第一章 Java集合框架
-----------------------------------------------------------------------------
Java集合框架(一)-ArrayList
大佬理解->Java集合之LinkedList
1、ArrayList的特点
| 存放的元素有序 |
|---|
| 元素不唯一(可以重复) |
| 随机访问快 |
| 插入删除元素慢 |
| 非线程安全 |
2、底层实现
底层初始化,使用一个Object类型的空对象数组,初始长度为0;
源码
//Object类型对象数组引用
transient Object[] elementData;
//默认空的Object数组
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
//实例化时,将Object类型对象数组引用 指向 默认空的Object数组
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
首次添加元素,自动进行扩容,默认扩充容量是10(数组的长度,也就是集合存放元素的个数);
源码
//如果是第一次添加元素
public boolean add(E e) {
//private int size; //size = 0;
//调用ensureCapacityInternal(int minCapacity)方法
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
//minCapacity = 1;
private void ensureCapacityInternal(int minCapacity) {
//调用calculateCapacity(Object[] elementData, int minCapacity)方法
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
private static int calculateCapacity(Object[] elementData, int minCapacity) {
//判断是不是默认空的Object数组
//如果是进入选择一个数组容量
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
//private static final int DEFAULT_CAPACITY = 10;
//minCapacity = 1;
//所以第一次添加元素时,自动进行扩容,默认扩充容量是10
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
3、扩容
- 当前一次扩容的数组容量不足时(放满10个元素,再想添加一个元素,容量不足),开始进行动态扩容;
- 每次扩容,是之前一次扩容后的数组容量的1.5倍(即:每次都在前一次数组容量的基础上,增加一半-右移1位);
- 最大容量Integer.MAX_VALUE - 8,即2^31-8;
//扩容方法
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length; //旧数组的容量
int newCapacity = oldCapacity + (oldCapacity >> 1); //新数组的容量 = 老数组的容量+老数组的一半(右移一位)
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0) //如果新数组的容量大于最大值,将数组的容量设置为Integer.MAX_VALUE - 8
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
//private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
4、ArrayList初始化
基于多态创建ArrayList集合对象
List<Object> list = new ArrayList<>(); // 推荐
Collection collection = new ArrayList();
ArrayList arrayList = new ArrayList();
List<Integer> intList = new ArrayList<>(); //可以使用泛型,指定存放数据的类型
5、常用方法
| 方法 | 说明 |
|---|---|
| add(Object obj) | 添加元素 |
| add(int index, E element) | 指定下标添加元素 |
| remove(int index) | 移除指定 下标 |
| remove(Object o) | 移除指定 元素 |
| get(int index)) | 获取元素 |
| size() | 集合元素个数 |
| contains(Object o) | 是否包含某元素 |
| isEmpty() | 集合是否为空 |
5.1 add(Object obj)
//添加元素方法:add(Object obj),每次添加元素都是自动添加到数组的末尾,元素下标值从0开始,跟数组一致;
//可以添加重复值;
//可以添加null值;
5.2 add(int index, E element)
