python存储MongoDB数据
MongoDB是由C++语言编写的非关系型数据库,是一个基于分布式文件存储的开源数据库系统,其内容存储形式类似JSON对象,它的字段值可以包含其他文档、数组及文档数组,非常灵活(总体来看,python对MongoDB的操作与直接在MongoDB操作大致相同)
1. 连接MongoDB
连接MongoDB时,需要使用PyMongoDB库中的MongoClient。一般来说,传入MongoDB的IP及端口即可,其中第一个参数为地址host,第二个参数为端口port(如果不给它传递参数,默认是27017)
import pymongo
client = pymongo.MongoClient(host='localhost', port=27017)
这样就创建了MongoDB的连接对象了。
另外,MongoClient第一个参数host还可以直接传入MongoDB的连接字符串,它以mongodb开头,例如
client = MongoClient('mongodb://localhost:27017/')
2. 指定数据库
MongoDB中可以建立多个数据库,接下来需要指定哪个数据库。这里以test数据库为例
db = client.test
这里调用client的test属性即返回test数据库。当然也可以这样指定:
db = client['test']
这两种方法是等价的。
3. 指定集合
MongoDB的每个数据库包含许多集合(collection),类似于关系型数据库中的表
下一步需要指定操作的集合,这里指定一个集合名称为students。与指定数据库类似,指定数据库也有两种方式:
collection = db.students
collection = db['students']
这样就声明了Collection对象
4. 插入数据
接下来,便可以插入数据了。对于students这个集合,新建一条学生数据,这条数据以字典形式表示:
student = {
'id': '20170101',
'name': 'Jordan',
'age': 20,
'gender': 'male'
}
这里指定了学生的学号、姓名、年龄和性别。接下来,直接调用collection的insert()方法即可插入数据,代码如下:
result = collection.insert(student)
print(result)
在MongoDB中,每条数据其实都有一个_id属性来唯一标识。如果没有显式指明该属性,MongoDB会自动产生一个ObjectId类型的_id属性。insert()方法会在执行后返回_id值。
运行结果:
5932a68615c2606814c91f3d
当然,我们也可以同时插入多条数据,只需要以列表形式传递即可,示例如下:
student1 = {
'id': '20170101',
'name': 'Jordan',
'age': 20,
'gender': 'male'
}
student2 = {
'id': '20170202',
'name': 'Mike',
'age': 21,
'gender': 'male'
}
result = collection.insert([student1, student2])
print(result)
返回结果是对应的_id的集合:
[ObjectId('5932a80115c2606a59e8a048'), ObjectId('5932a80115c2606a59e8a049')]
实际上,在PyMongo 3.x版本中,官方已经不推荐使用insert()方法了。当然,继续使用也没有什么问题。官方推荐使用insert_one()和insert_many()方法来分别插入单条记录和多条记录,示例如下:
student = {
'id': '20170101',
'name': 'Jordan',
'age': 20,
'gender': 'male'
}
result = collection.insert_one(student)
print(result)
print(result.inserted_id)
运行结果如下:
<pymongo.results.InsertOneResult object at 0x10d68b558>
5932ab0f15c2606f0c1cf6c5
与insert()方法不同,这次返回的是InsertOneResult对象,我们可以调用其inserted_id属性获取_id。
对于insert_many()方法,我们可以将数据以列表形式传递,示例如下:
student1 = {
'id': '20170101',
'name': 'Jordan',
'age': 20,
'gender': 'male'
}
student2 = {
'id': '20170202',
'name': 'Mike',
'age': 21,
'gender': 'male'
}
result = collection.insert_many([student1, student2])
