R语言学习数据挖掘
1.用R计算数据基本统计量(均值)
学习机器学习和数据挖掘中的各种算法和模型,需要掌握统计学的基本概念。统计学是通过搜索、整理、分析数据等手段,以达到推断所测对象的本质,并预测对象未来走势的一门综合性科学。
简单说,统计学是根据样本估计总体的科学。它的一些思想和大数据思想有些相悖,不关注数据的大小,而是更关注数据的好坏。
分析数据的第一步要进行数据描述性分析,数据描述性分析指的是:通过绘制统计图、编译统计 表、描述统计量等方法来表数据数据的分布特征。
其中,描述统计量包括:中心趋势度量、分散程度度量
中心趋势度量 描述样本数据的集中趋势的统计量 均值、中位数、众数、百分位数……
分散程度度量 又称散布度量 方差、标准差、极差、百分位数……
对于R中的必会操作可以参见:R语言必会基础语法
均值(mean)
均值数据的平均值
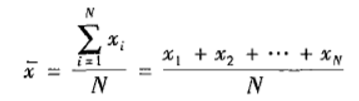
均值和期望:数据总体的平均值是均值,数据样本的平均值是期望。
用R计算均值
函数:在R中,可以用mean()函数来计算样本的均值
mean(x, trim=0, na.rm=FALSE)
其中,x是样本数据(比如向量、矩阵、数组或数据框),trim是计算均值前去掉与均值差较大数据的比例, 缺省值为0,即包含全部数据。当na.rm=FALSE时,允许数据中有缺失数据。
例1
> data<-c(30,31,47,50,52,56,60,63,70,70,110)
> data
[1] 30 31 47 50 52 56 60 63 70 70 110
> result=mean(data);result
[1] 58.09091
mean()函数还可以计算一个矩阵的总体数据均值。
例2
> data<-1:12
> dim(data)<-c(3,4);data
[,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 2 5 8 11
[3,] 3 6 9 12
> result=mean(data);result
[1] 6.5
apply(x,1或2,计算函数 )
计算矩阵中每行或每列的均值,需要调用apply()函数。
其中,x是样本数据,数字1表示求每行的数据平均值,数字2表示求每列的平均值。
还以上面的矩阵为例
例3
> result=apply(data,1,mean);result
[1] 5.5 6.5 7.5
> result=apply(data,2,mean);result
[1] 2 5 8 11
参数trim
均值的弱点是对异常值敏感,所以有的时候我们需要剔除掉一些数据,然后才能得到准确有意义的均值。
比如下面这组数据记录学生的体重值:
750,64.0,47.4,66.9,62.2,62.2,58.7,63.5
66.6,64.0,57.0,69.0,56.9,50.0,72.0
其中有一个值少了个小数点,变成了750kg,此时计算均值就是有误差的。所以需要把异常值替换掉。可以调用 mean()里的trim参数来处理。 trim的取值在0~0.5之间, 表示在计算均值前需要去掉的异常值比例。
当然,异常值也不是一定要剔除的,有些情况下,会专门做离群点分析。
例4
> data<-c(750,64.0,47.4,66.9,62.2,62.2,58.7,63.5,66.6,64.0,57.0,69.0,56.9,50.0,72.0);data
[1] 750.0 64.0 47.4 66.9 62.2 62.2 58.7 63.5 66.6 64.0 57.0 69.0
[13] 56.9 50.0 72.0
> result=mean(data,trim=0.1);result
[1] 62.53846
图中所求的第一个均值是没有剔除异常值时的均值,第二个为加入trim参数后的均值:

参数na.rm
有时样本数据里有缺失值,比如下组数据:
75.0,64.0,47.4,66.9,62.2,62.2,58.7,63.5,66.6,64.0,57.0,69.0,56.9,50.0,NA
这样在计算均值时就会出现错误,此时可以选用参数na.rm=TRUE来忽略控制。
例5
> data<-c(75.0,64.0,47.4,66.9,62.2,62.2,58.7,63.5,66.6,64.0,57.0,69.0,56.9,50.0,NA)
> result=mean(data,na.rm=TRUE);result
[1] 61.67143
> result=mean(data);result
[1] NA
图中可以看到,在有缺失值的情况下,直接求均值,结果为NA:
补充:加权算术均值
每一个样本数据x都有一个对应的权重W与之关联,权重反映了对应数据x的重要程度。
2.用R计算数据基本统计量(中位数、百分位数)
中位数
定义:
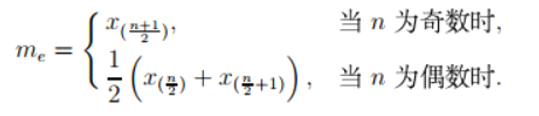
为什么要有中位数?