//指定下标添加元素和删除元素,执行效率比较低;
5.3 remove(int index)
// 先检查该索引是否合法,不合法会抛出索引越界异常;
//再把要删除的元素拿出来作为返回值,期间会计算要删除的元素后面还有多少个元素,再调用System.arraycopy(elementData, index+1, elementData, index, numMoved);移动数组元素,这个方法是一个本地方法,将一个数组从指定位置复制到另外一个数组的指定位置。
//然后让最后一个元素变成null,将数组大小减一,不置为null会存在引用,无法被GC回收,造成内存泄漏。
源码分析
//删除指定索引位置元素
public E remove(int index) {
//检查该索引是否合法
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
//将一个数组从指定位置复制到另外一个数组的指定位置
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
//让最后一个元素变成null
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
5.4 remove(Object o)
//删除指定元素和上一个方法类似,主要是这个需要先找到指定元素的索引位置,找不到直接返回false,找到再调用内部的删除方法fastRemove(int index)来删除;
源码分析
//删除指定元素
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
//内部的删除方法
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
}
注意:使用remove(Object o)移除元素的时候,如果存在多个元素值一样,只会移除一个;
特殊案例1,使用for循环遍历删除元素:
@Test
public void testRemoveObject(){
List nums = new ArrayList();
nums.add(1);
nums.add(1);
nums.add(1);
for (int i = 0; i < nums.size(); i++) {
if(nums.get(i).equals(1)){
nums.remove(i);
System.out.println("删除第"+i+"个1");
//第一个1被删除
//第二个1,由于第一个1删除后,往前移动了,所以第二次遍历的是第三个1
}
}
System.out.println("删除后的集合:"+nums);
/*
删除第0个1
删除第1个1
删除后的集合:[1] 删除还有遗漏
*/
}
特殊案例2使用 遍历删除元素:
@Test
public void testRemoveObject2(){
List nums = new ArrayList();
nums.add(1);
nums.add(1);
nums.add(1);
Iterator iterator = nums.iterator();
int i = 0;
while (iterator.hasNext()){
if(iterator.next().equals(new Integer(1))){
iterator.remove();
System.out.println("删除第"+i+"个1"); i++;
}
}
System.out.println("删除后的集合:"+nums);
/*
删除第0个1
删除第1个1
删除第2个1
删除后的集合:[] 删除成功
*/
}
5.5get(int index))
// 获取元素方法:get(下标值),只能通过下标取值;
//当访问下标值超出了集合元素的最大下标值,报下标越界异常:java.lang.IndexOutOfBoundsException
// 可用的下标值的范围:最小值是0,最大值是集合元素的个数 - 1
5.6 size()
// 获取集合中元素个数方法:size();
5.7 contains(Object o)
// 判断list集合中,是否包含某个元素方法:contains(查找元素值),返回true,代表存在,返回false,代表不存在;
5.8 isEmpty()
// 判断list集合是否为空方法:isEmpty(),返回true代表没有元素,空的,返回false,代表有元素,不是空的
// 底层就是通过集合中元素个数size == 0 判断,所以也可以使用size() == 0判断集合非空
源码
public boolean isEmpty() {
return size == 0;
}
5.9 clear()
//清空list集合方法:clear(),清除集合中的所有元素
源码
ublic void clear() {
modCount++;
// clear to let GC do its work
for (int i = 0; i < size; i++) //一次将数组赋值为null;
elementData[i] = null;
size = 0; //设置数组长度为0;
}
5.10 toArray()
// list集合一步转换为数组方法:toArray(),返回的是Object类型数组
6、数组转换成集合
