Relu的理解
ReLU上的花样
CNN出现以来,感觉在各个地方,即便是非常小的地方都有点可以挖掘。比如ReLU。
ReLU的有效性体现在两个方面:
- 克服梯度消失的问题
- 加快训练速度
而这两个方面是相辅相成的,因为克服了梯度消失问题,所以训练才会快。
ReLU的起源,在这片博文里,对ReLU的起源的介绍已经很详细了,包括如何从生物神经衍生出来,如何与稀疏性进行关联等等。
其中有一段特别精彩的话我引用在下面:
几十年的机器学习发展中,我们形成了这样一个概念:非线性激活函数要比线性激活函数更加先进。
尤其是在布满Sigmoid函数的BP神经网络,布满径向基函数的SVM神经网络中,往往有这样的幻觉,非线性函数对非线性网络贡献巨大。
该幻觉在SVM中更加严重。核函数的形式并非完全是SVM能够处理非线性数据的主力功臣(支持向量充当着隐层角色)。
那么在深度网络中,对非线性的依赖程度就可以缩一缩。另外,在上一部分提到,稀疏特征并不需要网络具有很强的处理线性不可分机制。
综合以上两点,在深度学习模型中,使用简单、速度快的线性激活函数可能更为合适。
而本文要讲的,则是ReLU上的改进,所谓麻雀虽小,五脏俱全,ReLU虽小,但也是可以改进的。
ReLU的种类
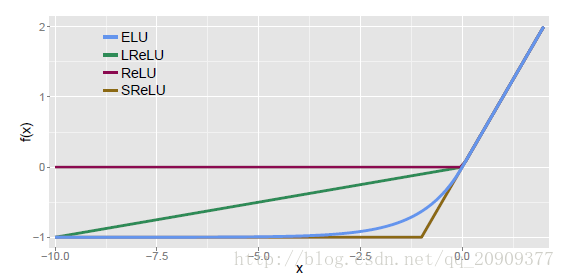
ReLU的区分主要在负数端,根据负数端斜率的不同来进行区分,大致如下图所示。

普通的ReLU负数端斜率是0,Leaky ReLU则是负数端有一个比较小的斜率,而PReLU则是在后向传播中学习到斜率。而Randomized Leaky ReLU则是使用一个均匀分布在训练的时候随机生成斜率,在测试的时候使用均值斜率来计算。
效果
其中,NDSB数据集是Kaggle的比赛,而RReLU正是在这次比赛中崭露头角的。

通过上述结果,可以看到四点:
- 对于leaky ReLU来说,如果斜率很小,那么与ReLU并没有大的不同,当斜率大一些时,效果就好很多。
- 在训练集上,PReLU往往能达到最小的错误率,说明PReLU容易过拟合。
- 在NSDB数据集上RReLU的提升比cifar10和cifar100上的提升更加明显,而NSDB数据集比较小,从而可以说明,RReLU在与过拟合的对抗中更加有效
- 对于RReLU来说,还需要研究一下随机化得斜率是怎样影响训练和测试过程的。
参考文献
[1]. Xu B, Wang N, Chen T, et al. Empirical evaluation of rectified activations in convolutional network[J]. arXiv preprint arXiv:1505.00853, 2015.
ReLU、LReLU、PReLU、CReLU、ELU、SELU
ReLU
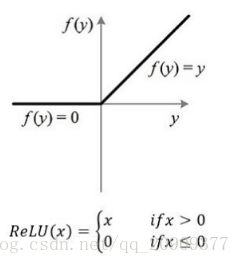
tensorflow中:tf.nn.relu(features, name=None)
LReLU
(Leaky-ReLU) 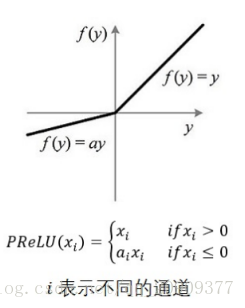
其中aiai是固定的。ii表示不同的通道对应不同的aiai.