我们要知道的是,均值描述并不总是可靠的或最佳的。均值对于极端值(例如离群点)很敏感, 比如整个公司薪水的均值由几个极高收入的经理显著推高。为了抵消少数极端值的影响,我们可以使用截尾均值(丢弃极端值后计算均值)。截尾均值一般是去掉高端和低端的2%数据。
但是,当异常值的价值非常大时,用截尾均值同样会丢失大量的价值数据。
对于倾斜数据,更好的度量值是中位数。
中位数定义为数据排序位于中间位置的数据,比如一组样本数据:3,1,7,5,9 则中位数为5。
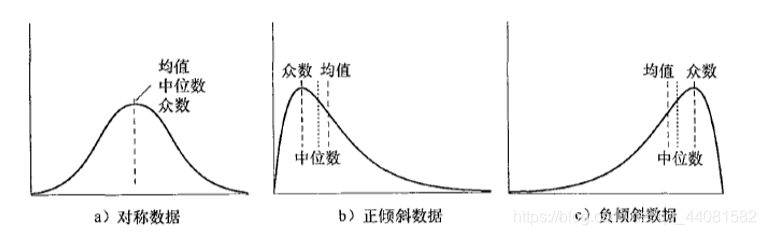
中位数描述数据中心位置的数字特征,大体上比中位数大或小的数据个数为整个数据的一半。 对于对称分布的数据,均值与中位数比较接近;对于偏态分布的数据,均值与中位数不同。在大部分实际应用中,数据都是不对称的,如下图,可能是正倾斜的(b),也可能是负倾斜的(c)。
中位数的显著特点是不受异常值的影响,具有稳健性,因此中位数也是数据分析中相当重要的统计量。
median(x, na.rm = FALSE)
用R计算下组数据中位数
75, 64, 47.4, 66.9, 62.2, 62.2, 58.7, 63.5
median(x, na.rm = FALSE) 是计算中位数函数。 x是数据样本,na.rm=TRUE可以带有缺失值的样本(默认是FALSE)
> data<-c(75, 64, 47.4, 66.9, 62.2, 62.2, 58.7, 63.5)
> result=median(data);result
[1] 62.85
百分位数
百分位数是中位数的推广,下图为某属性X的数据分布图
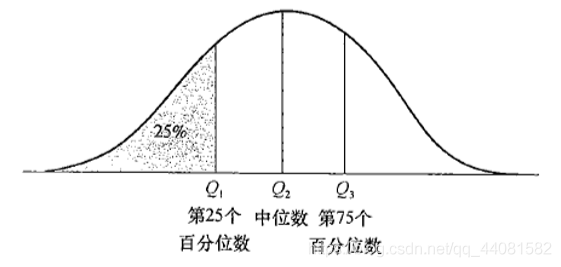
如图所示,Q1,Q2,Q3称为分位数。分位数是取自数据分布的每隔一定间隔的点,把数据划分为基本上大小相等的连贯集合。
二分位数:是一个数据点。相当于是中位数,将数据划分为高低两半。(Q2)
四分位数:是三个数据点。将整个数据分为4个相等部分(Q1,Q2,Q3)
四分位数极差:Q1和Q3的距离。
quantile(x, probs = seq(0, 1, 0.25), na.rm = FALSE,names = TRUE, type = 7, ...)