Arrays.asList(目标数组)
String[] strArrays = {"奥迪", "奔驰", "宝马"};
List<String> strList1 = Arrays.asList(strArrays);
System.out.println(strList1); //[奥迪, 奔驰, 宝马]
7、遍历
List<String> strList = new ArrayList<>();
strList.add("Audi");
strList.add("Benz");
strList.add("Bmw");
strList.add("Audi");
//for循环
for (int i = 0; i < strList.size(); i++) {
System.out.println("汽车品牌:" + strList.get(i));
}
//迭代器
//Iterator迭代器,只能通过集合获取,不可以重复使用,迭代结束,迭代器就失效,如果想再次使用,需要重新获取
Iterator<String> iterator = strList.iterator();
// 迭代器遍历,使用while,不知道其中元素个数
while(iterator.hasNext()){
System.out.println("汽车品牌:" + iterator.next());
}
运行结果:
汽车品牌:Audi
汽车品牌:Benz
汽车品牌:Bmw
汽车品牌:Audi
8、Vector(线程安全)
- Vector,底层数据结构是和ArrayList一致的,都是对象数组,但是它的操作是线程安全的,每个方法都带有synchronized同步;
- 默认初始容量是10,可以自定义,但是不能小于0,默认每次扩容是前一次容量的一倍,扩容的数量也是可以指定的,如果指定,每次都是在前一次基础上扩容指定的数量
-----------------------------------------------------------------------------------------------
1、LinkedList的特点
| 存放的元素有序 |
|---|
| 元素不唯一(可以重复) |
| 随机访问慢 |
| 插入删除元素快 |
| 非线程安全 |
2、底层实现
底层实现是链表结构(双向链表),插入和删除元素的效率高(遍历元素和随机访问元素的效率低);
底层使用Node双向链表实现的
private static class Node<E> {
E item; //元素值
Node<E> next; //下一个元素引用
Node<E> prev; //上一个元素引用
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
3、LinkedList初始化
// LinkedList包含首尾操作的特有方法,在list接口中没有定义,不推荐多态创建集合对象
// List<String> strList = new LinkedList<>();
// strList.addFirst();
LinkedList<String> linkedList = new LinkedList<>();
4、常用方法
| 方法 | 说明 |
|---|---|
| add(E e) | 添加元素(元素添加在链表末尾) |
| addFirst(E e) | 在链表首添加元素 |
| addLast(E e) | 在链表末尾添加元素 |
| getFirst() | 获取第一个元素 |
| getLast() | 获取最后一个元素 |
| removeFirst() | 移除第一个元素 |
| removeLast() | 移除最后一个元素 |
| size() | 获取元素的总数 |
| get(int index) | 根据元素下标获取元素值 |
4.1 add(E e)
添加元素的普通方法:add(元素),将元素自动添加到链表的末尾
4.2 addFirst(E e)
addFirst(E e)添加到链表首部
4.3 addLast(E e)
addLast(E e)添加到链表首部
4.4 getFirst()
getFirst() 获取第一个元素
4.5 getLast()
getLast() 获取最后一个元素
4.7 removeFirst()
removeFirst() 删除第一个元素
4.8 removeLast()
removeLast() 删除最后一个元素
4.9 size()
size() 获取集合中元素个数方法
4.10 get(int index)
1)获取的下标值必须是在有效的范围内:从0到元素个数-1之间,否则报错:IndexOutOfBoundsException;
2)如果下标值在可以有效的范围内,自动进行二分法移动指针,先判断目标下标值在元素个数一半的前半段还是后半段;
如果在前半段,自动从第一个节点开始,依次向后移动指针,直到找到下标位置,返回对应元素;
如果在后半段,自动从最后一个节点,依次向前移动指针,直到找到指定下标位置,返回对应元素;
所以:当下标位置越接近元素个数一半值(越靠近中间位置),效率是最低的,可以看出:遍历和随机访问的效率低;
源码
public E get(int index) {
checkElementIndex(index); //判断下标是否大于集合元素总数
return node(index).item; //返回结点值(元素)
