w3cschool-Go 教程
https://www.w3cschool.cn/go/
Go是从2007年末由Robert Griesemer, Rob Pike, Ken Thompson主持开发,后来还加入了Ian Lance Taylor, Russ Cox等人,并最终于2009年11月开源,在2012年早些时候发布了Go 1稳定版本。现在Go的开发已经是完全开放的,并且拥有一个活跃的社区。
Go 语言特色
- 简洁、快速、安全
- 并行、有趣、开源
- 内存管理、数组安全、编译迅速
Go 语言用途
Go 语言被设计成一门应用于搭载 Web 服务器,存储集群或类似用途的巨型中央服务器的系统编程语言。
对于高性能分布式系统领域而言,Go 语言无疑比大多数其它语言有着更高的开发效率。它提供了海量并行的支持,这对于游戏服务端的开发而言是再好不过了。
UNIX/Linux/Mac OS X, 和 FreeBSD 安装
以下介绍了在UNIX/Linux/Mac OS X, 和 FreeBSD系统下使用源码安装方法:
1、下载源码包:go1.15.2.linux-amd64.tar.gz。
2、将下载的源码包解压至 /usr/local目录。
tar -C /usr/local -xzf go1.15.2.linux-amd64.tar.gz
3、将 /usr/local/go/bin 目录添加至PATH环境变量:
export PATH=$PATH:/usr/local/go/bin
4、验证是否安装成功命令:
$ go version关键字
下面列举了 Go 代码中会使用到的 25 个关键字或保留字:
| break | default | func | interface | select |
| case | defer | go | map | struct |
| chan | else | goto | package | switch |
| const | fallthrough | if | range | type |
| continue | for | import | return | var |
除了以上介绍的这些关键字,Go 语言还有 36 个预定义标识符:
| append | bool | byte | cap | close | complex | complex64 | complex128 | uint16 |
| copy | false | float32 | float64 | imag | int | int8 | int16 | uint32 |
| int32 | int64 | iota | len | make | new | nil | panic | uint64 |
| println | real | recover | string | true | uint | uint8 | uintptr |
程序一般由关键字、常量、变量、运算符、类型和函数组成。
程序中可能会使用到这些分隔符:括号 (),中括号 [] 和大括号 {}。
程序中可能会使用到这些标点符号:.、,、;、: 和 …。
Go 语言数据类型
在 Go 编程语言中,数据类型用于声明函数和变量。
数据类型的出现是为了把数据分成所需内存大小不同的数据,编程的时候需要用大数据的时候才需要申请大内存,就可以充分利用内存。
Go 语言按类别有以下几种数据类型:
| 序号 | 类型和描述 |
|---|---|
| 1 | 布尔型 布尔型的值只可以是常量 true 或者 false。一个简单的例子:var b bool = true。 |
| 2 | 数字类型 整型 int 和浮点型 float,Go 语言支持整型和浮点型数字,并且原生支持复数,其中位的运算采用补码。 |
| 3 | 字符串类型: 字符串就是一串固定长度的字符连接起来的字符序列。Go的字符串是由单个字节连接起来的。Go语言的字符串的字节使用UTF-8编码标识Unicode文本。 |
| 4 | 派生类型: 包括:
|
数字类型
Go 也有基于架构的类型,例如:int、uint 和 uintptr。
| 序号 | 类型和描述 |
|---|---|
| 1 | uint8 无符号 8 位整型 (0 到 255) |
| 2 | uint16 无符号 16 位整型 (0 到 65535) |
| 3 | uint32 无符号 32 位整型 (0 到 4294967295) |
| 4 | uint64 无符号 64 位整型 (0 到 18446744073709551615) |
| 5 | int8 有符号 8 位整型 (-128 到 127) |
| 6 | int16 有符号 16 位整型 (-32768 到 32767) |
| 7 | int32 有符号 32 位整型 (-2147483648 到 2147483647) |
| 8 | int64 有符号 64 位整型 (-9223372036854775808 到 9223372036854775807) |
浮点型:
| 序号 | 类型和描述 |
|---|---|
| 1 | float32 IEEE-754 32位浮点型数 |
| 2 | float64 IEEE-754 64位浮点型数 |
| 3 | complex64 32 位实数和虚数 |
| 4 | complex128 64 位实数和虚数 |
其他数字类型
以下列出了其他更多的数字类型:
| 序号 | 类型和描述 |
|---|---|
| 1 | byte 类似 uint8 |
| 2 | rune 类似 int32 |
| 3 | uint 32 或 64 位 |
| 4 | int 与 uint 一样大小 |
| 5 | uintptr 无符号整型,用于存放一个指针 |
Go 语言变量
变量来源于数学,是计算机语言中能储存计算结果或能表示值的抽象概念。变量可以通过变量名访问。
Go 语言变量名由字母、数字、下划线组成,其中首个字母不能为数字。
声明变量的一般形式是使用 var 关键字:
var identifier type
变量声明
第一种,指定变量类型,声明后若不赋值,使用默认值。
var v_name v_type
v_name = value
第二种,根据值自行判定变量类型。
var v_name = value