print(result)
print(result.inserted_ids)
运行结果如下:
<pymongo.results.InsertManyResult object at 0x101dea558>
[ObjectId('5932abf415c2607083d3b2ac'), ObjectId('5932abf415c2607083d3b2ad')]
该方法返回的类型是InsertManyResult,调用inserted_ids属性可以获取插入数据的_id列表。
5. 查询
插入数据后,我们可以利用find_one()或find()方法进行查询,其中find_one()查询得到的是单个结果,find()则返回一个生成器对象。示例如下:
result = collection.find_one({'name': 'Mike'})
print(type(result))
print(result)
这里我们查询name为Mike的数据,它的返回结果是字典类型,运行结果如下:
<class 'dict'>
{'_id': ObjectId('5932a80115c2606a59e8a049'), 'id': '20170202', 'name': 'Mike', 'age': 21, 'gender': 'male'}
可以发现,它多了_id属性,这就是MongoDB在插入过程中自动添加的。
此外,我们也可以根据ObjectId来查询,此时需要使用bson库里面的objectid:
from bson.objectid import ObjectId
result = collection.find_one({'_id': ObjectId('593278c115c2602667ec6bae')})
print(result)
其查询结果依然是字典类型,具体如下:
{'_id': ObjectId('593278c115c2602667ec6bae'), 'id': '20170101', 'name': 'Jordan', 'age': 20, 'gender': 'male'}
当然,如果查询结果不存在,则会返回None。
对于多条数据的查询,我们可以使用find()方法。例如,这里查找年龄为20的数据,示例如下:
results = collection.find({'age': 20})
print(results)
for result in results:
print(result)
运行结果如下:
<pymongo.cursor.Cursor object at 0x1032d5128>
{'_id': ObjectId('593278c115c2602667ec6bae'), 'id': '20170101', 'name': 'Jordan', 'age': 20, 'gender': 'male'}
{'_id': ObjectId('593278c815c2602678bb2b8d'), 'id': '20170102', 'name': 'Kevin', 'age': 20, 'gender': 'male'}
{'_id': ObjectId('593278d815c260269d7645a8'), 'id': '20170103', 'name': 'Harden', 'age': 20, 'gender': 'male'}
返回结果是Cursor类型,它相当于一个生成器,我们需要遍历取到所有的结果,其中每个结果都是字典类型。
如果要查询年龄大于20的数据,则写法如下:
results = collection.find({'age': {'$gt': 20}})
这里查询的条件键值已经不是单纯的数字了,而是一个字典,其键名为比较符号$gt,意思是大于,键值为20。
这里将比较符号归纳为下表。
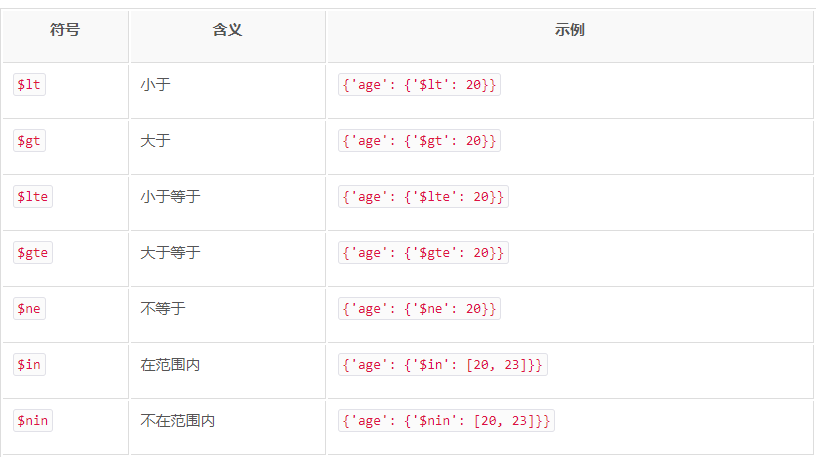
另外,还可以进行正则匹配查询。例如,查询名字以M开头的学生数据,示例如下:
results = collection.find({'name': {'$regex': '^M.*'}})
这里使用$regex来指定正则匹配,^M.*代表以M开头的正则表达式。
功能符号再归类为下表

关于这些操作的更详细用法,可以在MongoDB官方文档找到:https://docs.mongodb.com/manual/reference/operator/query/。
6. 计数
要统计查询结果有多少条数据,可以调用count()方法。比如,统计所有数据条数:
count = collection.find().count()
print(count)
或者统计符合某个条件的数据:
count = collection.find({'age': 20}).count()
print(count)
运行结果是一个数值,即符合条件的数据条数。
7. 排序
排序时,直接调用sort()方法,并在其中传入排序的字段及升降序标志即可。示例如下:
