTTPS
引言: 本文将介绍使用CH32V307VCT6以及官方协议栈(libwchnet)搭配Mbedtls作为客户端通过HTTPS访问百度并获取百度首页数据. 一.HTTPS概述与SSL/TSL简介 HTT ...