第三种,省略var, 注意 :=左侧的变量不应该是已经声明过的,否则会导致编译错误。
v_name := value
// 例如
var a int = 10
var b = 10
c := 10
实例如下:
package main
var a = "w3cschoolW3Cschool教程"
var b string = "w3cschool.cn"
var c bool
func main(){
println(a, b, c)
}Go 语言常量
常量是一个简单值的标识符,在程序运行时,不会被修改的量。
常量中的数据类型只可以是布尔型、数字型(整数型、浮点型和复数)和字符串型。
常量的定义格式:
const identifier [type] = value你可以省略类型说明符 [type],因为编译器可以根据变量的值来推断其类型。
- 显式类型定义:
const b string = "abc" - 隐式类型定义:
const b = "abc"
多个相同类型的声明可以简写为:
const c_name1, c_name2 = value1, value2以下实例演示了常量的应用:
package main
import "fmt"
func main() {
const LENGTH int = 10
const WIDTH int = 5
var area int
const a, b, c = 1, false, "str" //多重赋值
area = LENGTH * WIDTH
fmt.Printf("面积为 : %d", area)
println()
println(a, b, c)
}
尝试一下
以上实例运行结果为:
面积为 : 50
1 false str常量还可以用作枚举:
const (
Unknown = 0
Female = 1
Male = 2
)
数字 0、1 和 2 分别代表未知性别、女性和男性。
常量可以用len(), cap(), unsafe.Sizeof()常量计算表达式的值。常量表达式中,函数必须是内置函数,否则编译不通过:
package main
import "unsafe"
const (
a = "abc"
b = len(a)
c = unsafe.Sizeof(a)
)
func main(){
println(a, b, c)
}Go 语言运算符
运算符用于在程序运行时执行数学或逻辑运算。
Go 语言内置的运算符有:
- 算术运算符
- 关系运算符
- 逻辑运算符
- 位运算符
- 赋值运算符
- 其他运算符
Go 语言 switch 语句
Go 语言 switch 语句
 Go 语言条件语句
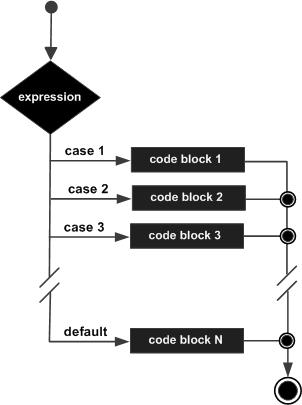
Go 语言条件语句switch 语句用于基于不同条件执行不同动作,每一个 case 分支都是唯一的,从上直下逐一测试,直到匹配为止。
switch 语句执行的过程从上至下,直到找到匹配项,匹配项后面也不需要再加break
语法
Go 编程语言中 switch 语句的语法如下:
switch var1 {
case val1:
...
case val2:
...
default:
...
}
变量 var1 可以是任何类型,而 val1 和 val2 则可以是同类型的任意值。类型不被局限于常量或整数,但必须是相同的类型;或者最终结果为相同类型的表达式。
您可以同时测试多个可能符合条件的值,使用逗号分割它们,例如:case val1, val2, val3。
流程图:
实例
package main
import "fmt"
func main() {
/* 定义局部变量 */
var grade string = "B"
var marks int = 90
switch marks {
case 90: grade = "A"
case 80: grade = "B"
case 50,60,70 : grade = "C"
default: grade = "D"
}
switch {
case grade == "A" :
fmt.Printf("优秀!\n" )
case grade == "B", grade == "C" :
fmt.Printf("良好\n" )
case grade == "D" :
fmt.Printf("及格\n" )
case grade == "F":
fmt.Printf("不及格\n" )
default:
fmt.Printf("差\n" )
}
fmt.Printf("你的等级是 %s\n", grade )
}Go 语言函数
函数是基本的代码块,用于执行一个任务。
Go 语言最少有1个 main() 函数。
你可以通过函数来划分不同功能,逻辑上每个函数执行的是指定的任务。
函数声明告诉了编译器函数的名称,返回类型和参数。
Go 语言标准库提供了多种可动用的内置的函数。例如,len() 函数可以接受不同类型参数并返回该类型的长度。如果我们传入的是字符串则返回字符串的长度,如果传入的是数组,则返回数组中包含的分量个数。
函数定义
Go 语言函数定义格式如下:
func function_name( [parameter list] ) [return_types]{
函数体
}
函数定义解析:
- func:函数由 func 开始声明
- function_name:函数名称,函数名和参数列表一起构成了函数签名。
- parameter list]:参数列表,参数就像一个占位符,当函数被调用时,你可以将值传递给参数,这个值被称为实际参数。参数列表指定的是参数类型、顺序及参数个数。参数是可选的,也就是说函数也可以不包含参数。
- return_types:返回类型,函数返回一列值。return_types 是该列值的数据类型。有些功能不需要返回值,这种情况下 return_types 不是必须的。
- 函数体:函数定义的代码集合。
实例
以下实例为 max() 函数的代码,该函数传入两个整型参数 num1 和 num2,并返回这两个参数的最大值:
/* 函数返回两个数的最大值 */
func max(num1, num2 int) int{
/* 声明局部变量 */
var result int
if (num1 > num2) {
result = num1
} else {
result = num2