}
//一个一个的往后找到指定的节点并返回
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
5、ArrayList 和 LinkedList的区别
相同点
都是list的实现类,存放的元素都是有序,不唯一的,都是线程不安全的
不同点
1)底层实现不同:ArrayList底层实现是Object对象数组,而LinkedList底层是双向链表结构;
2)扩容机制不同:ArrayList默认是空的Object对象数组(也可以指定大于0的初识容量),首次自动扩容为10个长度,后续每次扩容原来容量的1.5倍,LinkedList底层是链表,没有容量,没有扩容,存放元素没限制;
3)使用场景不同:ArrayList适用于快速的遍历和随机访问元素,而LinkedList适用于快速的添加删除元素;
-----------------------------------------------------------------------------------------------
1、HashSet特点
| 存放的元素是无序的(不保证添加元素的顺序) |
|---|
| 元素唯一(不可以重复) |
| 可以存null,但是只能存放1个 |
| 虽然set集合不保证添加元素的顺序,但是集合中存放的元素顺序其实是固定的,根据元素的hash值确定的顺序 |
2、HashSet原理分析
HashSet底层,是借助HashMap实现的;
3、HashSet初始化
Set<String> strSet = new HashSet<>();
4、HashSet常用方法
| 方法 | 说明 |
|---|---|
| size() | 结合元素个数 |
| contains(Object o) | 集合是否包含某个元素 |
4.1 size()
// 获取set集合元素个数方法:size()
4.2 contains(Object o)
// 判断set集合中是否包含某个元素方法:contains(元素)
4.3 list的其它常用方法,set中也有,不再介绍
5、HashSet遍历
5.1 迭代器遍历
Set<String> carSet = new HashSet<>();
carSet.add("Bmw325");
carSet.add("BenzC200");
carSet.add("AudiA4");
// 方式一:迭代器遍历
Iterator<String> iterator = carSet.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
5.2 增强for循环
// 方式二:增强for循环
for (String car : carSet) {
System.out.println(car);
}
运行结果:
BenzC200
AudiA4
Bmw325
6、HashSet集合是如何确定元素唯一的
6.1 HashSet添加一个元素的过程
调用对象的hashCode()方法获取对象的哈希值;
根据对象的哈希值计算对象的存储位置;
判断该位置是否有元素,如果没有元素则将元素存储到该位置;如果有元素则遍历该位置的所有元素,和新存入的元素比较哈希值是否相同,如果都不相同则将元素存储到该位置;如果有相同的,则调用equals()方法比较对象内容是否相等;
如果返回false则将元素存储到该位置,如果返回true则说明元素重复,不存储;
6.2 流程图
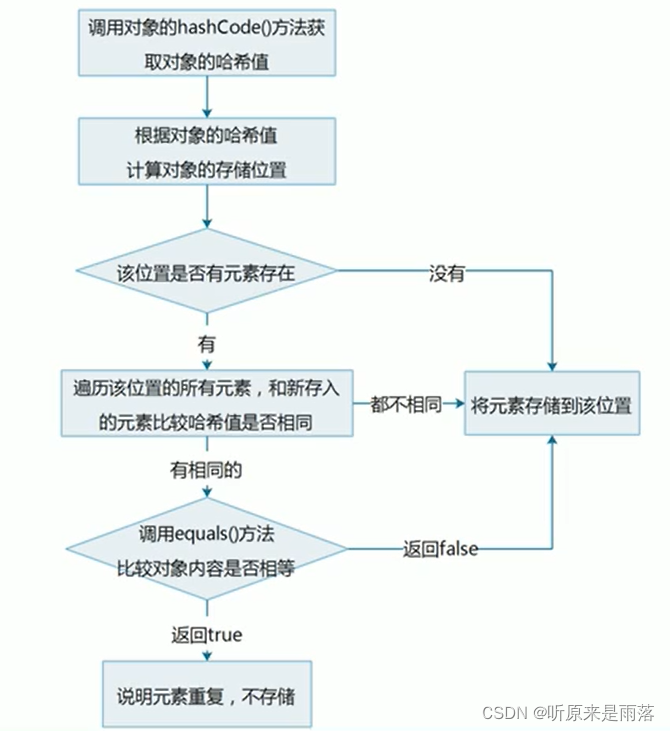
HashSet集合存储元素:要保证元素唯一性,需要重写hashCode()和equals()方法。
-----------------------------------------------------------------------------------------------
1、HashMap特点
| 存放的元素都是键值对(key-value),key是唯一的,value是可以重复的 |
|---|
| 存放的元素也不保证添加的顺序,即是无序的 |
| 存放的元素的键可以为null,但是只能有一个key为null,可以有多个value为null(前提是存放的是HasHap对象) |
| 如果新添加的元素的键(key)在集合中已经存在,自动将新添加的值覆盖到原有的值 |
2、底层实现
HashMap的底层使用的是Node对象数组;
HashMap源码
transient Node<K,V>[] table; //Node对象数组
//Node类
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
......
}
3、扩容
- HashMap的底层使用的是Node对象数组,初始容量(未自定义)是16,根据负载因子跟数组容量,计算出扩容临界值,每当存放元素达到了临界值就可以扩容,而不是等到数组长度不够;
- 每次扩容,都是原有数组容量的2倍,必须要保证是2的整数次幂(底层算法实现),最大容量是2的30次方;
初始容量和默认扩容因子
/**
* Constructs an empty <tt>HashMap</tt> with the default initial capacity
* (16) and the default load factor (0.75).
