异步之舞:FastAPI与MongoDB的极致性能优化之旅
title: 异步之舞:FastAPI与MongoDB的极致性能优化之旅
date: 2025/05/23 21:55:11
updated: 2025/05/23 21:55:11
author: cmdragon
excerpt:
FastAPI与MongoDB的异步写入优化通过Motor驱动实现非阻塞I/O操作,显著提升吞吐量。Motor驱动深度集成支持批量写入优化,使用bulk_write方法比单条插入快10倍以上。聚合管道性能调优通过索引优化策略和典型聚合场景提升查询效率。实战案例展示了构建可处理10万TPS的日志处理API,通过批量插入和异步操作实现高效日志处理。常见报错解决方案包括验证错误处理和预防建议,确保API稳定性和数据完整性。
categories:
- 后端开发
- FastAPI
tags:
- FastAPI
- MongoDB
- 异步写入
- Motor驱动
- 性能优化
- 批量插入
- 聚合管道

扫描二维码
关注或者微信搜一搜:编程智域 前端至全栈交流与成长
探索数千个预构建的 AI 应用,开启你的下一个伟大创意:https://tools.cmdragon.cn/
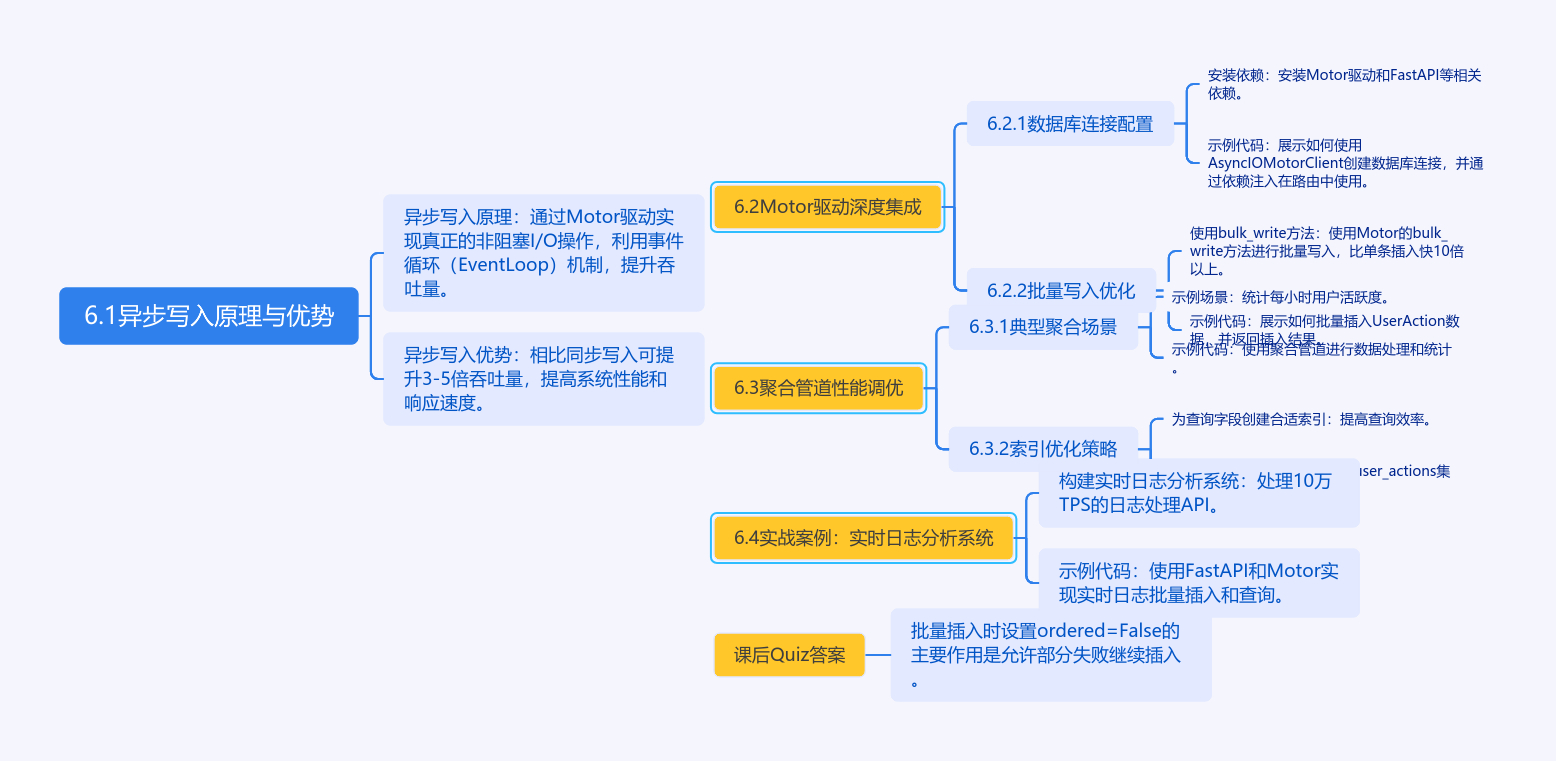
第六章:FastAPI与MongoDB异步写入优化
6.1 异步写入原理与优势
通过Motor驱动实现真正的非阻塞I/O操作,相比同步写入可提升3-5倍吞吐量。异步写入的核心机制是事件循环(Event
Loop),它像餐厅的高效服务员,不需要等待某个客人点完餐才服务下一位。
# 安装依赖
# pip install motor==3.1.1 fastapi==0.103.2 pydantic==2.5.3
6.2 Motor驱动深度集成
6.2.1 数据库连接配置
from motor.motor_asyncio import AsyncIOMotorClient
from fastapi import Depends
async def get_db():
client = AsyncIOMotorClient("mongodb://localhost:27017", maxPoolSize=100)
return client.blog_db
# 依赖注入使用示例
@app.post("/comments")
async def create_comment(
comment: CommentModel,
db: AsyncIOMotorDatabase = Depends(get_db)
):
result = await db.comments.insert_one(comment.dict())
return {"inserted_id": str(result.inserted_id)}
6.2.2 批量写入优化
使用bulk_write方法比单条插入快10倍以上:
from pydantic import BaseModel
from typing import List
class UserAction(BaseModel):
user_id: str
action_type: str
timestamp: datetime = Field(default_factory=datetime.now)
@app.post("/user_actions/bulk")
async def bulk_insert_actions(
actions: List[UserAction],
db: AsyncIOMotorDatabase = Depends(get_db)