tensorflow中:tf.nn.leaky_relu(features, alpha=0.2, name=None)
PReLU
其中aiai是可以学习的的。如果ai=0ai=0,那么 PReLU 退化为ReLU;如果 aiai是一个很小的固定值(如ai=0.01ai=0.01),则 PReLU 退化为 Leaky ReLU(LReLU)。
PReLU 只增加了极少量的参数,也就意味着网络的计算量以及过拟合的危险性都只增加了一点点。特别的,当不同 channels 使用相同的aiai时,参数就更少了。BP 更新aiai时,采用的是带动量的更新方式(momentum)。
tensorflow中:没找到啊!
CReLU
(Concatenated Rectified Linear Units) 
tensorflow中:tf.nn.crelu(features, name=None)
ELU
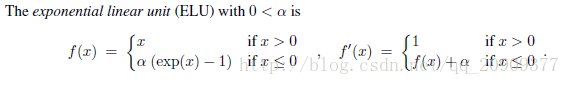
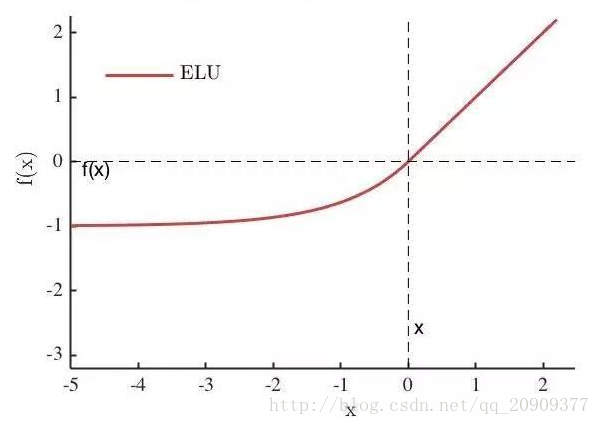
其中α是一个可调整的参数,它控制着ELU负值部分在何时饱和。
右侧线性部分使得ELU能够缓解梯度消失,而左侧软饱能够让ELU对输入变化或噪声更鲁棒。ELU的输出均值接近于零,所以收敛速度更快
tensorflow中:tf.nn.elu(features, name=None)
SELU
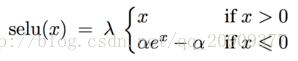
经过该激活函数后使得样本分布自动归一化到0均值和单位方差(自归一化,保证训练过程中梯度不会爆炸或消失,效果比Batch Normalization 要好)
其实就是ELU乘了个lambda,关键在于这个lambda是大于1的。以前relu,prelu,elu这些激活函数,都是在负半轴坡度平缓,这样在activation的方差过大的时候可以让它减小,防止了梯度爆炸,但是正半轴坡度简单的设成了1。而selu的正半轴大于1,在方差过小的的时候可以让它增大,同时防止了梯度消失。这样激活函数就有一个不动点,网络深了以后每一层的输出都是均值为0方差为1。
tensorflow中:tf.nn.selu(features, name=None)
Relu的理解的更多相关文章
- 【深度学习】深入理解ReLU(Rectifie Linear Units)激活函数
论文参考:Deep Sparse Rectifier Neural Networks (很有趣的一篇paper) Part 0:传统激活函数.脑神经元激活频率研究.稀疏激活性 0.1 一般激活函数有 ...
- caffe_手写数字识别Lenet模型理解
这两天看了Lenet的模型理解,很简单的手写数字CNN网络,90年代美国用它来识别钞票,准确率还是很高的,所以它也是一个很经典的模型.而且学习这个模型也有助于我们理解更大的网络比如Imagenet等等 ...
- Deep learning:四十五(maxout简单理解)
maxout出现在ICML2013上,作者Goodfellow将maxout和dropout结合后,号称在MNIST, CIFAR-10, CIFAR-100, SVHN这4个数据上都取得了start ...