*/
//初始容量为16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
//默认扩容因子为0.75
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//最大容量是2的30次方
static final int MAXIMUM_CAPACITY = 1 << 30;
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
4、初始化
Map<String,String> carMap = new HashMap<>(); //推荐使用
5、常用方法
| put(key, value) | 添加键值对 |
|---|---|
| get(Object key) | 通过key获取value |
| size() | 获取集合键值对数量 |
| keySet() | 获取所有的键集合(返回值为set集合) |
| values() | 获取所有值集合 |
| containsKey(Object key) | 判断某个键是否存在 |
| containsValue(Object value) | 判断某个值是否存在某个值 |
| remove(Object key) | 根据键值删除键值对 |
| clear() | 清空集合 |
5.1 put(key, value);
添加键值对方法;
可以添加 null 的key 或者value,键只能由一个null,值可以由多个null;
5.2 get(Object key)
获取键值对的方法:get(key),只能根据key获取value,如果key不存在,不会报错,返回null;
5.3 size()
获取集合中存放键值对数量;
5.4 keySet()
获取所有的键集合;
Map<String,String> carMap = new HashMap<>();
carMap.put("Audi","奥迪");
carMap.put("Benz","奔驰");
carMap.put("Bmw","宝马");
Set<String> keySet = carMap.keySet();
System.out.println("获取所有的键集合:"+keySet);//[Benz, Audi, Bmw]
5.5 values()
获取所有值集合方法;
Collection<String> values = carMap.values();
System.out.println(values);//[奔驰, 奥迪, 宝马]
5.6 containsKey(Object key)
判断集合中是否包含某个键值对,存在返回true;
5.7 containsValue(Object value)
判断集合中是否包含某个值,不可以作为键值对的唯一标识,值可重复;
5.8 remove(Object key)
删除键值对方法;
5.9 clear()
清空map集合;
6、遍历
6.1 方式一:迭代器(不可以通过map集合直接获取,因为它只能通过Collection获取)
System.out.println("方式一");
Iterator<String> iterator = carKeySet.iterator();
while (iterator.hasNext()){
//获取key
String carKey = iterator.next();
//根据key 获取值
String carValue = carMap.get(carKey);
System.out.print(carKey + "---" + carValue +" ");
}
6.2 方式二:增强for,原理和上一个类似,也根据键的集合,获取值
System.out.println("\n"+"方式二");
for (String carKey : carMap.keySet()) {
System.out.print(carKey+"---"+carMap.get(carKey)+" ");
}
6.3 方式三:增强for,操作的是Map.Entry对象,推荐写法,效率较高
System.out.println("\n"+"方式三");
for (Map.Entry<String,String> entry : carMap.entrySet()){
System.out.print(entry.getKey()+"---"+entry.getValue()+" ");
}
运行结果
Benz---奔驰 Audi---奥迪 Bmw---宝马
7、TreeMap
自带排序功能的集合map,TreeMap,自动按照key的字典序排序;
System.out.println("自带排序功能的集合map,TreeMap,自动按照key的字典序排序");
Map<String,String> paramsMap = new TreeMap<>();
paramsMap.put("body","TreeMap");
paramsMap.put("userId","U0001");
paramsMap.put("sign","sign");
paramsMap.put("appId","KH96");
System.out.println(paramsMap);
自带排序功能的集合map,TreeMap,自动按照key的字典序排序
{appId=KH96, body=TreeMap, sign=sign, userId=U0001}
8、HashTable
Hashtable,是map集合的实现类,但是跟HashMap的去表是,线程安全的;
Hashtable的put方法源码
//put方法是同步安全的
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
默认初始容量是11,扩容因子也是0.75;
Hashtable初始化源码
/**
* Constructs a new, empty hashtable with a default initial capacity (11)
* and load factor (0.75).