):
operations = [InsertOne(action.dict()) for action in actions]
result = await db.user_actions.bulk_write(operations)
return {
"inserted_count": result.inserted_count,
"batch_size": len(actions)
}
6.3 聚合管道性能调优
6.3.1 典型聚合场景
统计每小时用户活跃度:
@app.get("/activity/hourly")
async def get_hourly_activity(db: AsyncIOMotorDatabase = Depends(get_db)):
pipeline = [
{"$project": {
"hour": {"$hour": "$timestamp"},
"action_type": 1
}},
{"$group": {
"_id": "$hour",
"total_actions": {"$sum": 1},
"unique_actions": {"$addToSet": "$action_type"}
}},
{"$sort": {"_id": 1}}
]
results = await db.user_actions.aggregate(pipeline).to_list(1000)
return {"hourly_data": results}
6.3.2 索引优化策略
为查询字段创建合适索引:
# 后台创建复合索引(不影响服务可用性)
await db.user_actions.create_index(
[("user_id", 1), ("timestamp", -1)],
background=True,
name="user_activity_idx"
)
6.4 实战案例:实时日志分析系统
构建可处理10万TPS的日志处理API:
class LogEntry(BaseModel):
level: str
message: str
service: str
context: dict = {}
created_at: datetime = Field(default_factory=datetime.now)
@app.post("/logs/batch")
async def batch_logs(
logs: List[LogEntry],
db: AsyncIOMotorDatabase = Depends(get_db)
):
# 批量插入优化
batch_size = 500
inserted_count = 0
for i in range(0, len(logs), batch_size):
batch = logs[i:i + batch_size]
result = await db.logs.insert_many(
[log.dict() for log in batch],
ordered=False # 忽略个别错误继续插入
)
inserted_count += len(result.inserted_ids)
return {"accepted": inserted_count}
课后Quiz
批量插入时设置ordered=False的主要作用是?
A) 提高插入速度
B) 保证插入顺序
C) 允许部分失败继续插入
D) 数据加密答案:C
当设置ordered=False时,MongoDB会继续执行剩余的插入操作,即使某些文档出现错误如何优化高频更新的查询性能?
