Spark与mysql整合
一、需求:把最终结果存储在mysql中
1、UrlGroupCount1类
import java.net.URL
import java.sql.DriverManager import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext} /**
* 把最终结果存储在mysql中
*/
object UrlGroupCount1 {
def main(args: Array[String]): Unit = {
//1.创建spark程序入口
val conf: SparkConf = new SparkConf().setAppName("UrlGroupCount1").setMaster("local[2]")
val sc: SparkContext = new SparkContext(conf) //2.加载数据
val rdd1: RDD[String] = sc.textFile("e:/access.log") //3.将数据切分
val rdd2: RDD[(String, Int)] = rdd1.map(line => {
val s: Array[String] = line.split("\t")
//元组输出
(s(1), 1)
}) //4.累加求和
val rdd3: RDD[(String, Int)] = rdd2.reduceByKey(_+_) //5.取出分组的学院
val rdd4: RDD[(String, Int)] = rdd3.map(x => {
val url = x._1
val host: String = new URL(url).getHost.split("[.]")(0)
//元组输出
(host, x._2)
}) //6.根据学院分组
val rdd5: RDD[(String, List[(String, Int)])] = rdd4.groupBy(_._1).mapValues(it => {
//根据访问量排序 倒序
it.toList.sortBy(_._2).reverse.take(1)
}) //7.把计算结果保存到mysql中
rdd5.foreach(x => {
//把数据写到mysql
val conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/urlcount?charactorEncoding=utf-8","root", "root")
//把spark结果插入到mysql中
val sql = "INSERT INTO url_data (xueyuan,number_one) VALUES (?,?)"
//执行sql
val statement = conn.prepareStatement(sql) statement.setString(1, x._1)
statement.setString(2, x._2.toString())
statement.executeUpdate()
statement.close()
conn.close()
}) //8.关闭资源
sc.stop()
}
}
2、mysql创建数据库和表
CREATE DATABASE urlcount;
USE urlcount; CREATE TABLE url_data(
uid INT PRIMARY KEY AUTO_INCREMENT,
xueyuan VARCHAR(50),
number_one VARCHAR(200)
)
3、结果

二、Spark提供的连接mysql的方式--jdbcRDD
1、JdbcRDDDemo类
import java.sql.DriverManager import org.apache.spark.rdd.JdbcRDD
import org.apache.spark.{SparkConf, SparkContext} /**
* spark提供的连接mysql的方式
* jdbcRDD
*/
object JdbcRDDDemo {
def main(args: Array[String]): Unit = {
//1.创建spark程序入口
val conf: SparkConf = new SparkConf().setAppName("JdbcRDDDemo").setMaster("local[2]")
val sc: SparkContext = new SparkContext(conf) //匿名函数
val connection = () => {
Class.forName("com.mysql.jdbc.Driver").newInstance()
DriverManager.getConnection("jdbc:mysql://localhost:3306/urlcount?characterEncoding=utf-8","root", "root")
} //查询数据
val jdbcRdd: JdbcRDD[(Int, String, String)] = new JdbcRDD(
//指定sparkContext
sc,
connection,
"SELECT * FROM url_data where uid >= ? AND uid <= ?",
//2个任务并行
1, 4, 2,
r => {
val uid = r.getInt(1)
val xueyuan = r.getString(2)
val number_one = r.getString(3)
(uid, xueyuan, number_one)
}
) val result: Array[(Int, String, String)] = jdbcRdd.collect()
println(result.toBuffer)
sc.stop()
}
}
2、结果
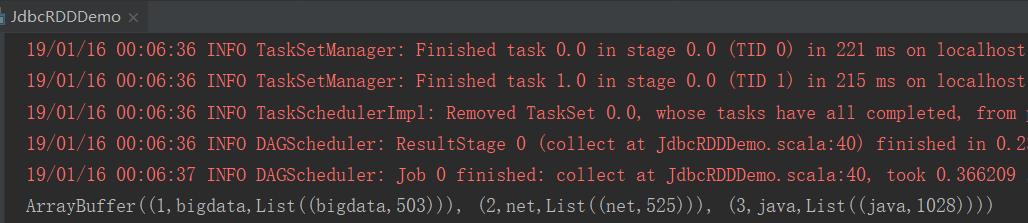
Spark与mysql整合的更多相关文章
- 大数据工具篇之Hive与MySQL整合完整教程
大数据工具篇之Hive与MySQL整合完整教程 一.引言 Hive元数据存储可以放到RDBMS数据库中,本文以Hive与MySQL数据库的整合为目标,详细说明Hive与MySQL的整合方法. 二.安装 ...