results = collection.find().sort('name', pymongo.ASCENDING)
print([result['name'] for result in results])
运行结果如下:
['Harden', 'Jordan', 'Kevin', 'Mark', 'Mike']
这里我们调用pymongo.ASCENDING指定升序。如果要降序排列,可以传入pymongo.DESCENDING。
8. 偏移
在某些情况下,我们可能想只取某几个元素,这时可以利用skip()方法偏移几个位置,比如偏移2,就忽略前两个元素,得到第三个及以后的元素:
results = collection.find().sort('name', pymongo.ASCENDING).skip(2)
print([result['name'] for result in results])
运行结果如下:
['Kevin', 'Mark', 'Mike']
另外,还可以用limit()方法指定要取的结果个数,示例如下:
results = collection.find().sort('name', pymongo.ASCENDING).skip(2).limit(2)
print([result['name'] for result in results])
运行结果如下:
['Kevin', 'Mark']
如果不使用limit()方法,原本会返回三个结果,加了限制后,会截取两个结果返回。
值得注意的是,在数据库数量非常庞大的时候,如千万、亿级别,最好不要使用大的偏移量来查询数据,因为这样很可能导致内存溢出。此时可以使用类似如下操作来查询:
from bson.objectid import ObjectId
collection.find({'_id': {'$gt': ObjectId('593278c815c2602678bb2b8d')}})
这时需要记录好上次查询的_id。
9. 更新
对于数据更新,我们可以使用update()方法,指定更新的条件和更新后的数据即可。例如:
condition = {'name': 'Kevin'}
student = collection.find_one(condition)
student['age'] = 25
result = collection.update(condition, student)
print(result)
这里我们要更新name为Kevin的数据的年龄:首先指定查询条件,然后将数据查询出来,修改年龄后调用update()方法将原条件和修改后的数据传入。
运行结果如下:
{'ok': 1, 'nModified': 1, 'n': 1, 'updatedExisting': True}
返回结果是字典形式,ok代表执行成功,nModified代表影响的数据条数。
另外,我们也可以使用$set操作符对数据进行更新,代码如下:
result = collection.update(condition, {'$set': student})
这样可以只更新student字典内存在的字段。如果原先还有其他字段,则不会更新,也不会删除。而如果不用$set的话,则会把之前的数据全部用student字典替换;如果原本存在其他字段,则会被删除。
另外,update()方法其实也是官方不推荐使用的方法。这里也分为update_one()方法和update_many()方法,用法更加严格,它们的第二个参数需要使用$类型操作符作为字典的键名,示例如下:
condition = {'name': 'Kevin'}
student = collection.find_one(condition)
student['age'] = 26
result = collection.update_one(condition, {'$set': student})
print(result)
print(result.matched_count, result.modified_count)
这里调用了update_one()方法,第二个参数不能再直接传入修改后的字典,而是需要使用{'$set': student}这样的形式,其返回结果是UpdateResult类型。然后分别调用matched_count和modified_count属性,可以获得匹配的数据条数和影响的数据条数。
运行结果如下:
<pymongo.results.UpdateResult object at 0x10d17b678>
1 0
再看个例子:
condition = {'age': {'$gt': 20}}
result = collection.update_one(condition, {'$inc': {'age': 1}})
print(result)
print(result.matched_count, result.modified_count)
这里指定查询条件为年龄大于20,然后更新条件{'$inc': {'age': 1}},也就是年龄加1,执行之后会将第一条符合条件的数据年龄加1。