x为样本,probs指定百分位,默认是:0% 25% 75% 100% ,也可以手动指定。na.rm=TRUE可以处理缺失说明。
例子:计算下列数据的百分位数:
75.0,64.0,47.4,66.9,62.2,62.2,58.7,63.5,66.6,64.0,57.0,69.0,56.9,50.0,72.0
> data<-c(75.0,64.0,47.4,66.9,62.2,62.2,58.7,63.5,66.6,64.0,57.0,69.0,56.9,50.0,72.0)
> result=quantile(data);result
0% 25% 50% 75% 100%
47.40 57.85 63.50 66.75 75.00
将上组数据的分位点变间隔变为20% :
> result=quantile(data,probs=seq(0,1,0.2));result
0% 20% 40% 60% 80% 100%
47.40 56.98 62.20 64.00 67.32 75.00

3.用R计算数据基本统计量(方差)
方差和标准差都是数据散布度量。这两个值越小,意味着数据观测趋向于非常靠近均值。
方差公式:
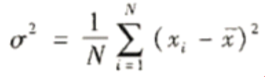
标准差是方差的平方根。
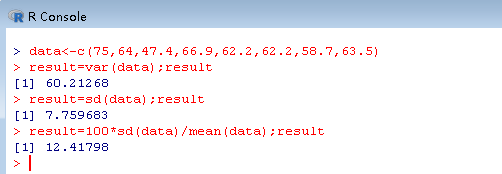
例子:计算学生体重的方差 75,64,47.4,66.9,62.2,62.2,58.7,63.5
计算方差
> data<-c(75,64,47.4,66.9,62.2,62.2,58.7,63.5)
> result=var(data);result
[1] 60.21268
计算标准差
> data<-c(75,64,47.4,66.9,62.2,62.2,58.7,63.5)
> result=sd(data);result
[1] 7.759683
计算变异系数
> data<-c(75,64,47.4,66.9,62.2,62.2,58.7,63.5)
> result=100*sd(data)/mean(data);result
[1] 12.41798
变异系数是标准差与其平均数的比,是一个百分数,用于比较两组数据的散布程度,值越大,越散布。
4.随机变量及其分布(二项分布)
随机变量X(random variable)表示随机试验各种结果的实值单值函数。
描述一个随机变量,不仅要说明它能够取哪些值,而且还要关心它取这些值的概率。因此,引入随机变量的分布函数概念。
对每个随机变量X和每个实数集合A,可以计算X取A中值的概率。所有这些概率的集合就是随机变量X的分布。
随机变量以及分布函数主要有两类:离散型分布和连续型分布。
离散型分布:当X只能取有限个不同值x1,x2,……Xk时,我们称随机变量X服从一个离散型分布。X称为离散型随机变量。比如用随机变量X代表抛一枚硬币的结果,则此时X是离散型随机变量。因为X只能取0或1(正面或背面)。