*/
//默认初始容量是11
//扩容因子也是0.75
public Hashtable() {
this(11, 0.75f);
}
每次扩容是之前容量的2倍+1;
Hashtable扩容源码
protected void rehash() {
int oldCapacity = table.length;
Entry<?,?>[] oldMap = table;
// 新数组的容量=旧数组长度*2+1
int newCapacity = (oldCapacity << 1) + 1;
// 保证新数组的大小永远小于等于MAX_ARRAY_SIZE
// MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8
if (newCapacity - MAX_ARRAY_SIZE > 0) {
if (oldCapacity == MAX_ARRAY_SIZE)
return;
newCapacity = MAX_ARRAY_SIZE;
}
// 创建新数组
Entry<?,?>[] newMap = new Entry<?,?>[newCapacity];
modCount++;
// 计算新的临界值
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
table = newMap;
// 将旧数组中的元素迁移到新数组中
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next;
//计算新数组下标
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
// 头插法的方式迁移旧数组的元素
e.next = (Entry<K,V>)newMap[index];
newMap[index] = e;
}
}
}-----------------------------------------------------------------------------------------------
1、Collections
| sort(List list) | 自然升序排序 |
|---|---|
| reverse(List<?> list) | 集合反转 |
| binarySearch(List<? extends Comparable<? super T>> list, T key) | 二分查找(要求集合有序) |
| addAll(Collection<? extends E> c) | 从集合中添加批量元素 |
| max(Collection<? extends T> coll) | 集合最大元素 |
| min(Collection<? extends T> coll) | 集合最小元素 |
1.1 sort(List list)
自然升序;
1.2 reverse(List<?> list)
集合反转;
1.3 binarySearch(List<? extends Comparable<? super T>> list, T key)
二分查找(要求集合有序);
1.4 addAll(Collection<? extends E> c)
从集合中添加批量元素;
1.5 max(Collection<? extends T> coll)
集合中最大元素;
1.6 min(Collection<? extends T> coll)
集合中最小元素;
1.7 同步控制
Collections工具类中提供了多个synchronizedXxx方法,该方法返回指定集合对象对应的同步对象,从而解决多线程并发访问集合时线程的安全问题。HashSet、ArrayList、HashMap都是线程不安全的,如果需要考虑同步,则使用这些方法。这些方法主要有:synchronizedSet、synchronizedSortedSet、synchronizedList、synchronizedMap、synchronizedSortedMap。
2、泛型
泛型就相当于是类型模板,指定什么样的类型,对应的值就是什么类型,通常泛型给你参数T,E,K,V等,推荐使用T(Type);
自定义泛型举例
Studnet类
public class Student<T1,T2,T3>{
private T1 name;
private T2 age;
private T3 sex;
public Student() {
}
public Student(T1 name, T2 age, T3 sex) {
this.name = name;
this.age = age;
this.sex = sex;
}
//省略get,set方法
@Override
public String toString() {
return "Student{" +
"name=" + name +
", age=" + age +
", sex=" + sex +
'}';
}
}
测试
public class TestStudnet {
public static void main(String[] args) {
//在实例化的时候可以对类型进行约束
Student<String, Integer, Character> student = new Student<>();
student.setName("二狗");
student.setAge(18);
student.setSex('男');
System.out.println(student);
}
}
运行结果
Student{name=二狗, age=18, sex=男}-----------------------------------------------------------------------------------------------
第一章 Java集合框架的更多相关文章
- 22章、Java集合框架习题
1.描述Java集合框架.列出接口.便利抽象类和具体类. Java集合框架支持2种容器:(1) 集合(Collection),存储元素集合 (2)图(Map),存储键值对.
- 浅入深出之Java集合框架(中)
Java中的集合框架(中) 由于Java中的集合框架的内容比较多,在这里分为三个部分介绍Java的集合框架,内容是从浅到深,如果已经有java基础的小伙伴可以直接跳到<浅入深出之Java集合框架 ...
- Java集合框架概述和集合的遍历
第三阶段 JAVA常见对象的学习 集合框架概述和集合的遍历 (一) 集合框架的概述 (1) 集合的由来 如果一个程序只包含固定数量的且其生命周期都是已知的对象,那么这是一个非常简单的程序. 通常,程序 ...
- Java 集合框架
Java集合框架大致可以分为五个部分:List列表,Set集合.Map映射.迭代器.工具类 List 接口通常表示一个列表(数组.队列.链表 栈),其中的元素 可以重复 的是:ArrayList 和L ...
