混合高斯模型(Mixtures of Gaussians)
http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006924.html
这篇讨论使用期望最大化算法(Expectation-Maximization)来进行密度估计(density estimation)。
与k-means一样,给定的训练样本是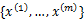 ,我们将隐含类别标签用
,我们将隐含类别标签用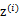 表示。与k-means的硬指定不同,我们首先认为
表示。与k-means的硬指定不同,我们首先认为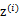 是满足一定的概率分布的,这里我们认为满足多项式分布,
是满足一定的概率分布的,这里我们认为满足多项式分布,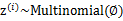 ,其中
,其中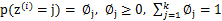 ,
,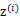 有k个值{1,…,k}可以选取。而且我们认为在给定
有k个值{1,…,k}可以选取。而且我们认为在给定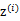 后,
后,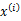 满足多值高斯分布,即
满足多值高斯分布,即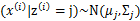 。由此可以得到联合分布
。由此可以得到联合分布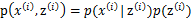 。
。
整个模型简单描述为对于每个样例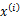 ,我们先从k个类别中按多项式分布抽取一个
,我们先从k个类别中按多项式分布抽取一个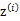 ,然后根据
,然后根据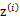 所对应的k个多值高斯分布中的一个生成样例
所对应的k个多值高斯分布中的一个生成样例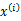 ,。整个过程称作混合高斯模型。注意的是这里的
,。整个过程称作混合高斯模型。注意的是这里的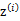 仍然是隐含随机变量。模型中还有三个变量
仍然是隐含随机变量。模型中还有三个变量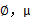 和
和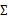 。最大似然估计为
。最大似然估计为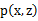 。对数化后如下:
。对数化后如下:
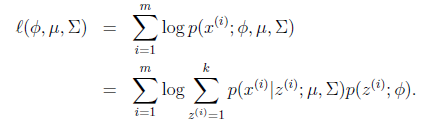
这个式子的最大值是不能通过前面使用的求导数为0的方法解决的,因为求的结果不是close form。但是假设我们知道了每个样例的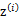 ,那么上式可以简化为:
,那么上式可以简化为:
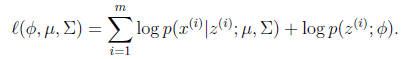
这时候我们再来对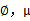 和
和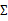 进行求导得到:
进行求导得到:
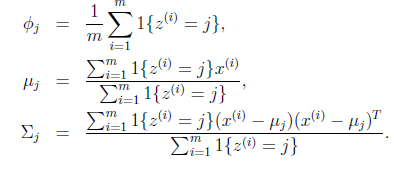
 就是样本类别中
就是样本类别中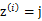 的比率。
的比率。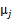 是类别为j的样本特征均值,
是类别为j的样本特征均值,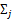 是类别为j的样例的特征的协方差矩阵。
是类别为j的样例的特征的协方差矩阵。
实际上,当知道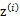 后,最大似然估计就近似于高斯判别分析模型(Gaussian discriminant analysis model)了。所不同的是GDA中类别y是伯努利分布,而这里的z是多项式分布,还有这里的每个样例都有不同的协方差矩阵,而GDA中认为只有一个。
后,最大似然估计就近似于高斯判别分析模型(Gaussian discriminant analysis model)了。所不同的是GDA中类别y是伯努利分布,而这里的z是多项式分布,还有这里的每个样例都有不同的协方差矩阵,而GDA中认为只有一个。
之前我们是假设给定了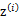 ,实际上
,实际上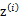 是不知道的。那么怎么办呢?考虑之前提到的EM的思想,第一步是猜测隐含类别变量z,第二步是更新其他参数,以获得最大的最大似然估计。用到这里就是:
是不知道的。那么怎么办呢?考虑之前提到的EM的思想,第一步是猜测隐含类别变量z,第二步是更新其他参数,以获得最大的最大似然估计。用到这里就是:
|
循环下面步骤,直到收敛: { (E步)对于每一个i和j,计算
(M步),更新参数:
} |
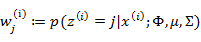
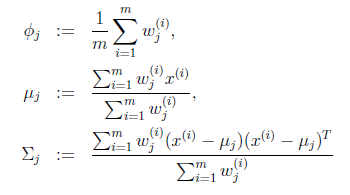
在E步中,我们将其他参数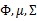 看作常量,计算
看作常量,计算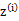 的后验概率,也就是估计隐含类别变量。估计好后,利用上面的公式重新计算其他参数,计算好后发现最大化最大似然估计时,
的后验概率,也就是估计隐含类别变量。估计好后,利用上面的公式重新计算其他参数,计算好后发现最大化最大似然估计时,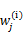 值又不对了,需要重新计算,周而复始,直至收敛。
值又不对了,需要重新计算,周而复始,直至收敛。
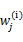 的具体计算公式如下:
的具体计算公式如下:
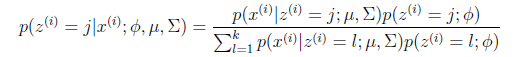
这个式子利用了贝叶斯公式。
这里我们使用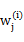 代替了前面的
代替了前面的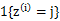 ,由简单的0/1值变成了概率值。
,由简单的0/1值变成了概率值。
对比K-means可以发现,这里使用了“软”指定,为每个样例分配的类别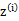 是有一定的概率的,同时计算量也变大了,每个样例i都要计算属于每一个类别j的概率。与K-means相同的是,结果仍然是局部最优解。对其他参数取不同的初始值进行多次计算不失为一种好方法。
是有一定的概率的,同时计算量也变大了,每个样例i都要计算属于每一个类别j的概率。与K-means相同的是,结果仍然是局部最优解。对其他参数取不同的初始值进行多次计算不失为一种好方法。
虽然之前再K-means中定性描述了EM的收敛性,仍然没有定量地给出,还有一般化EM的推导过程仍然没有给出。下一篇着重介绍这些内容。
混合高斯模型(Mixtures of Gaussians)的更多相关文章
- 混合高斯模型(Mixtures of Gaussians)和EM算法
这篇讨论使用期望最大化算法(Expectation-Maximization)来进行密度估计(density estimation). 与k-means一样,给定的训练样本是,我们将隐含类别标签用表示 ...