连续型分布:对实轴的任意子集A,随机变量X落在A中的概率是f在A上的积 分,那么我们说X服从连续型分布或者X是连续型随机变量。一般我们都是讨论X落入子集A的区间[a,b]的概率,则记为:
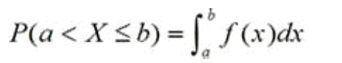
如图:
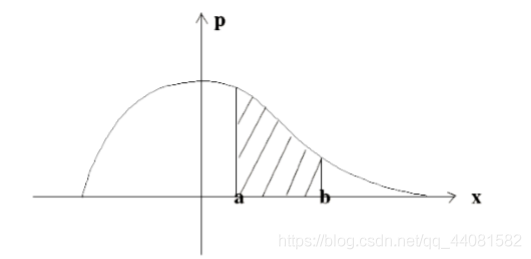
如果对整个曲线做积分,相当于求整个曲线和x轴围成的面积。所以结果是1。所以上式在图中,相当于求a,b区间出现的概率。 针对连续型分布,求一个点的概率是没有意义的(因为面积是0,即概率是0),所以要求一个 区间的概率。
常用的数据分布有如下几种:
常见的一元离散型分布: 整数型均匀分布 二项分布 泊松分布 几何分布 超几何分布
常见的一元连续型分布: 实数型均匀分布 正态分布(高斯分布) γ(伽玛)分布 指数分布 贝塔分布
多元离散型分布: 多项式分布
二元连续型分布: 二元正态分布
还有其他一些分布: weibull(韦伯)分布 F分布 T分布 β(贝塔)分布 χ²(卡方)分布 cauchy分布
其中,最常用和常见的有:正态分布、二项分布、指数分布
均匀分布
均匀分布是一种简单的概率分布,分为离散型均匀分布和连续型均匀分布。
离散型均匀分布指的是整数的均匀分布。设随机变量X可能取1,2,……n, 那么X的概率密度函数为: f(x)=1/n
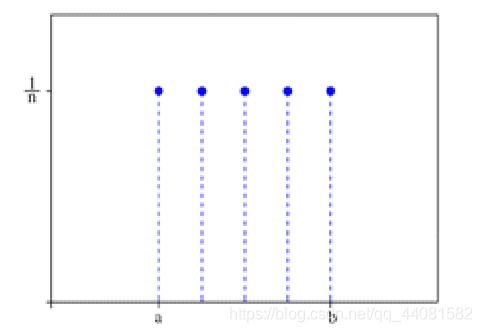
连续型均匀分布指的是实数的均匀分布,在a~b区间上,随机变量可以取任意一点。 那么X的概率密度函数为:f(x)=1/(b-a) a≦x≦b。
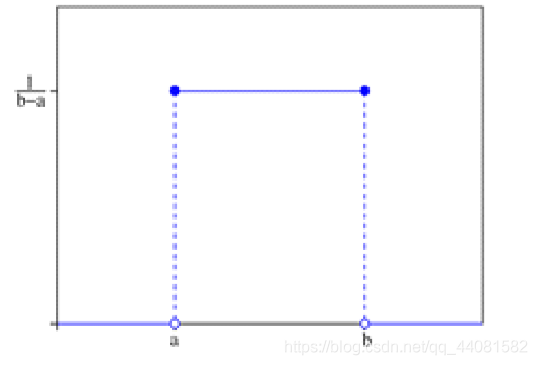
注:在实际生成生活中,如果是均匀分布,一般都是连续型均匀分布。
伯努利分布
伯努利分布是一种离散分布,有两种可能的结果。1表示成功,出现的概率为p(其中0<p<1)。0表示失败,出现的概率为q=1-p。即:若随机变量X所能取的实验结果只有两种结果,则随机变量X服从伯努利分布。
伯努利分布最简单的实验是抛一枚(只一次)硬币出现的结果(正面或反面)。
伯努利分布概率函数:如果随机变量X只取0和1两个值,并且相应的概率为: Pr(X=1)=p,Pr(X=0)=1-p
则X的概率函数可以写为:
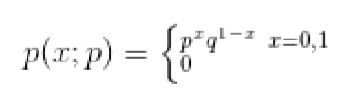
二项分布
二项分布即重复n次独立的伯努利试验。在每次试验中只有两种可能的结果,而且两种结果发生与否互相对立,并且相互独立,与其它各次试验结果无关,事件发生与否的概率在每一次独立试验中都保持不变, 则这一系列试验总称为n重伯努利实验,当试验次数为1时,二项分布就是伯努利分布。
二项分布概率函数:二项分布(Binomial Distribution),即重复n次的伯努利试验(Bernoulli Experiment),用ξ表示随机试验的结果。如果事件发生的概率是p,则不发生的概率q=1-p,n次独立重复试验中发生k次的概率是:
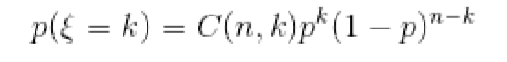
其中,C(n,k)为:
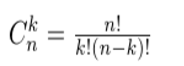
rbinom(n,size,prob)
n是实验次数。prob为单点分布的成功的概率。size为随机数产生范围,从0开始取值。如果是1,则取值为0或1。
利用R语言模拟一次伯努利实验 (伯努利分布)
例如:抛一枚硬币,出现正面记为1,背面记为0,正面和背面出现的概率都为0.5。
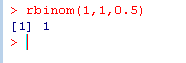
> rbinom(1,1,0.5)
[1] 1
第一个1表示实验一次
第二个1表示随便变量X的取值结果,如果写1,表示去0或1两种情况
第三是概率,表示出现1的概率
实验如图:
画出伯努利分布 (实验一次)的图:
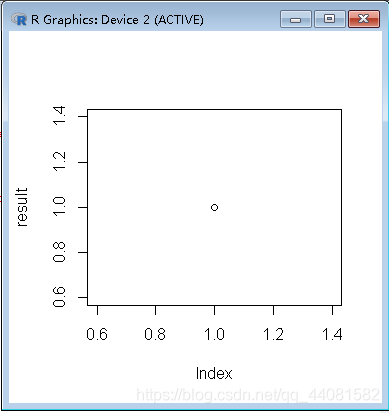
> result=rbinom(1,1,0.5);result
[1] 1
> plot(result)
代码如图:
画出10次伯努利实验的图:
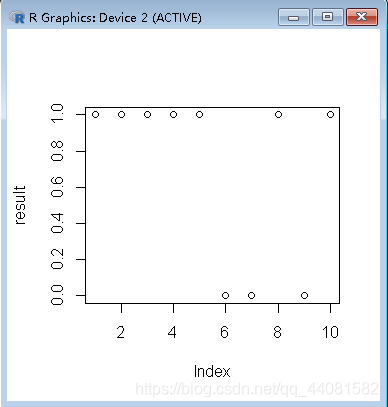
> result=rbinom(10,1,0.5);result
[1] 1 1 1 1 1 0 0 1 0 1
> plot(result)
画出1000次伯努利实验的图,并以线图模拟出实验结果的概率密度:
> result=rbinom(1000,1,0.5);result
> plot(result)
> lines(result)
实验如图:
做1000次伯努利实验,并调整概率为0.2,并模拟出概率密度图来观察结果:
> result=rbinom(1000,1,0.2);result
> plot(result)
> lines(result)
实验如图:
5.随机变量及其分布(正态分布)
正态分布(Normal distribution)又名高斯分布(Gaussian distribution),是一个在数学、物理及工程等领域都非常重要的概率分布,在统计学的许多方面有着重大的影响力。可以说是最重要的一种分布,也是应用最广泛的连续型分布。
正态分布是具有两个参数μ和σ^2的连续型随机变量的分布。
第一参数μ是遵从正态分布的随机变量的均值(期望),这个参数决定了分布的位置。
第二个参数σ^2是此随机变量的方差,这个参数决定了分布的幅度。
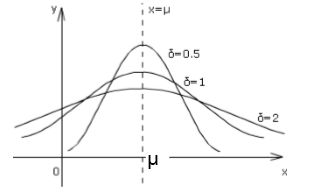
所以正态分布记作N(μ,σ^2 )。 遵从正态分布的随机变量的概率规律为取 μ邻近的值的概率大 ,而取离μ越远的值的概率越小;σ越小,分布越集中在μ附近,σ越大,分布越分散。
当μ=0,σ^2 =1时,称为标准正态分布,记为N(0,1)。
概率密度函数
如果连续型随机变量X的概率密度函数 f(x|μ,σ^2)具有如下形式:
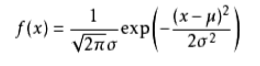
则称X服从均值为μ,方差为σ^2的正态分布。
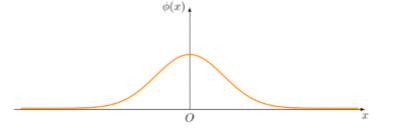
概率密度曲线图
1.标准正态分布图——N(0,1):