- (转)Java集合框架:HashMap
来源:朱小厮 链接:http://blog.csdn.net/u013256816/article/details/50912762 Java集合框架概述 Java集合框架无论是在工作.学习.面试中都 ...
- Java集合框架
集合框架体系如图所示 Java 集合框架提供了一套性能优良,使用方便的接口和类,java集合框架位于java.util包中, 所以当使用集合框架的时候需要进行导包. Map接口的常用方法 Map接口提 ...
- 【JAVA集合框架之Map】
一.概述.1.Map是一种接口,在JAVA集合框架中是以一种非常重要的集合.2.Map一次添加一对元素,所以又称为“双列集合”(Collection一次添加一个元素,所以又称为“单列集合”)3.Map ...
- 【JAVA集合框架之List】
一.List接口概述. List有个很大的特点就是可以操作角标. 下面开始介绍List接口中相对于Collection接口比较特别的方法.在Collection接口中已经介绍的方法此处就不再赘述. 1 ...
- Java集合框架:HashMap
转载: Java集合框架:HashMap Java集合框架概述 Java集合框架无论是在工作.学习.面试中都会经常涉及到,相信各位也并不陌生,其强大也不用多说,博主最近翻阅java集合框架的源码以 ...
- java集合框架1
1.综述 所有集合类都位于java.util包下.集合中只能保存对象(保存对象的引用变量).(数组既可以保存基本类型的数据也可以保存对象). 当我们把一个对象放入集合中后,系统会把所有集合元素都当成O ...
随机推荐
- CSP-S 2024 简单题
CSP-S 2024 简单题 以下均为考场做法. T1 决斗 (duel) 考虑贪心,按照攻击力 \(a_i\) 排序,从小到大使用所有怪物进行攻击,每只怪物攻击一个在场且能击杀的怪物中,攻击力最大的 ...
- 低功耗4G模组HTTP网络协议应用
大家好,今天我们来学习合宙Air780E模组LuatOS开发4G通信中HTTP网络协议的应用,实现模组和服务器之间数据的传输. 一.HTTP概述 1.1 简介 HTTP是HyperTextTran ...
- Sublime装sftp远程编辑插件
我平时很喜欢用Sublime来编辑一些脚本软件,本次需要远程编辑Linux上的脚本,需要安装一些插件来完成. Ctrl+Shift+P呼叫出命令行面板后输入 install选择 Install Pac ...
- AtCoder Beginner Contest 380 (A~E)题解
A - 123233 遍历字符串统计出现次数即可. #include<bits/stdc++.h> using namespace std; #define int long long c ...
- Thinkphp漏洞复现
Thinkphp漏洞复现 环境均为vulhub/thinkphp Thinkphp是一种开源框架.是一个由国人开发的支持windows/Unix/Linux等服务器环境的轻量级PHP开发框架. 很多c ...
- 在 ASP.NET Core 中创建 gRPC 客户端和服务器
前言 gRPC 是一种高性能.开源的远程过程调用(RPC)框架,它基于 Protocol Buffers(protobuf)定义服务,并使用 HTTP/2 协议进行通信. 新建项目 新建解决方案Grp ...
- C#-JavaScript-base64加密解码
C# //base64加密 //调用方式:Helper.EncodeToBase64(需要加密字符串) public static string EncodeToBase64(string data) ...
- golang之Time时间函数
在编程中,我们经常会遭遇八小时时间差问题.这是由时区差异引起的,为了能更好地解决它们,我们需要理解几个时间定义标准. GMT(Greenwich Mean Time),格林威治平时.GMT 根据地球的 ...
- Mac下常用软件汇总(精)
1.连接Windows远程连接工具(Microsoft-Remote-Desktop-For-Mac ) 2.SSH管理工具:Royal TSX 下载地址:Royal Apps Royal TSX 是 ...
- uView的DatetimePicker组件在confirm回调中取不到v-model的最新值
前情 uni-app是我比较喜欢的跨平台框架,它能开发小程序/H5/APP(安卓/iOS),重要的是对前端开发友好,自带的IDE让开发体验非常棒,公司项目就是主推uni-app,在uniapp生态中u ...