运行结果如下:
<pymongo.results.UpdateResult object at 0x10b8874c8>
1 1
可以看到匹配条数为1条,影响条数也为1条。
如果调用update_many()方法,则会将所有符合条件的数据都更新,示例如下:
condition = {'age': {'$gt': 20}}
result = collection.update_many(condition, {'$inc': {'age': 1}})
print(result)
print(result.matched_count, result.modified_count)
这时匹配条数就不再为1条了,运行结果如下:
<pymongo.results.UpdateResult object at 0x10c6384c8>
3 3
可以看到,这时所有匹配到的数据都会被更新。
10. 删除
删除操作比较简单,直接调用remove()方法指定删除的条件即可,此时符合条件的所有数据均会被删除。示例如下:
result = collection.remove({'name': 'Kevin'})
print(result)
运行结果如下:
{'ok': 1, 'n': 1}
另外,这里依然存在两个新的推荐方法——delete_one()和delete_many()。示例如下:
result = collection.delete_one({'name': 'Kevin'})
print(result)
print(result.deleted_count)
result = collection.delete_many({'age': {'$lt': 25}})
print(result.deleted_count)
运行结果如下:
<pymongo.results.DeleteResult object at 0x10e6ba4c8>
1
4
delete_one()即删除第一条符合条件的数据,delete_many()即删除所有符合条件的数据。它们的返回结果都是DeleteResult类型,可以调用deleted_count属性获取删除的数据条数。
11. 其他操作
另外,PyMongo还提供了一些组合方法,如find_one_and_delete()、find_one_and_replace()和find_one_and_update(),它们是查找后删除、替换和更新操作,其用法与上述方法基本一致。
关于PyMongo的详细用法,可以参见官方文档:http://api.mongodb.com/python/current/api/pymongo/collection.html。
另外,还有对数据库和集合本身等的一些操作,这里不再一一讲解,可以参见官方文档:http://api.mongodb.com/python/current/api/pymongo/。
参考:https://cuiqingcai.com/5584.html
python存储MongoDB数据的更多相关文章
- python 导出mongoDB数据中的数据
import pymongo,urllibimport sysimport timeimport datetimereload(sys)sys.setdefaultencoding('utf8')fr ...
- python编码与存储读取数据(数组字典)
Camp时在python2的编码上坑了不少. 理解pyhon2的编码 python2字符串类型只有两种: str类型:b'xxx'即是str类型, 是编码后的类型,len()按字节计算 unicode ...
- MongoDB聚合查询及Python连接MongoDB操作
今日内容概要 聚合查询 Python操作MongoDB 第三方可视化视图工具 今日内容详细 聚合查询 Python操作MongoDB 数据准备 from pymongo import MongoCli ...
- python爬虫27 | 当Python遇到MongoDB的时候,存储av女优的数据变得如此顺滑爽~
上次 我们知道了怎么操作 MySQL 数据库 python爬虫26 | 把数据爬取下来之后就存储到你的MySQL数据库. MySQL 有些年头了 开源又成熟又牛逼 所以现在很多企业都在使用 MySQL ...
- python操作MONGODB数据库,提取部分数据再存储
目标:从一个数据库中提取几个集合中的部分数据,组合起来一共一万条.几个集合,不足一千条数据的集合就全部提取,够一千条的就用一万减去不足一千的,再除以大于一千的集合个数,得到的值即为所需提取文档的个数. ...
- python 全栈开发,Day126(创业故事,软件部需求,内容采集,显示内容图文列表,MongoDB数据导入导出JSON)
作业讲解 下载代码: HBuilder APP和flask后端登录 链接:https://pan.baidu.com/s/1eBwd1sVXTNLdHwKRM2-ytg 密码:4pcw 如何打开APP ...