}
return result
}
函数调用
当创建函数时,你定义了函数需要做什么,通过调用该函数来执行指定任务。
调用函数,向函数传递参数,并返回值,例如:
package main
import "fmt"
func main() {
/* 定义局部变量 */
var a int = 100
var b int = 200
var ret int
/* 调用函数并返回最大值 */
ret = max(a, b)
fmt.Printf( "最大值是 : %d\n", ret )
}
/* 函数返回两个数的最大值 */
func max(num1, num2 int) int {
/* 定义局部变量 */
var result int
if (num1 > num2) {
result = num1
} else {
result = num2
}
return result
}Go 语言数组
Go 语言提供了数组类型的数据结构。
数组是具有相同唯一类型的一组已编号且长度固定的数据项序列,这种类型可以是任意的原始类型例如整型、字符串或者自定义类型。
相对于去声明number0, number1, ..., and number99的变量,使用数组形式numbers[0], numbers[1] ..., numbers[99]更加方便且易于扩展。
数组元素可以通过索引(位置)来读取(或者修改),索引从0开始,第一个元素索引为 0,第二个索引为 1,以此类推。

声明数组
Go 语言数组声明需要指定元素类型及元素个数,语法格式如下:
var variable_name [SIZE] variable_type
以上为一维数组的定义方式。数组长度必须是整数且大于 0。例如以下定义了数组 balance 长度为 10,类型为 float32:
var balance [10] float32
初始化数组
以下演示了数组初始化:
var balance = [5]float32{1000.0, 2.0, 3.4, 7.0, 50.0}
初始化数组中 {} 中的元素个数不能大于 [] 中的数字。
如果忽略 [] 中的数字不设置数组大小,Go 语言会根据元素的个数来设置数组的大小:
var balance = []float32{1000.0, 2.0, 3.4, 7.0, 50.0}
该实例与上面的实例是一样的,虽然没有设置数组的大小。
balance[4] = 50.0
以上实例读取了第五个元素。数组元素可以通过索引(位置)来读取(或者修改),索引从0开始,第一个元素索引为 0,第二个索引为 1,以此类推。

访问数组元素
数组元素可以通过索引(位置)来读取。格式为数组名后加中括号,中括号中为索引的值。例如:
float32 salary = balance[9]
以上实例读取了数组balance第10个元素的值。
以下演示了数组完整操作(声明、赋值、访问)的实例:
package main
import "fmt"
func main() {
var n [10]int /* n 是一个长度为 10 的数组 */
var i,j int
/* 为数组 n 初始化元素 */
for i = 0; i < 10; i++ {
n[i] = i + 100 /* 设置元素为 i + 100 */
}
/* 输出每个数组元素的值 */
for j = 0; j < 10; j++ {
fmt.Printf("Element[%d] = %d\n", j, n[j] )
}
}Go 语言指针
Go 语言中指针是很容易学习的,Go 语言中使用指针可以更简单的执行一些任务。
接下来让我们来一步步学习 Go 语言指针。
我们都知道,变量是一种使用方便的占位符,用于引用计算机内存地址。
Go 语言的取地址符是 &,放到一个变量前使用就会返回相应变量的内存地址。
以下实例演示了变量在内存中地址:
package main
import "fmt"
func main() {
var a int = 10
fmt.Printf("变量的地址: %x\n", &a )
}
尝试一下
执行以上代码输出结果为:
变量的地址: 20818a220
现在我们已经了解了什么是内存地址和如何去访问它。接下来我们将具体介绍指针。
什么是指针
一个指针变量可以指向任何一个值的内存地址它指向那个值的内存地址。
类似于变量和常量,在使用指针前你需要声明指针。指针声明格式如下:
var var_name *var-type
var-type 为指针类型,var_name 为指针变量名,* 号用于指定变量是作为一个指针。以下是有效的指针声明:
var ip *int /* 指向整型*/
var fp *float32 /* 指向浮点型 */
本例中这是一个指向 int 和 float32 的指针。
如何使用指针
指针使用流程:
- 定义指针变量。
- 为指针变量赋值。
- 访问指针变量中指向地址的值。
在指针类型前面加上 * 号(前缀)来获取指针所指向的内容。
package main
import "fmt"
func main() {
var a int= 20 /* 声明实际变量 */
var ip *int /* 声明指针变量 */
ip = &a /* 指针变量的存储地址 */
fmt.Printf("a 变量的地址是: %x\n", &a )
/* 指针变量的存储地址 */
fmt.Printf("ip 变量的存储地址: %x\n", ip )
/* 使用指针访问值 */
fmt.Printf("*ip 变量的值: %d\n", *ip )
}Go 语言结构体
Go 语言中数组可以存储同一类型的数据,但在结构体中我们可以为不同项定义不同的数据类型。
结构体是由一系列具有相同类型或不同类型的数据构成的数据集合。
结构体表示一项记录,比如保存图书馆的书籍记录,每本书有以下属性:
- Title :标题
- Author : 作者
- Subject:学科
- ID:书籍ID
定义结构体
结构体定义需要使用 type 和 struct 语句。struct 语句定义一个新的数据类型,结构体中有一个或多个成员。type 语句设定了结构体的名称。结构体的格式如下:
type struct_variable_type struct {
member definition
member definition
...