- 深度神经网络结构以及Pre-Training的理解
Logistic回归.传统多层神经网络 1.1 线性回归.线性神经网络.Logistic/Softmax回归 线性回归是用于数据拟合的常规手段,其任务是优化目标函数:$h(\theta )=\thet ...
- 深度学习研究理解5:Visualizing and Understanding Convolutional Networks(转)
Visualizing and understandingConvolutional Networks 本文是Matthew D.Zeiler 和Rob Fergus于(纽约大学)13年撰写的论文,主 ...
- 机器学习:从编程的角度理解BP神经网络
1.简介(只是简单介绍下理论内容帮助理解下面的代码,如果自己写代码实现此理论不够) 1) BP神经网络是一种多层网络算法,其核心是反向传播误差,即: 使用梯度下降法(或其他算法),通过反向传播来不断调 ...
- 【深度学习】深入理解Batch Normalization批标准化
这几天面试经常被问到BN层的原理,虽然回答上来了,但还是感觉答得不是很好,今天仔细研究了一下Batch Normalization的原理,以下为参考网上几篇文章总结得出. Batch Normaliz ...
- DeconvNet 论文阅读理解
学习语义分割反卷积网络DeconvNet 一点想法:反卷积网络就是基于FCN改进了上采样层,用到了反池化和反卷积操作,参数量2亿多,非常大,segnet把两个全连接层去掉,效果也能很好,显著减少了参数 ...
- 通过Visualizing Representations来理解Deep Learning、Neural network、以及输入样本自身的高维空间结构
catalogue . 引言 . Neural Networks Transform Space - 神经网络内部的空间结构 . Understand the data itself by visua ...
随机推荐
- AdminLTE, Color Admin
AdminLTE, Color Adminhttps://github.com/almasaeed2010/AdminLTE/http://www.seantheme.com/color-admin- ...
- 关于https中的算法
1,对称加密算法,是指加密和解密使用相同的密钥,典型的算法有RSA,DSA,DH 2,非对称加密算法:又称为公钥加密算法,是指加密和解密使用不同的密钥,公共的公钥用于加密,私钥用于解密,比如第一次请求 ...
- 从tableview中拖动某个精灵
virtual void registerWithTouchDispatcher(void); virtual bool ccTouchBegan(CCTouch *pTouch,CCEvent *p ...
- [SQL in Azure] Getting Started with SQL Server in Azure Virtual Machines
This topic provides guidelines on how to sign up for SQL Server on a Azure virtual machine and how t ...
- tensorflow笔记3:CRF函数:tf.contrib.crf.crf_log_likelihood()
在分析训练代码的时候,遇到了,tf.contrib.crf.crf_log_likelihood,这个函数,于是想简单理解下: 函数的目的:使用crf 来计算损失,里面用到的优化方法是:最大似然估计 ...
- PBR Metallic/Roughness工作流中Albedo与F0的计算方法
首先简单回顾一下典型的纯金属与绝缘体的PBR属性: 纯金属: Albedo(diff): 0 F0(spec): >0.3 (or 0.5, epic/allegorithmic etc.) M ...
- android工程导入没有错误,运行提示Unable to instantiate activity ComponentInfo
导入小米clientside_android_sdk的demo OAuth-OpenAuthDemo,点Java Build Path的Libraries内Add External JARs,将oau ...
- 【linux】dpkg info修复及dpkg: warning: files list file for package
mv /var/lib/dpkg/info /var/lib/dpkg/info.bak //现将info文件夹更名 sudo mkdir /var/lib/dpkg/info //再新建一个新的in ...
- 综合出现NSScanner: nil string argument libc++abi.dylib: terminat错误的解决方案
在开发中出现了这个错误,断点查找很久,没找到问题所在的代码,google下,发现了下面这几点会产生这个错误: 首先,顾名思义,错误原因是我们在调用某个方法的时候,传入了一个空字符串(注意区别于字符串内 ...
- NewStyleClass学习笔记[一]
from : https://www.python.org/doc/newstyle/ New-style Classes Unfortunately(遗憾,不幸的), new-style class ...