- 使用Apache Spark 对 mysql 调优 查询速度提升10倍以上
在这篇文章中我们将讨论如何利用 Apache Spark 来提升 MySQL 的查询性能. 介绍 在我的前一篇文章Apache Spark with MySQL 中介绍了如何利用 Apache Spa ...
- Hive+Sqoop+Mysql整合
Hive+Sqoop+Mysql整合 在本文中,LZ随意想到了一个场景: 车,道路,监控,摄像头 即当一辆车在道路上面行驶的时候,道路上面的监控点里面的摄像头就会对车进行数据采集. 我们对采集的数据进 ...
- 记录一次spark连接mysql遇到的问题
版权声明:本文为博主原创文章,未经博主允许不得转载 在使用spark连接mysql的过程中报错了,错误如下 08:51:32.495 [main] ERROR - Error loading fact ...
- [Spark][Python]Spark 访问 mysql , 生成 dataframe 的例子:
[Spark][Python]Spark 访问 mysql , 生成 dataframe 的例子: mydf001=sqlContext.read.format("jdbc").o ...
- freeradius+xl2tp+mysql整合
freeradius+xl2tp+mysql整合 搭了5个小时,可以说是入门到精通了.首先请确认你已经搭建好L2TP,并可以正常使用. 如何在Ubuntu下配置L2TP VPN L2TP使用radi ...
- spark SQL学习(spark连接 mysql)
spark连接mysql(打jar包方式) package wujiadong_sparkSQL import java.util.Properties import org.apache.spark ...
- spark第十篇:Spark与Kafka整合
spark与kafka整合需要引入spark-streaming-kafka.jar,该jar根据kafka版本有2个分支,分别是spark-streaming-kafka-0-8和spark-str ...
- spark练习--mysql的读取
前面我们一直操作的是,通过一个文件来读取数据,这个里面不涉及数据相关的只是,今天我们来介绍一下spark操作中存放与读取 1.首先我们先介绍的是把数据存放进入mysql中,今天介绍的这个例子是我们前两 ...
随机推荐
- js 获取ISO-8601格式时间字符串的时间戳
function getTimeStamp(isostr) { var parts = isostr.match(/\d+/g); return new Date(parts[0]+'-'+parts ...
- mysql 外键约束示例
-- 创建测试主表. ID 是主键.CREATE TABLE test_main ( id INT, value VARCHAR(10), PRIMARY KEY(id)); -- ...
- osgEarth设置模型旋转角度
#include<windows.h> #include <osgViewer/Viewer> #include <osgEarthDrivers/gdal/GDALOp ...
- Android的Fragment中onActivityResult不被调用
1.检查该Fragment所属的Activity中,是否重写了onActivityResult方法. 2.检查Fragment中的startActivityForResult的调用方式. 请确保不要使 ...
- ip防刷脚本
#!/bin/sh #防刷脚本 #env ACCESS_PATH=/home/wwwlogs ACCESS_LOG=y.log IPTABLES_TOP_LOG=iptables_top.log DR ...
- Android数据存储之SD卡
为了更好的存取应用程序的大文件数据,应用程序需要读. 写SD卡上的文件.SD卡大大扩充手机的存储能力. 操作SD首先要加权限: <!--在SDCard中创建与删除文件权限 --> < ...
- Esper学习之二:事件类型
Esper对事件有特殊的数据结构约定.能处理的事件结构有:POJO,java.util.Map,Object Array,XML 1.POJO 对于POJO,Esper要求对每一个私有属性要有gett ...
- 【大数据系列】hadoop集群的配置
一.hadoop的配置文件分类 1.只读类型的默认文件 core-default.xml hdfs-default.xml mapred-default.xml mapred-que ...
- 【Studio】解决格式化时,注释部分没有缩进的问题
android studio默认代码格式化(默认Ctrl+Alt+L),是让注释从每行最左边开始显示,比如这样: 我个人喜欢注释也要缩进对齐.其实这个需要自己设置,打开studio的设置,依次找 Se ...
- 怎样在excel中快速输入当前日期和时间
找到并启动我们的Microsoft Excel软件,如图 在excel中,我们先演示如何快速输入当前“日期”,先在一个“单元格”里面输入“Ctrl+:”(就是“Ctrl“键和“:”键的组合),效果 ...