Python 爬虫-Scrapy爬虫框架
2017-07-29 17:50:29
Scrapy是一个快速功能强大的网络爬虫框架。
Scrapy不是一个函数功能库,而是一个爬虫框架。爬虫框架是实现爬虫功能的一个软件结构和功能组件集合。爬虫框架是一个半成品,能够帮助用户实现专业网络爬虫。
一、Scrapy框架介绍
- 5+2结构,5个主要模块加2个中间件。
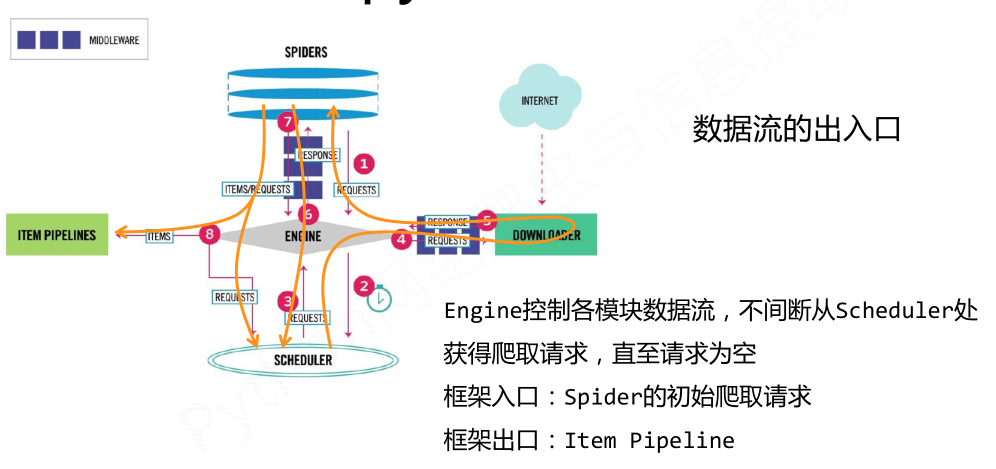
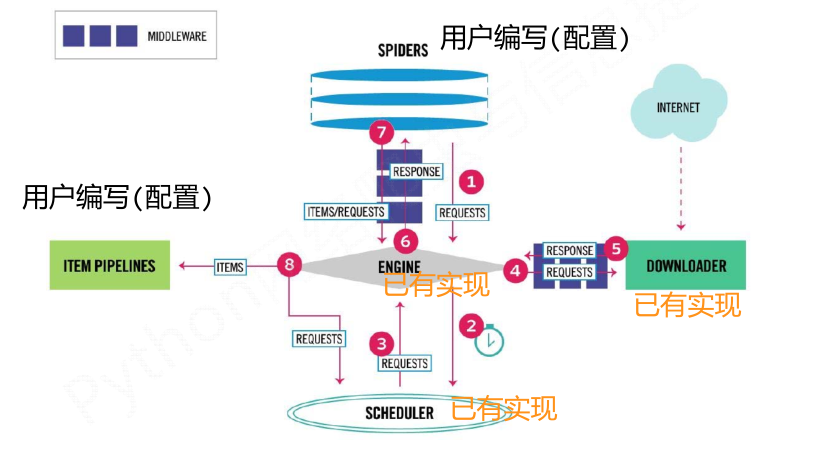
(1)Engine:控制所有模块之间的数据流;根据条件触发事件。不需要用户修改
(2)Downloader:根据请求下载网页。不需要用户修改
(3)Scheduler:对所有爬取请求进行调度管理。不需要用户修改
(4)Downloader Middleware:实施Engine、Scheduler和Downloader之间进行用户可配置的控制,进行修改、丢弃、新增请求或响应。用户可以编写配置代码
(5)Spider:解析Downloader返回的响应(Response);产生爬取项(scraped item);产生额外的爬取请求(Request)。需要用户编写配置代码
(6)Item Pipelines:以流水线方式处理Spider产生的爬取项;由一组操作顺序组成,类似流水线,每个操作是一个Item Pipeline类型;可能操作包括:清理、检验和查重爬取项中的HTML数据、将数据存储到数据库。需要用户编写配置代码
(7)Spider Middleware:对请求和爬取项的再处理,进行修改、丢弃、新增请求或爬取项。用户可以编写配置代码

- 流程介绍
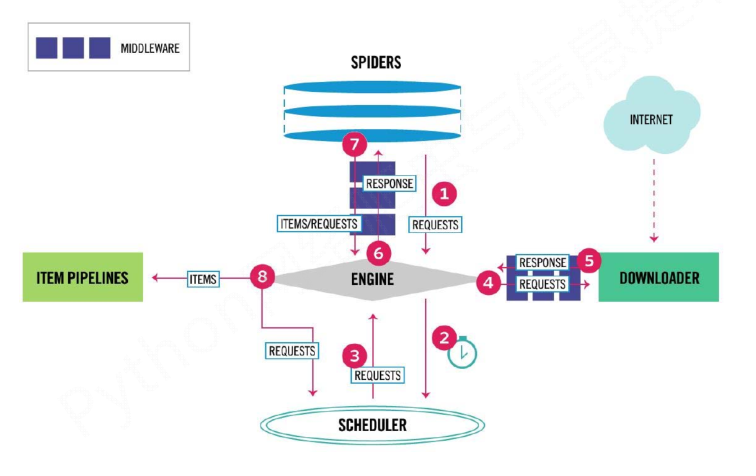
数据流的三个路径--1:
1 Engine从Spider处获得爬取请求(Request)
2 Engine将爬取请求转发给Scheduler,用于调度
数据流的三个路径--2:
3 Engine从Scheduler处获得下一个要爬取的请求
4 Engine将爬取请求通过中间件发送给Downloader
5 爬取网页后,Downloader形成响应(Response,通过中间件发给Engine
6 Engine将收到的响应通过中间件发送给Spider处理
数据流的三个路径--3:
7 Spider处理响应后产生爬取项(scraped Item和新的爬取请求(Requests)给Engine
8 Engine将爬取项发送给Item Pipeline(框架出口)
9 Engine将爬取请求发送给Scheduler
- 数据流的出入口以及用户需要配置的部分
二、Scrapy库 和 Requests库的比较
相同点:
- 两者都可以进行页面请求和爬取,Python爬虫的两个重要技术路线
- 两者可用性都好,文档丰富,入门简单
- 两者都没有处理js、提交表单、应对验证码等功能(可扩展)
区别:
- 非常小的需求,requests库
- 不太小的需求,Scrapy框架,能够持续的爬取信息,并积累成自己的爬取库
- 定制程度很高的需求(不考虑规模),自搭框架,requests > Scrapy

Python 爬虫-Scrapy爬虫框架的更多相关文章
- dota玩家与英雄契合度的计算器,python语言scrapy爬虫的使用
首发:个人博客,更新&纠错&回复 演示地址在这里,代码在这里. 一个dota玩家与英雄契合度的计算器(查看效果),包括两部分代码: 1.python的scrapy爬虫,总体思路是pag ...