member definition
}
一旦定义了结构体类型,它就能用于变量的声明,语法格式如下:
variable_name := structure_variable_type {value1, value2...valuen}
访问结构体成员
如果要访问结构体成员,需要使用点号 (.) 操作符,格式为:"结构体.成员名"。
结构体类型变量使用struct关键字定义,实例如下:
package main
import "fmt"
type Books struct {
title string
author string
subject string
book_id int
}
func main() {
var Book1 Books /* 声明 Book1 为 Books 类型 */
var Book2 Books /* 声明 Book2 为 Books 类型 */
/* book 1 描述 */
Book1.title = "Go 语言"
Book1.author = "www.w3cschool.cn"
Book1.subject = "Go 语言教程"
Book1.book_id = 6495407
/* book 2 描述 */
Book2.title = "Python 教程"
Book2.author = "www.w3cschool.cn"
Book2.subject = "Python 语言教程"
Book2.book_id = 6495700
/* 打印 Book1 信息 */
fmt.Printf( "Book 1 title : %s\n", Book1.title)
fmt.Printf( "Book 1 author : %s\n", Book1.author)
fmt.Printf( "Book 1 subject : %s\n", Book1.subject)
fmt.Printf( "Book 1 book_id : %d\n", Book1.book_id)
/* 打印 Book2 信息 */
fmt.Printf( "Book 2 title : %s\n", Book2.title)
fmt.Printf( "Book 2 author : %s\n", Book2.author)
fmt.Printf( "Book 2 subject : %s\n", Book2.subject)
fmt.Printf( "Book 2 book_id : %d\n", Book2.book_id)
}Go 语言切片(Slice)
Go 语言切片是对数组的抽象。
Go 数组的长度不可改变,在特定场景中这样的集合就不太适用,Go中提供了一种灵活,功能强悍的内置类型切片("动态数组"),与数组相比切片的长度是不固定的,可以追加元素,在追加时可能使切片的容量增大。
定义切片
你可以声明一个未指定大小的数组来定义切片:
var identifier []type
切片不需要说明长度。
或使用make()函数来创建切片:
var slice1 []type = make([]type, len)
也可以简写为
slice1 := make([]type, len)也可以指定容量,其中capacity为可选参数。
make([]T, length, capacity)
这里 len 是数组的长度并且也是切片的初始长度。
切片初始化
s :=[] int {1,2,3 }
直接初始化切片,[]表示是切片类型,{1,2,3}初始化值依次是1,2,3.其cap=len=3
s := arr[:]
初始化切片s,是数组arr的引用
s := arr[startIndex:endIndex]
将arr中从下标startIndex到endIndex-1 下的元素创建为一个新的切片
s := arr[startIndex:]
缺省endIndex时将表示一直到arr的最后一个元素
s := arr[:endIndex]
缺省startIndex时将表示从arr的第一个元素开始
s1 := s[startIndex:endIndex]
通过切片s初始化切片s1
s :=make([]int,len,cap)
通过内置函数make()初始化切片s,[]int 标识为其元素类型为int的切片
len() 和 cap() 函数
切片是可索引的,并且可以由 len() 方法获取长度。
切片提供了计算容量的方法 cap() 可以测量切片最长可以达到多少。
以下为具体实例:
package main
import "fmt"
func main() {
var numbers = make([]int,3,5)
printSlice(numbers)
}
func printSlice(x []int){
fmt.Printf("len=%d cap=%d slice=%v\n",len(x),cap(x),x)
}Go 语言范围(Range)
Go 语言中 range 关键字用于for循环中迭代数组(array)、切片(slice)、通道(channel)或集合(map)的元素。在数组和切片中它返回元素的索引值,在集合中返回 key-value 对的 key 值。
对于映射,它返回下一个键值对的键。Range返回一个值或两个值。如果在Range表达式的左侧只使用了一个值,则该值是下表中的第一个值。
| Range表达式 | 第一个值 | 第二个值[可选的] |
| Array 或者 slice a [n]E | 索引 i int | a[i] E |
| String s string type | 索引 i int | rune int |
| map m map[K]V | 键 k K | 值 m[k] V |
| channel c chan E | 元素 e E | none |
实例
package main
import "fmt"
func main() {
//这是我们使用range去求一个slice的和。使用数组跟这个很类似
nums := []int{2, 3, 4}
sum := 0
for _, num := range nums {
sum += num
}
fmt.Println("sum:", sum)
//在数组上使用range将传入index和值两个变量。上面那个例子我们不需要使用该元素的序号,所以我们使用空白符"_"省略了。有时侯我们确实需要知道它的索引。
for i, num := range nums {
if num == 3 {
fmt.Println("index:", i)
}
}
//range也可以用在map的键值对上。
kvs := map[string]string{"a": "apple", "b": "banana"}
for k, v := range kvs {
fmt.Printf("%s -> %s\n", k, v)
}
//range也可以用来枚举Unicode字符串。第一个参数是字符的索引,第二个是字符(Unicode的值)本身。
for i, c := range "go" {
fmt.Println(i, c)
}
}Go 语言递归函数
递归,就是在运行的过程中调用自己。
语法格式如下:
func recursion() {
recursion() /* 函数调用自身 */
}
func main() {
recursion()
}
Go 语言接口
Go 语言提供了另外一种数据类型即接口,它把所有的具有共性的方法定义在一起,任何其他类型只要实现了这些方法就是实现了这个接口。
实例
/* 定义接口 */
type interface_name interface {
method_name1 [return_type]
method_name2 [return_type]
method_name3 [return_type]
...
method_namen [return_type]
}
/* 定义结构体 */
type struct_name struct {
/* variables */
}
/* 实现接口方法 */
func (struct_name_variable struct_name) method_name1() [return_type] {
/* 方法实现 */
}
...
func (struct_name_variable struct_name) method_namen() [return_type] {
/* 方法实现*/
}
实例
package main
import (
"fmt"
)
type Phone interface {
call()
}
type NokiaPhone struct {
}
func (nokiaPhone NokiaPhone) call() {
fmt.Println("I am Nokia, I can call you!")
}
type IPhone struct {
}
func (iPhone IPhone) call() {
fmt.Println("I am iPhone, I can call you!")