2.当随机变量X服从N(μ,0.5),N(μ,0.1),N(μ,2)时的图形:
6.随机变量及其分布(指数分布)
指数分布(Exponential distribution)用来表示独立随机事件发生的时间间隔,许多电子产品的寿命分布一般服从指数分布。它在可靠性研究中是最常用的一种分布形式。
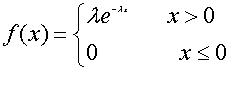
指数分布的区间是[0,∞),上式中λ > 0是分布的一个参数,常被称为率参数(rate parameter)。即每单位时间发生该事件的次数。
如果一个随机变量X 呈指数分布,则可以写作:X ~ Exponential(λ)。指数分布的概率密度图像如下图:
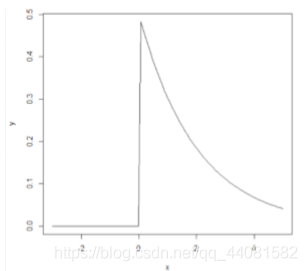
用R模拟指数分布案例
概率密度函数
dexp( ):R中指数分布的概率密度函数
例1
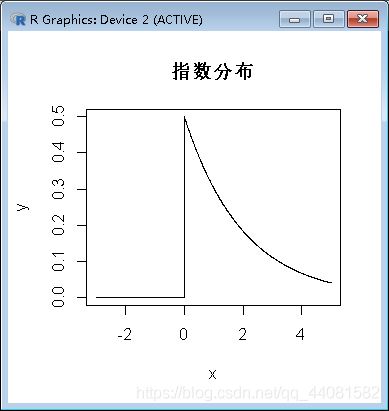
在区间[-3,5]上,随机变量X服从 X ~ Exponential(λ),试绘出 λ=0.5时对应的指数分布曲线
> x<-seq(-3,5,length.out=1000)
> y<-dexp(x,0.5)
> plot(x,y,type="l",main="指数分布")
绘制曲线如下图:(length.out=1000:在指定区间内生成1000个数)
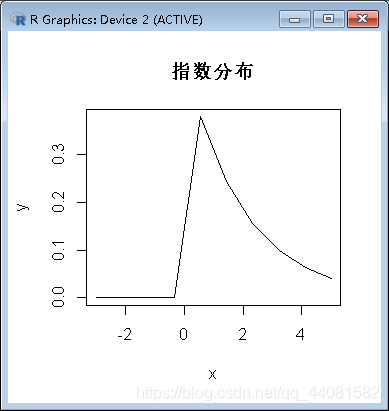
下面是length.out=10时,做出的图像,可以看到与指数函数实际的概率密度图像有着差异:
例2
在区间[0,5]上,绘出 Exponential(0.5), Exponential(1), Exponential(2), Exponential(5)的曲线
代码:
> x<-seq(-3,5,length.out=1000)
> y<-dexp(x,0.5)
> plot(x,y,col="red",xlim=c(0,2),ylim=c(0,5),type="l",ylab="密度",xlab="",main="指数密度分布")
> lines(x,dexp(x,1),col="green")
> lines(x,dexp(x,2),col="blue")
> lines(x,dexp(x,5),col="orange")
> legend("topright",legend=paste("rate=",c(.5,1,2,5)),lwd=1,col=c("red","green","blue","orange"))
结果图:
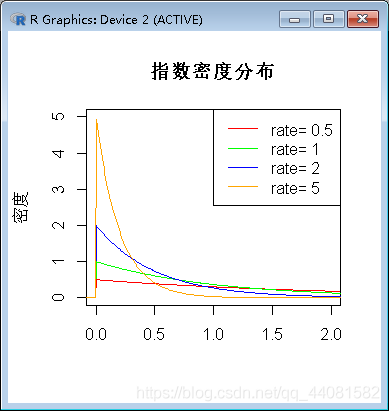
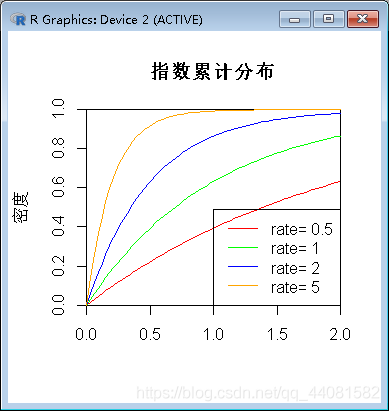
结果显示:λ值越大,图形越陡峭
累计分布函数
pexp():R中指数分布的累计分布函数
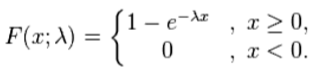
例3