- 孤荷凌寒自学python第六十天在windows10上搭建本地Mongodb数据服务
孤荷凌寒自学python第六十天在windows10上找搭建本地Mongodb数据服务 (完整学习过程屏幕记录视频地址在文末) 今天是学习mongoDB数据库的第六天.成功在本地搭建了windows ...
- 孤荷凌寒自学python第五十九天尝试使用python来读访问远端MongoDb数据服务
孤荷凌寒自学python第五十九天尝试使用python来读访问远端MongoDb数据服务 (完整学习过程屏幕记录视频地址在文末) 今天是学习mongoDB数据库的第五天.今天的感觉是,mongoDB数 ...
- mongodb存储二进制数据的二种方式——binary bson或gridfs
python 版本为2.7 mongodb版本2.6.5 使用mongodb存储文件,可以使用两种方式,一种是像存储普通数据那样,将文件转化为二进制数据存入mongodb,另一种使用gridfs,咱们 ...
- Python之pandas数据加载、存储
Python之pandas数据加载.存储 0. 输入与输出大致可分为三类: 0.1 读取文本文件和其他更好效的磁盘存储格式 2.2 使用数据库中的数据 0.3 利用Web API操作网络资源 1. 读 ...
随机推荐
- 26考研高数习题:1.1. 分段&复合函数
§1.1. 分段&复合函数 更详细的考研数学精讲请访问「荒原之梦考研数学」 Ultra 版:www.zhaokaifeng.com 001 题目 设 \(g\left(x\right) = ...
- SpringMVC - 谈谈你对SpringMVC的理解
谈谈你对 Spring MVC 的理解? 普通人:Spring MVC 它是一个MVC框架吧,就是,我们可以使用Spring MVC来开发Web应用...呃 它是基于Servlet上的一个扩展,就是它 ...
- Ansible - [07] 定义变量的几种方式
题记部分 Ansible 支持十几种定义变量的方式 Inventory 变量 Host Facts 变量 Register 变量 Playbook 变量 Playbook 提示变量 变量文件 命令行变 ...
- Processing多窗口程序范例(二)
多窗口范例(二),做一个划线生成图像的应用,最后结果: 子窗口划线,主窗口复制多个画布叠加并添加了旋转动画. 范例程序 主程序: package syf.demo.multiwindow2; impo ...
- VSCode ESLint规则警告屏蔽方法
举例:要屏蔽"Missing trailing comma"或"comma-dangle"警告,你可以使用ESLint的配置选项来设置规则.下面是一些方法,你可 ...
- Unable to Connect: sPort: 0 C# ServiceStack.Redis 访问 redis
需求: 对数据库中的不断抓取的文章进行缓存,因此需要定时访问数据,写入缓存中 在捕获到的异常日志发现错误:Unable to Connect: sPort: 0 使用的访问方式是线程池的方式:Poo ...
- wxpython 文件重命名报错提示os.rename WinError 2]系统找不到指定的文件‘
原因:重命名需要把文件路径带上 源码: for file in files: print(file) os.rename(file, file.replace(beforename, afternam ...
- LayerSkip: 使用自推测解码加速大模型推理
自推测解码是一种新颖的文本生成方法,它结合了推测解码 (Speculative Decoding) 的优势和大语言模型 (LLM) 的提前退出 (Early Exit) 机制.该方法出自论文 Laye ...
- CSS那些事读书笔记-2
背景 作为一个后端开发,曾经尝试过学习前端,但是总觉不得要领,照猫画虎,而公司里又有专业的前端开发,工作中几乎接触不到实际的前端任务,所以前端的技能田野一直是一片荒芜.但是笔者深知前端的技能对找工作和 ...
- SQLServer中事务处理
--将当前库存记录insert医废转移单中 --declare @Warehouse nvarchar(100); declare @Warehouse_JJRID nvarchar(100); de ...