}
func main() {
var phone Phone
phone = new(NokiaPhone)
phone.call()
phone = new(IPhone)
phone.call()
}Go 语言并发
基本概念
并发与并行
并发:同一时间段内执行多个任务(你早上在编程狮学习Java和Python)
并行:同一时刻执行多个任务(你和你的网友早上都在使用编程狮学习Go)
Go语言中的并发程序主要是通过基于CSP(communicating sequential processes)的goroutine和channel来实现,当然也支持使用传统的多线程共享内存的并发方式
goroutine
Go语言中使用goroutine非常简单,只需要在函数或者方法前面加上go关键字就可以创建一个goroutine,从而让该函数或者方法在新的goroutine中执行
匿名函数同样也支持使用go关键字来创建goroutine去执行
一个goroutine必定对应一个函数或者方法,可以创建多个goroutine去执行相同的函数或者方法
启动单个goroutine
启动方式非常简单,我们先来看一个案例
package main
import (
"fmt"
)
func hello() {
fmt.Println("hello")
}
func main() {
go hello()
fmt.Println("欢迎来到编程狮")
}尝试一下
以上代码输出结果如下
欢迎来到编程狮上述代码执行结果只在终端控制台输出了“欢迎来到编程狮”,并没有打印“hello”,这是为什么呢 ?.
其实在Go程序中,会默认为main函数创建一个goroutine,而在上述代码中我们使用go关键字创建了一个新的goroutine去调用hello函数。而此时main的goroutine还在往下执行中,我们的程序中存在两个并发执行的goroutine。当main函数结束时,整个程序也结束了,所有由main函数创建的子goroutine也会跟着退出,也就是说我们的main函数执行过快退出导致另一个goroutine内容还未执行就退出了,导致未能打印出hello
所以我们这边要想办法让main函数等一等,让另一个goroutine的内容执行完。其中最简单的方法就是在main函数中使用time.sleep睡眠一秒钟
按如下方式修改
package main
import (
"fmt"
"time"
)
func hello(){
fmt.Println("hello")
}
func main() {
go hello()
fmt.Println("欢迎来到编程狮")
time.Sleep(time.Second)
}尝试一下
此时的输出结果为
欢迎来到编程狮
hello
为什么会先打印欢迎来到编程狮呢?
这是因为在程序中创建 goroutine 执行函数需要一定的开销,而与此同时 main 函数所在的 goroutine 是继续执行的。
sync.WaitGroup
在上述代码中使用time.sleep的方法是不准确的
Go语言中的sync包为我们提供了一些常用的并发原语
在这一小节,我们介绍一下sync包中的WaitGroup。当你并不关心并发操作的结果或者有其它方式收集并发操作的结果时,WaitGroup是实现等待一组并发操作完成的好方法
我们再修改下上述代码
package main
import (
"fmt"
"sync"
)
var wg sync.WaitGroup
func hello() {
fmt.Println("hello")
defer wg.Done()//把计算器-1
}
func main() {
wg.Add(1)//把计数器+1
go hello()
fmt.Println("欢迎来到编程狮")
wg.Wait()//阻塞代码的运行,直到计算器为0
}尝试一下
以上代码输出结果如下
欢迎来到编程狮
hello启动多个goroutine
在Go语言中启动并发就是这么简单,接下来我们看看如何启动多个goroutine
package main
import (
"fmt"
"sync"
)
var wg sync.WaitGroup
func hello(i int) {
fmt.Printf("hello,欢迎来到编程狮%v\n", i)
defer wg.Done()//goroutine结束计数器-1
}
func main() {
for i := 0; i < 10; i++ {
go hello(i)
wg.Add(1)//启动一个goroutine计数器+1
}
wg.Wait()//等待所有的goroutine执行结束
}尝试一下
以上代码执行结果如下
hello,欢迎来到编程狮6
hello,欢迎来到编程狮9
hello,欢迎来到编程狮4
hello,欢迎来到编程狮7
hello,欢迎来到编程狮8
hello,欢迎来到编程狮0
hello,欢迎来到编程狮3
hello,欢迎来到编程狮2
hello,欢迎来到编程狮1
hello,欢迎来到编程狮5执行多次上述代码你会发现输出顺序并不一致,这是因为10个goroutine都是并发执行的,而goroutine的调度是随机的
动态栈
操作系统的线程一般都有固定的栈内存(通常为2MB),而 Go 语言中的 goroutine 非常轻量级,一个 goroutine 的初始栈空间很小(一般为2KB),所以在 Go 语言中一次创建数万个 goroutine 也是可能的。并且 goroutine 的栈不是固定的,可以根据需要动态地增大或缩小, Go 的 runtime 会自动为 goroutine 分配合适的栈空间。
goroutine调度
在经过数个版本迭代之后,目前Go语言的调度器采用的是GPM调度模型
- G: 表示goroutine,存储了goroutine的执行stack信息、goroutine状态以及goroutine的任务函数等;另外G对象是可以重用的。
- P: 表示逻辑processor,P的数量决定了系统内最大可并行的G的数量(前提:系统的物理cpu核数>=P的数量);P的最大作用还是其拥有的各种G对象队列、链表、一些cache和状态。