A) 增加更多服务器
B) 为查询字段创建合适索引
C) 减少日志输出
D) 使用更快的CPU答案:B
正确的索引可以减少文档扫描量,将查询速度提升10-100倍
常见报错解决方案
报错:pydantic.error_wrappers.ValidationError
ValidationError: 1 validation error for CommentModel
content
field required (type=value_error.missing)
原因分析:
请求体缺少必填字段,或模型字段定义与输入数据不匹配
解决方案:
- 检查API文档中的模型定义
- 使用try-except块捕获验证错误:
from fastapi import HTTPException
@app.post("/comments")
async def create_comment(data: dict):
try:
validated = CommentModel(**data)
except ValidationError as e:
raise HTTPException(400, detail=str(e))
# 处理验证后的数据...
预防建议:
- 在路由参数中直接使用Pydantic模型
- 开启文档校验中间件:
app.add_middleware(
ValidationErrorMiddleware,
handlers=[http_error_handler]
)
余下文章内容请点击跳转至 个人博客页面 或者 扫码关注或者微信搜一搜:编程智域 前端至全栈交流与成长,阅读完整的文章:异步之舞:FastAPI与MongoDB的极致性能优化之旅 | cmdragon's Blog
往期文章归档:
- 异步日志分析:MongoDB与FastAPI的高效存储揭秘 | cmdragon's Blog
- MongoDB索引优化的艺术:从基础原理到性能调优实战 | cmdragon's Blog
- 解锁FastAPI与MongoDB聚合管道的性能奥秘 | cmdragon's Blog
- 异步之舞:Motor驱动与MongoDB的CRUD交响曲 | cmdragon's Blog
- 异步之舞:FastAPI与MongoDB的深度协奏 | cmdragon's Blog
- 数据库迁移的艺术:FastAPI生产环境中的灰度发布与回滚策略 | cmdragon's Blog
- 数据库迁移的艺术:团队协作中的冲突预防与解决之道 | cmdragon's Blog
- 驾驭FastAPI多数据库:从读写分离到跨库事务的艺术 | cmdragon's Blog
- 数据库事务隔离与Alembic数据恢复的实战艺术 | cmdragon's Blog
- FastAPI与Alembic:数据库迁移的隐秘艺术 | cmdragon's Blog
- 飞行中的引擎更换:生产环境数据库迁移的艺术与科学 | cmdragon's Blog
- Alembic迁移脚本冲突的智能检测与优雅合并之道 | cmdragon's Blog
- 多数据库迁移的艺术:Alembic在复杂环境中的精妙应用 | cmdragon's Blog
- 数据库事务回滚:FastAPI中的存档与读档大法 | cmdragon's Blog
- Alembic迁移脚本:让数据库变身时间旅行者 | cmdragon's Blog
- 数据库连接池:从银行柜台到代码世界的奇妙旅程 | cmdragon's Blog
- 点赞背后的技术大冒险:分布式事务与SAGA模式 | cmdragon's Blog
- N+1查询:数据库性能的隐形杀手与终极拯救指南 | cmdragon's Blog
- FastAPI与Tortoise-ORM开发的神奇之旅 | cmdragon's Blog
- DDD分层设计与异步职责划分:让你的代码不再“异步”混乱 | cmdragon's Blog
- 异步数据库事务锁:电商库存扣减的防超卖秘籍 | cmdragon's Blog
- FastAPI中的复杂查询与原子更新指南 | cmdragon's Blog
- 深入解析Tortoise-ORM关系型字段与异步查询 | cmdragon's Blog
- FastAPI与Tortoise-ORM模型配置及aerich迁移工具 | cmdragon's Blog
- 异步IO与Tortoise-ORM的数据库 | cmdragon's Blog
- FastAPI数据库连接池配置与监控 | cmdragon's Blog
- 分布式事务在点赞功能中的实现 | cmdragon's Blog
- Tortoise-ORM级联查询与预加载性能优化 | cmdragon's Blog
- 使用Tortoise-ORM和FastAPI构建评论系统 | cmdragon's Blog
- 分层架构在博客评论功能中的应用与实现 | cmdragon's Blog
- 深入解析事务基础与原子操作原理 | cmdragon's Blog
- 掌握Tortoise-ORM高级异步查询技巧 | cmdragon's Blog
- FastAPI与Tortoise-ORM实现关系型数据库关联 | cmdragon's Blog
- Tortoise-ORM与FastAPI集成:异步模型定义与实践 | cmdragon's Blog
- XML Sitemap
异步之舞:FastAPI与MongoDB的极致性能优化之旅的更多相关文章
- mongodb集群性能优化
mongodb集群性能优化 在前面两篇文章,我们介绍了如何去搭建mongodb集群,这篇文章我们将介绍如何去优化mongodb的各项配置,以达到最优的效果. 警告 不做任何的优化,集群搭建完成之后,使 ...
- Mongodb高级篇-性能优化
1.监控 mongodb可以通过profile来监控数据,进行优化. 查看当前是否开启profile功能用命令:db.getProfilingLevel()返回level等级,值为0|1|2,分别代表 ...