- 混合高斯模型的EM求解(Mixtures of Gaussians)及Python实现源代码
今天为大家带来混合高斯模型的EM推导求解过程. watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQveHVhbnl1YW5zZW4=/font/5a6L5L2T/ ...
- <转>与EM相关的两个算法-K-mean算法以及混合高斯模型
转自http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006924.html http://www.cnblogs.com/jerrylead/ ...
- EM相关两个算法 k-mean算法和混合高斯模型
转自http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006924.html http://www.cnblogs.com/jerrylead/ ...
- 混合高斯模型(GMM)推导及实现
作者:桂. 时间:2017-03-20 06:20:54 链接:http://www.cnblogs.com/xingshansi/p/6584555.html 声明:欢迎被转载,不过记得注明出处哦 ...
- PRML读书会第九章 Mixture Models and EM(Kmeans,混合高斯模型,Expectation Maximization)
主讲人 网络上的尼采 (新浪微博: @Nietzsche_复杂网络机器学习) 网络上的尼采(813394698) 9:10:56 今天的主要内容有k-means.混合高斯模型. EM算法.对于k-me ...
- Opencv混合高斯模型前景分离
#include "stdio.h" #include "string.h" #include "iostream" #include &q ...
- 混合高斯模型:opencv中MOG2的代码结构梳理
/* 头文件:OurGaussmix2.h */ #include "opencv2/core/core.hpp" #include <list> #include&q ...
- [zz] 混合高斯模型 Gaussian Mixture Model
聚类(1)——混合高斯模型 Gaussian Mixture Model http://blog.csdn.net/jwh_bupt/article/details/7663885 聚类系列: 聚类( ...
随机推荐
- 笨鸟就要勤奋&专注
最近两天在找工作的过程中颇受打击,两家高大上的公司看起来就是要收集世界上最聪明的人~,在参加G家的online test之前还天真的认为一不小心通过了怎么办呢?考完试之后才发现真的是想多了,关于题目看 ...
- C#取得Web程序和非Web程序的根目录的N种取法
取得控制台应用程序的根目录方法方法1.Environment.CurrentDirectory 取得或设置当前工作目录的完整限定路径方法2.AppDomain.CurrentDomain.BaseDi ...
- 【BZOJ5094】硬盘检测 概率
[BZOJ5094]硬盘检测 Description 很久很久以前,小Q买了一个大小为n单元的硬盘,并往里随机写入了n个32位无符号整数.因为时间过去太久,硬盘上的容量字眼早已模糊不清,小Q也早已忘记 ...
- linux 命令行常用快捷键
linux命令行常用快捷键,区别于vim编辑器快捷键.熟练掌握下面的快捷键可提高操作linux的工作效率.当然最重要的是可以装屌. 1.移动光标快捷键Ctrl+a光标回到命令行首* Ctrl+e光标回 ...
- Linux下 磁盘扩容的两种方式
Hadoop扩容 概述 Hadoop存储容量或计算能力不能满足日益增长的需求时,就需要扩容. 扩容有两个方案: 1) 增加磁盘 2) 增加节点 方案一:扩大虚拟磁盘 扩大容量 将虚拟的Linux关闭, ...
- mongodb的学习笔记一(集合和文档的增删改查)
1数据库的增删改查 一.增加一个数据库: use blog-----切换到指定的数据库,如果数据库不存在,则自动创建该数据库(新建的数据库,如果没有存储对应的集合,是不会显示出来的) 二.删除一个数据 ...
- HDU 2544 - 最短路 - [堆优化dijkstra][最短路模板题]
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=2544 Time Limit: 5000/1000 MS (Java/Others) Memory Li ...
- 【源码】rm zip 删除文件夹中大量的小文件 百万 扫描文件时间
rm 删除文件夹中大量的小文件 百万 迟迟未删除 在扫描文件? rm删除命令源码分析 - ty_laurel的博客 - CSDN博客 https://blog.csdn.net/ty_laurel/ ...
- Rikka with Parenthesis II---hdu5831(括号匹配)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=5831 给你一个只包含‘(’‘)’的字符串,然后让我们交换两个字符一次,问是否能得到一个合法的匹配:必须 ...
- Catch---hdu3478(染色法判断是否含有奇环)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=3478 题意:有n个路口,m条街,一小偷某一时刻从路口 s 开始逃跑,下一时刻都跑沿着街跑到另一路口,问 ...