- M: M代表着真正的执行计算资源。在绑定有效的p后,进入schedule循环;而schedule循环的机制大致是从各种队列、p的本地队列中获取G,切换到G的执行栈上并执行G的函数,调用goexit做清理工作并回到m,如此反复。M并不保留G状态,这是G可以跨M调度的基础。
GOMAXPROCS
Go运行时,调度器使用GOMAXPROCS的参数来决定需要使用多少个OS线程来同时执行Go代码。默认值是当前计算机的CPU核心数。例如在一个8核处理器的电脑上,GOMAXPROCS默认值为8。Go语言中可以使用runtime.GOMAXPROCS()函数设置当前程序并发时占用的CPU核心数
channel
单纯地将函数并发执行是没有意义的,函数与函数间需要交换数据才能体现并发执行函数的意义
虽然可以使用共享内存进行数据交换,但是共享内存在不同的 goroutine 中容易发生竞态问题。为了保证数据交换的正确性,很多并发模型中必须使用互斥锁对内存进行加锁,这种做法势必造成性能问题
Go语言采用的并发模型是CSP(Communicating Sequential Processes),提倡通过通信共享内存,而不是通过共享内存而实现通信
Go 语言中的通道(channel)是一种特殊的类型。通道像一个传送带或者队列,总是遵循先入先出的规则,保证收发数据的顺序。每一个通道都是一个具体类型的导管,也就是声明channel的时候需要为其指定元素类型。
channel类型
声明通道类型变量方法如下
var 变量名 chan 元素类型其中chan是关键字,元素类型指通道中传递的元素的类型
举几个例子
var a chan int //声明一个传递int类型的通道
var b chan string // 声明一个传递string类型的通道
var c chan bool //声明一个传递bool类型的通道channel零值
未经初始化的通道默认值为nil
package main
import "fmt"
func main() {
var a chan map[int]string
fmt.Println(a)
}以上代码执行结果如下
<nil>初始化channel
声明的通道类型变量需要使用内置的make函数初始化之后才能使用,具体格式如下
make(chan 元素类型,[缓冲大小])channel的缓冲大小是可选的
a:=make(chan int)
b:=make(chan int,10)//声明一个缓冲大小为10的通道channel操作
通道共有发送,接收,关闭三种操作,而发送和接收操作均用<-符号,举几个例子
- 声明通道并初始化
a := make(chan int) //声明一个通道并初始化- 给一个通道发送值
a <- 10 //把10发送给a通道- 从一个通道中取值
x := <-a //x从a通道中取值
<-a //从a通道中取值,忽略结果- 关闭通道
close(a) //关闭通道一个通道值是可以被垃圾回收掉的。通道通常由发送方执行关闭操作,并且只有在接收方明确等待通道关闭的信号时才需要执行关闭操作。它和关闭文件不一样,通常在结束操作之后关闭文件是必须要做的,但关闭通道不是必须的。
关闭后的通道有以下特点
- 对一个关闭的通道再发送值就会导致 panic。
- 对一个关闭的通道进行接收会一直获取值直到通道为空。
- 对一个关闭的并且没有值的通道执行接收操作会得到对应类型的零值。
- 关闭一个已经关闭的通道会导致 panic。
无缓冲的通道
无缓冲的通道又称为阻塞的通道,我们来看一下如下代码片段
package main
import "fmt"
func main() {
a := make(chan int)
a <- 10
fmt.Println("发送成功")
}尝试一下
上面这段代码能够通过编译,但是执行时会报错
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [chan send]:
main.main()
C:/Users/W3Cschool/Desktop/test/main.go:7 +0x31
exit status 2deadlock表示我们程序中所有的goroutine都被挂起导致程序死锁了,为什么会出现这种情况呢?
这是因为我们创建的是一个无缓冲区的通道,无缓冲的通道只有在有接收方能够接收值的时候才能发送成功,否则会一直处于等待发送的阶段。同理,如果对一个无缓冲通道执行接收操作时,没有任何向通道中发送值的操作那么也会导致接收操作阻塞。
我们可以创建一个goroutine去接收值,例如
package main
import "fmt"
func receive(x chan int) {
ret := <-x
fmt.Println("接收成功", ret)
}
func main() {
a := make(chan int)
go receive(a)
a <- 10
fmt.Println("发送成功")
}尝试一下
以上代码执行结果如下
接收成功 10
发送成功有缓冲区的通道
另外还有一种方法解决上述死锁的问题,那就是使用有缓冲区的通道。我们可以在使用make函数初始化通道时,为其指定缓冲区大小,例如
package main
import "fmt"
func main() {
a := make(chan int,1)
a <- 10
fmt.Println("发送成功")
}尝试一下
以上代码执行结果如下
发送成功
只要通道的容量大于零,那么该通道就属于有缓冲的通道,通道的容量表示通道中最大能存放的元素数量。当通道内已有元素数达到最大容量后,再向通道执行发送操作就会阻塞,除非有从通道执行接收操作。
我们可以使用内置的len函数获取通道的长度,使用cap函数获取通道的容量
判断通道关闭
当向通道中发送完数据时,我们可以通过close函数来关闭通道。当一个通道被关闭后,再往该通道发送值会引发panic。从该通道取值的操作会先取完通道中的值。通道内的值被接收完后再对通道执行接收操作得到的值会一直都是对应元素类型的零值。那我们如何判断一个通道是否被关闭了呢?