绘出Exponential(0.5), Exponential(1), Exponential(2), Exponential(5)的累计分布曲线
代码:
> x<-seq(-1,2,length.out=100)
> y<-pexp(x,0.5)
> plot(x,y,col="red",xlim=c(0,2),ylim=c(0,1),type="l",xaxs="i",yaxs="i",ylab="密度",xlab="",main="指数累计分布")
> lines(x,pexp(x,1),col="green")
> lines(x,pexp(x,2),col="blue")
> lines(x,pexp(x,5),col="orange")
> legend("bottomright",legend=paste("rate=",c(.5,1,2,5)),lwd=1,col=c("red","green","blue","orange"))
结果图:
分布检验
检验一组样本是否满足指数分布
rexp():用于生成满足指数分布的样本数据
ks.test():Kolmogorov-Smirnov连续分布检验:检验单一样本是不是服从某一预先假设的特定分布的方法,根据的是此样本的累计分布函数来检验。
统计量D值越小,越接近0,表示样本数据越接近指数分布p值,如果p-value小于显著性水平α(0.05),说明不服从指数分布
R语言学习数据挖掘的更多相关文章
- R语言文本数据挖掘(二)
tm文本挖掘示例 文本挖掘是从非结构化的文本信息中抽取潜在的.用户感兴趣的重要模式或知识的过程,可以把它看作数据挖掘或数据库中知识发现的延伸.对文本信息的挖掘主要是以数理统计学和计算语言学为理论基础, ...
- R语言学习 第四篇:函数和流程控制
变量用于临时存储数据,而函数用于操作数据,实现代码的重复使用.在R中,函数只是另一种数据类型的变量,可以被分配,操作,甚至把函数作为参数传递给其他函数.分支控制和循环控制,和通用编程语言的风格很相似, ...
- R语言文本数据挖掘(一)
文本挖掘可以视为NLP(Natural language processing,自然语言处理)的一个子领域,目标是在大量非结构化文本中整理析取出有价值的内容.由于人类语言具有很高的复杂性,例如不同语言 ...
- R语言学习路线和常用数据挖掘包(转)
对于初学R语言的人,最常见的方式是:遇到不会的地方,就跑到论坛上吼一嗓子,然后欣然or悲伤的离去,一直到遇到下一个问题再回来.当然,这不是最好的学习方式,最好的方式是——看书.目前,市面上介绍R语言的 ...
- R语言文本数据挖掘(四)
文本分词,就是对文本进行合理的分割,从而可以比较快捷地获取关键信息.例如,电商平台要想了解更多消费者的心声,就需要对消费者的文本评论数据进行内在信息的数据挖掘分析,而文本分词是文本挖掘的重要步骤.R语 ...
- R语言文本数据挖掘(三)
文本分词,就是对文本进行合理的分割,从而可以比较快捷地获取关键信息.例如,电商平台要想了解更多消费者的心声,就需要对消费者的文本评论数据进行内在信息的数据挖掘分析,而文本分词是文本挖掘的重要步骤.R语 ...