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- Python之Scrapy爬虫框架 入门实例(一)
一.开发环境 1.安装 scrapy 2.安装 python2.7 3.安装编辑器 PyCharm 二.创建scrapy项目pachong 1.在命令行输入命令:scrapy startproject ...
- [Python爬虫] scrapy爬虫系列 <一>.安装及入门介绍
前面介绍了很多Selenium基于自动测试的Python爬虫程序,主要利用它的xpath语句,通过分析网页DOM树结构进行爬取内容,同时可以结合Phantomjs模拟浏览器进行鼠标或键盘操作.但是,更 ...
- windows下使用python的scrapy爬虫框架,爬取个人博客文章内容信息
scrapy作为流行的python爬虫框架,简单易用,这里简单介绍如何使用该爬虫框架爬取个人博客信息.关于python的安装和scrapy的安装配置请读者自行查阅相关资料,或者也可以关注我后续的内容. ...
- 【python】Scrapy爬虫框架入门
说明: 本文主要学习Scrapy框架入门,介绍如何使用Scrapy框架爬取页面信息. 项目案例:爬取腾讯招聘页面 https://hr.tencent.com/position.php?&st ...
- Python使用Scrapy爬虫框架全站爬取图片并保存本地(妹子图)
大家可以在Github上clone全部源码. Github:https://github.com/williamzxl/Scrapy_CrawlMeiziTu Scrapy官方文档:http://sc ...
- 11.Python使用Scrapy爬虫小Demo(新手入门)
1.前提:已安装好scrapy,且已新建好项目,编写小Demo去获取美剧天堂的电影标题名 2.在项目中创建一个python文件 3.代码如下所示: import scrapy class movies ...
- Python爬虫Scrapy框架入门(0)
想学习爬虫,又想了解python语言,有个python高手推荐我看看scrapy. scrapy是一个python爬虫框架,据说很灵活,网上介绍该框架的信息很多,此处不再赘述.专心记录我自己遇到的问题 ...
随机推荐
- vue性能优化2--引入cdn
当我们加载页面时,需要将我们所需要的一些依赖加载到当前会话中然后再开始执行,如果我们首屏,模块比较多是,需要等待的时间会比较长,而且.浏览器内存最多执行四十个进程,需要等到加载完前面的才能执行后面的代 ...
- UVM中的regmodel建模(三)
总结一下UVM中的寄存器访问实现: 后门访问通过add_hdl_path命令来添加寄存器路径,并扩展uvm_reg_backdoor基类,定义read与write函数,最后在uvm_reg_block ...
- EntityFramework包含作用
System.Data.Entity.Infrastructure.DbQuery的引用需要加入上面那个包
- ActiveMQ 安装以及集群搭建
安装环境: jdk1.7 apache-activemq-5.11.1-bin.tar.gz VM虚拟机redhat6.5-x64:192.168.1.200 Xshell4 部署方案: 主机IP 集 ...
- 应用程序无法正常启动0xc000007b怎么解决
解决方法两种: 1. 网上搜索中最常见的,缺少DirectX 9 ,去下载一个安上就OK了. 2.第二种情况比较操蛋,其实报的错误应该是:mfc100u.dll丢失 .我在两台电脑上装了相同系统后,台 ...
- 设置(更改)Mysql 自增ID的起始值
SELECT * FROM segwords WHERE id>790511 DELETE FROM segwords WHERE id>790511 #下面这句是设置的 ALTER TA ...
- C/C++之内存对齐
数据对齐,是指数据所在的内存地址必须是该数据长度的整数倍.DWORD数据的内存起始地址能被4除尽,WORD数据的内存起始地址能被2除尽.X86 CPU能直接访问对齐的数据,当它试图访问一个未对齐的数据 ...
- sql server deadlock跟踪的四种方法
最近写程序常会遇到deadlock victim,每次一脸懵逼.研究了下怎么跟踪,写下来记录下. 建测试数据 CREATE DATABASE testdb; GO USE testdb; CREATE ...
- 教你如何用Nginx搭建一个安全的、快速的微服务架构
今天我们要谈论微服务以及如何使用Nginx构建一个快速的.安全的网络系统.最后,我们将向您展示一个使用Fabric模式如何非常快速和轻松地构建一个微服务的demo. 在我们探讨Fabric模式之前,我 ...
- Python3.x与Python2.x的差异用法
Python3.x与Python2.x的差异用法 1,关于urllib2区别: # python2 import urllib2 # python3 # 用urllib.request代替urllib ...