value, ok := <-chvalue:表示从通道中所取得的值
ok:若通道已关闭,返回false,否则返回true
以下代码会不断从通道中取值,直到通道被关闭后退出
package main
import "fmt"
func receive(ch chan int) {
for {
v, ok := <-ch
if !ok {
fmt.Println("通道已关闭")
break
}
fmt.Printf("v:%#v ok:%#v\n", v, ok)
}
}
func main() {
ch := make(chan int, 1)
ch <- 1
close(ch)
receive(ch)
}尝试一下
以上代码执行结果如下
v:1 ok:true
通道已关闭for range接收值
通常我们会使用for range循环来从通道中接收值,当通道关闭后,会在通道内所有值被取完之后退出循环,上面的例子我们使用for range会更加简洁
package main
import "fmt"
func receive(ch chan int) {
for i:=range ch{
fmt.Printf("v:%v",i)
}
}
func main() {
ch := make(chan int, 1)
ch <- 1
close(ch)
receive(ch)
}尝试一下
以上代码执行结果如下
v:1单向通道
在某些场景下我们可能会将通道作为参数在多个任务函数间进行传递,通常我们会选择在不同的任务函数中对通道的使用进行限制,比如限制通道在某个函数中只能执行发送或只能执行接收操作
<- chan int // 只接收通道,只能接收不能发送
chan <- int // 只发送通道,只能发送不能接收select多路复用
在某些场景下我们可能需要同时从多个通道接收数据。通道在接收数据时,如果没有数据可以被接收那么当前 goroutine 将会发生阻塞。Go语言内置了select关键字,使用它可以同时响应多个通道的操作,具体格式如下
select {
case <-ch1:
//...
case data := <-ch2:
//...
case ch3 <- 10:
//...
default:
//默认操作
}select语句具有以下特点
- 可处理一个或多个channel的发送/接收操作
- 如果多个case同时满足,select会随机选择一个执行
- 对于没有case的select会一直阻塞,可用于阻塞 main 函数,防止退出
下面这段代码在终端中打印1-10之间的奇数,借助这段代码来看下select的使用方法
package main
import "fmt"
func main() {
ch := make(chan int, 1)//创建一个类型为int,缓冲区大小为1的通道
for i := 1; i <= 10; i++ {
select {
case x := <-ch://第一次循环由于没有值,所以该分支不满足
fmt.Println(x)
case ch <- i://将i发送给通道(由于缓冲区大小为1,缓冲区已满,第二次不会走该分支)
}
}
}尝试一下
以上代码执行结果如下
1
3
5
7
9并发安全和互斥锁
有时候我们的代码中可能会存在多个 goroutine 同时操作一个资源的情况,这种情况下就会发生数据读写错乱的问题,例如下面这段代码
package main
import (
"fmt"
"sync"
)
var (
x int64
wg sync.WaitGroup // 等待组
)
// add 对全局变量x执行5000次加1操作
func add() {
for i := 0; i < 5000; i++ {
x = x + 1
}
wg.Done()
}
func main() {
wg.Add(2)
go add()
go add()
wg.Wait()
fmt.Println(x)
}我们将上述代码执行多次,不出意外会输出许多不同的结果,这是为什么呢?
因为在上述代码中,我们开启了2个goroutine去执行add函数,某个goroutine对全局变量x的修改可能会覆盖掉另外一个goroutine中的操作,所以导致结果与预期不符
互斥锁
互斥锁是一种常用的控制共享资源访问的方法,它能够保证同一时间只有一个 goroutine 可以访问共享资源。Go语言中使用sync包中提供的Mutex类型来实现互斥锁
我们在下面的代码中使用互斥锁限制每次只有一个goroutine能修改全局变量x,从而解决上述问题
package main
import (
"fmt"
"sync"
)
var (
x int64
wg sync.WaitGroup
m sync.Mutex // 互斥锁
)
func add() {
for i := 0; i < 5000; i++ {
m.Lock() // 修改x前加锁
x = x + 1
m.Unlock() // 改完解锁
}
wg.Done()
}
func main() {
wg.Add(2)
go add()
go add()
wg.Wait()
fmt.Println(x)
}将上述代码编译后多次执行,最终结果都会是10000
使用互斥锁能够保证同一时间有且只有一个 goroutine 进入临界区,其他的 goroutine 则在等待锁;当互斥锁释放后,等待的 goroutine 才可以获取锁进入临界区,多个 goroutine 同时等待一个锁时,唤醒的策略是随机的
读写互斥锁
互斥锁是完全互斥的,但是实际上有很多场景是读多写少的,当我们并发的去读取一个资源而不涉及资源修改的时候是没有必要加互斥锁的,这种场景下使用读写锁是更好的一种选择。在Go语言中使用sync包中的RWMutex类型来实现读写互斥锁
读写锁分为两种:读锁和写锁。当一个 goroutine 获取到读锁之后,其他的 goroutine 如果是获取读锁会继续获得锁,如果是获取写锁就会等待;而当一个 goroutine 获取写锁之后,其他的 goroutine 无论是获取读锁还是写锁都会等待
以下为读多写少场景
package main
import (
"fmt"
"sync"
"time"
)
var (
x = 0
wg sync.WaitGroup
// lock sync.Mutex
rwlock sync.RWMutex
)
func read() {
defer wg.Done()
// lock.Lock()
rwlock.RLock()
fmt.Println(x)
time.Sleep(time.Millisecond)
rwlock.RUnlock()
// lock.Unlock()
}
func write() {
defer wg.Done()
rwlock.Lock()
// lock.Lock()
x += 1
time.Sleep(time.Millisecond * 5)
rwlock.Unlock()
// lock.Unlock()
}
func main() {
start := time.Now()
for i := 0; i < 10; i++ {
go write()
wg.Add(1)
}
time.Sleep(time.Second)
for i := 0; i < 1000; i++ {
go read()
wg.Add(1)
}
wg.Wait()
fmt.Println(time.Since(start))
}w3cschool-Go 教程的更多相关文章
- JavaScript 实例 | w3cschool菜鸟教程
JavaScript 实例 | w3cschool菜鸟教程 http://www.w3cschool.cc/js/js-examples.html
- w3cschool菜鸟教程离线版chm手册正式发布
w3cschool菜鸟教程是一个提供了最全的的web技术基础教程网站.网站包含了HTML教程.CSS教程.Javascript教程.PHP教程等各种建站基础教程.同时也提供了大量的在线实例,通过实例, ...