- R语言学习笔记之: 论如何正确把EXCEL文件喂给R处理
博客总目录:http://www.cnblogs.com/weibaar/p/4507801.html ---- 前言: 应用背景兼吐槽 继续延续之前每个月至少一次更新博客,归纳总结学习心得好习惯. ...
- R语言学习笔记(二)
今天主要学习了两个统计学的基本概念:峰度和偏度,并且用R语言来描述. > vars<-c("mpg","hp","wt") &g ...
- R语言学习笔记:小试R环境
买了三本R语言的书,同时使用来学习R语言,粗略翻下来感觉第一本最好: <R语言编程艺术>The Art of R Programming <R语言初学者使用>A Beginne ...
- R语言学习——根据信息熵建决策树KD3
R语言代码 决策树的构建 rm(list=ls()) setwd("C:/Users/Administrator/Desktop/R语言与数据挖掘作业/实验3-决策树分类") #s ...
随机推荐
- 牛客多校H题题解
链接:[https://ac.nowcoder.com/acm/contest/81597/H] 来源:牛客网 题目描述 Red stands at the coordinate \((0,0)\) ...
- Go语言net/http包源码学习
0.前言 该笔记为笔者第一次学习go的net/http包源码的时候所记,也许写的并不是很精确,希望大家多多包涵,一起讨论学习. 该笔记很大程度的参考了网名为"小徐先生"的前辈所分享 ...
- TSCTF-J2024 密码向WP(5/8)
ezRSA part 1 #part1 p = getPrime(512) q = getPrime(512) n = p * q phi = (p-1) * (q-1) d = getPrime(2 ...
- git cherry-pick 同事代码commit后 如何修改为自己的author
如果有个功能是同事在做,但是做到一半,需要接手帮忙修改或者完成后续,可以切入他的分支 git checkout 分支名称 直接开发,也可以 git checkout -b 新分支名称 这样就完全拥有他 ...
- Redis中有事务吗?有何不同?
与关系型数据库事务的区别 Redis事务是指将多条命令加入队列,一次批量执行多条命令,每条命令会按顺序执行,事务执行过程中不会被其他客户端发来的命令所打断.也就是说,Redis事务就是一次性.顺序性. ...
- 高性能计算-雅可比算法MPI通信优化(5)
雅可比算法原理:如下图对方阵非边界元素求上下左右元素的均值,全部计算元素的数值计算完成后更新矩阵,进行下一次迭代. 测试目标:用MPI实现对8*8方阵雅可比算法迭代并行计算,用重复非阻塞的通信方式 # ...
- AbstractQueuedSynchronizer源码解析之ReentrantLock(二)
上篇文章分析了ReentrantLock的lock,tryLock,unlock方法,继续分析剩下的方法,首先开始lockInterruptibly,先看其API说明:lockInterruptibl ...
- 利用 word VBA 将投标文件偏离参数表列数据拷贝至技术偏差表中
使用 vba 将正偏离参数表的第一列信息复制粘贴至对应的技术偏离表的第4列中.需要同时打开两个 word 文件,在技术偏差表中打开 VBE(可以用ctrl + f11 快捷键),插入模块. 忽略格式的 ...
- 案例 | 销讯通加持药企SFE部门效能提升
为了获取更大的市场空间,医药健康行业正迎来一波前所未有的产业升级.尽管不少企业取得了许多成绩,但仍面临诸多挑战. 江苏某制药公司在心脑血管.中枢神经.胃肠内科.心脏科.内分泌科.皮肤科和风湿科等领域均 ...
- SQLServer无法远程连接的解决方法
服务器端: 打开SQLServer配置管理器 - SQLServer 网络配置- MSSQLSERVER的协议-TCP/IP 启用 运行输入Services.msc,重启MSSQLSERVER服务. ...