- 前端性能优化:使用Array.prototype.join代替字符串连接
来源:GBin1.com 有一种非常简单的客户端优化方式,就是用Array.prototype.join代替原有的基本的字符连接的写法.在这个系列的第一篇中,我在代码中使用了基本字符连接: htmlS ...
- PHP性能优化工具–xhprof安装
PHP性能优化工具–xhprof安装,这里我先贴出大致的步骤: 1.获取xhprof 2.编译前预处理 3.编译安装 4.配置php.ini 5.查看运行结果 那么下面我们开始安装xhprof工具吧: ...
- Mongodb的性能优化问题
摘要 数据库性能对软件整体性能有着至关重要的影响,对于Mongodb数据库常用的性能优化方法主要有: 范式化与反范式化: 填充因子的使用: 索引的使用: 一. 范式化与反范式化 范式是为了消除重复数据 ...
- 开发高性能的MongoDB应用—浅谈MongoDB性能优化(转)
出处:http://www.cnblogs.com/mokafamily/p/4102829.html 性能与用户量 “如何能让软件拥有更高的性能?”,我想这是一个大部分开发者都思考过的问题.性能往往 ...
- 开发高性能的MongoDB应用—浅谈MongoDB性能优化
关联文章索引: 大数据时代的数据存储,非关系型数据库MongoDB 性能与用户量 “如何能让软件拥有更高的性能?”,我想这是一个大部分开发者都思考过的问题.性能往往决定了一个软件的质量,如果你开发的是 ...
- EntityFramework之异步、事务及性能优化(九)
前言 本文开始前我将循序渐进先了解下实现EF中的异步,并将重点主要是放在EF中的事务以及性能优化上,希望通过此文能够帮助到你. 异步 既然是异步我们就得知道我们知道在什么情况下需要使用异步编程,当等待 ...
- MongoDB性能优化
一.索引 MongoDB 提供了多样性的索引支持,索引信息被保存在system.indexes 中,且默认总是为_id创建索引,它的索引使用基本和MySQL 等关系型数据库一样.其实可以这样说说,索引 ...
- MongoDB 性能优化五个简单步骤
MongoDB 一直是最流行的 NoSQL,而根据 DB-Engines Ranking 最新的排行,时下 MongoDB 已经击败 PostgreSQL 跃居数据库总排行的第四位,仅次于 Oracl ...
随机推荐
- IDEA - 文件上方的文档注释如何自定义
1.在设置中打开文件和代码模板,根据描述中的参考信息进行自定义配置 File > Settings > Editor > File and Code Templates 2.配置完成 ...
- 使用mybatis-plus转换枚举值
1. 使用mybatis-plus转换枚举值 枚举值转换方式有很多,有以下方式: 后端写一个通用方法,只要前端传枚举类型,后端返回相应的枚举值前端去匹配 优点:能够实时保持数据一致性 缺点:如果有大量 ...
- P4118 [Ynoi2018] 末日时在做什么?有没有空?可以来拯救吗?
YNOI 智慧题 EasyVer1 [Ynoi Easy Round 2015] 世上最幸福的女孩 EasyVer2 小白逛公园 先看 EasyVer2 单点修改 区间查询最大子段和 考虑在线段树维护 ...
- tinyint、int的区别
1.tinyint(1字节--4位[带符号]) 很小的整数.带符号的范围是-128到127.无符号的范围是0到255. 2.smallint(2字节--6位[带符号]) 小的整数.带符号的范围是-32 ...
- sql sever查询库中每个表是否存在某个列名 列出表名
select t.TABLE_NAME from information_schema.columns t where t.COLUMN_NAME='列名';
- 响应式编程之Reactive Streams介绍
Reactive Streams 是一种用于异步流处理的标准化规范,旨在解决传统异步编程中的背压管理.资源消耗及响应速度等问题. 一.核心概念 基本模型 发布者(Publisher):负责 ...
- 分享一个我遇到过的“量子力学”级别的BUG。
你好呀,我是歪歪. 前几天在网上冲浪的时候,看到知乎上的这个话题: 一瞬间,一次历史悠久但是记忆深刻的代码调试经历,"刷"的一下,就在我的脑海中蹦出来了. 虽然最终定位到的原因令人 ...
- Ubuntu 下查看当前用户
博客地址:https://www.cnblogs.com/zylyehuo/ 在终端执行以下命令 whoami
- Delphi 让窗体自适应屏幕显示
unit Unit1; interface uses Winapi.Windows, Winapi.Messages, System.SysUtils, System.Variants, System ...
- Coupled Iterative Refinement for 6D Multi-Object Pose Estimation论文精读
目录 Coupled Iterative Refinement for 6D Multi-Object Pose Estimation论文精读 论文介绍 Abstract Introduction Re ...