- w3cschool在线教程
做网页开发的,没有不知道w3cschool的,如果你还不知道,那么就应该早点看下面推荐的文章,菜鸟可以帮你提升你的技能,老鸟可以温故而知新. 第一个是:http://www.w3school.com. ...
- W3Cschool菜鸟教程离线版下载链接
请在电脑上打开以下链接进行下载w3cschool 离线版(chm):http://pan.baidu.com/s/1bniwRCV(最新,2014年10月21日更新)w3cschool 离线版(htm ...
- HTML5 Canvas | w3cschool菜鸟教程
HTML5 Canvas <canvas> 标签定义图形,比如图表和其他图像,您必须使用脚本来绘制图形.. 在画布上(Canvas)画一个红色矩形,梯度矩形,彩色矩形,和一些彩色的文字. ...
- [置顶] IOS 基础入门教程
IOS 基础入门教程 教程列表: IOS 简介 IOS环境搭建 Objective C 基础知识 创建第一款iPhone应用程序 IOS操作(action)和输出口(Outlet) iOS - 委托( ...
- UML 教程
UML 教程 关键词:部署图, 组件图, 包图, 类图, 复合结构图, 对象图, 活动图, 状态机图, 用例图, 通信图, 交互概述图, 时序图, 时间图 简介 部署图 组件图 包图 类图 复合结构图 ...
- 【微信小程序】:客服消息教程
1.本教程完全链接W3Cschool的教程,已经讲的非常清晰和透彻. 2.链接:https://www.w3cschool.cn/weixinapp/weixinapp-api-custommsg-c ...
- 在w3cschool学完html,css,javascript,jquery以后,还是不会做前端怎么办?
w3cschool是一个非盈利性的在线技术学习网站,提供按W3C标准编写的基础教程.完整的看完w3cschool上面的手册,可以基本掌握编程语法.基础性的东西通常都会比较零散,因此,在学习一段时间后, ...
- Git 相关工具及教程地址
一.Git GUI 客户端 Git 客户端下载(Windows) TortoiseGit 客户端下载(Windows) Sourcetree 客户端下载(Windows.Mac) Git Extens ...
随机推荐
- C++之OpenCV入门到提高004:Mat 对象的使用
一.介绍 今天是这个系列<C++之 Opencv 入门到提高>得第四篇文章.这篇文章很简单,介绍如何使用 Mat 对象来实例化图像实例,了解它的构造函数和常用的方法,这是基础,为以后的学习 ...
- [昌哥IT课堂]|ubuntu18.04手动安装mysql8.0.33 deb包
前期准备 1.更新aliyun的软件包安装源: 手动更改 用你熟悉的编辑器打开: /etc/apt/sources.list 把源来链接删除或注释: 加入以下命令: ubuntu 18.04 LTS ...
- JVM源码分析-Java运行
最近在看Java并发编程实践和Inside JVM两本书,发现如果不真正的了解底层运作,那么永远是雾里看花.因此从http://openjdk.java.net/groups/hotspot/上下载了 ...
- 话说ReferenceQueue
也是几年前写的,在内部邮件列表里发过,在这里保存一下. 看到了这篇帖子: <WeakHashMap的神话>http://www.javaeye.com/topic/587995 因为Jav ...
- python常用模块汇总
os模块 os.remove() 删除文件 os.unlink() 删除文件 os.rename() 重命名文件 os.listdir() 列出指定目录下所有文件 os.chdir() 改变当前工作目 ...
- 从零开始学java(第一天)
上班日学习时间很短,而且很多事情会耽搁,就会写的比较少 近几期的笔记以复习为主,后面会逐渐拓展对我个人来说的新知识 1. 复习了一下typore的语法,方便以后记笔记用 # MarkDown学习(# ...
- Jetpack Compose学习(14)——ConstraintLayout约束布局使用
原文地址: Jetpack Compose学习(14)--ConstraintLayout约束布局使用-Stars-One的杂货小窝 本文阅读之前,需要了解ConstraintLayout的使用! 各 ...
- pyc文件花指令
pyc花指令 常见的python花指令形式有两种:单重叠指令和多重叠指令. 以下以python3.8为例,指令长度为2字节. 单重叠指令: 例如pyc经过反编译后得到的东西为 0 JUMP_ABSOL ...
- 痞子衡嵌入式:i.MXRT1170上PXP对CM7 TCM进行随机地址短小数据写入操作限制
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家分享的是i.MXRT1170上PXP对CM7 TCM进行随机地址短小数据写入操作限制. 在 MCU 里能够对片内外映射的存储器进行读写操作的主设 ...
- GraphQL Part I: hello, world.
GraphQL with ASP.NET Core (Part- I : Hello World) 厌倦了 REST? 让我们谈一下 GraphQL, GraphQL 提供声明式的方式从服务器获取数据 ...