构建高性能web之路------mysql读写分离实战(转)
一个完整的mysql读写分离环境包括以下几个部分:
- 应用程序client
- database proxy
- database集群
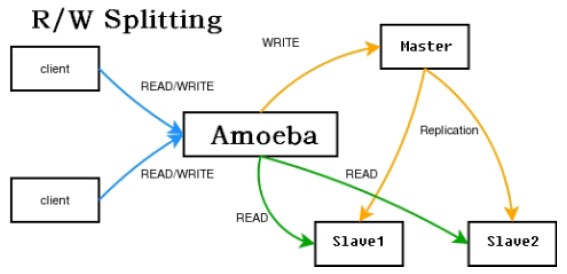
在本次实战中,应用程序client基于c3p0连接后端的database proxy。database proxy负责管理client实际访问database的路由策略,采用开源框架amoeba。database集群采用mysql的master-slave的replication方案。整个环境的结构图如下所示:
实战步骤与详解
一.搭建mysql的master-slave环境
1)分别在host1(10.20.147.110)和host2(10.20.147.111)上安装mysql(5.0.45),具体安装方法可见官方文档
2)配置master
首先编辑/etc/my.cnf,添加以下配置:
log-bin=mysql-bin #slave会基于此log-bin来做replication
server-id=1 #master的标示
binlog-do-db = amoeba_study #用于master-slave的具体数据库
然后添加专门用于replication的用户:
mysql> GRANT REPLICATION SLAVE ON *.* TO repl@10.20.147.111 IDENTIFIED BY '111111';
重启mysql,使得配置生效:
/etc/init.d/mysqld restart
最后查看master状态:

3)配置slave
首先编辑/etc/my.cnf,添加以下配置:
server-id=2 #slave的标示
配置生效后,配置与master的连接:
mysql> CHANGE MASTER TO
-> MASTER_HOST='10.20.147.110',
-> MASTER_USER='repl',
-> MASTER_PASSWORD='111111',
-> MASTER_LOG_FILE='mysql-bin.000003',
-> MASTER_LOG_POS=161261;
其中MASTER_HOST是master机的ip,MASTER_USER和MASTER_PASSWORD就是我们刚才在master上添加的用户,MASTER_LOG_FILE和MASTER_LOG_POS对应与master status里的信息
最后启动slave:
mysql> start slave;
4)验证master-slave搭建生效
通过查看slave机的log(/var/log/mysqld.log):
100703 10:51:42 [Note] Slave I/O thread: connected to master 'repl@10.20.147.110:3306', replication started in log 'mysql-bin.000003' at position 161261
如看到以上信息则证明搭建成功,如果有问题也可通过此log找原因
二.搭建database proxy
此次实战中database proxy采用amoeba ,它的相关信息可以查阅官方文档,不在此详述
1)安装amoeba
下载amoeba(1.2.0-GA)后解压到本地(D:/openSource/amoeba-mysql-1.2.0-GA),即完成安装
2)配置amoeba
先配置proxy连接和与各后端mysql服务器连接信息(D:/openSource/amoeba-mysql-1.2.0-GA/conf/amoeba.xml):
<server>
<!-- proxy server绑定的端口 -->
<property name="port"></property> <!-- proxy server绑定的IP -->
<!--
<property name="ipAddress">127.0.0.1</property>
-->
<!-- proxy server net IO Read thread size -->
<property name="readThreadPoolSize"></property> <!-- proxy server client process thread size -->
<property name="clientSideThreadPoolSize"></property> <!-- mysql server data packet process thread size -->
<property name="serverSideThreadPoolSize"></property> <!-- socket Send and receive BufferSize(unit:K) -->
<property name="netBufferSize"></property> <!-- Enable/disable TCP_NODELAY (disable/enable Nagle's algorithm). -->
<property name="tcpNoDelay">true</property> <!-- 对外验证的用户名 -->
<property name="user">root</property> <!-- 对外验证的密码 -->
<property name="password">root</property>
</server>
以上是proxy提供给client的连接配置
<dbServerList>
<dbServer name="server1">
<!-- PoolableObjectFactory实现类 -->
<factoryConfig class="com.meidusa.amoeba.mysql.net.MysqlServerConnectionFactory">
<property name="manager">defaultManager</property> <!-- 真实mysql数据库端口 -->
<property name="port"></property> <!-- 真实mysql数据库IP -->
<property name="ipAddress">10.20.147.110</property>
<property name="schema">amoeba_study</property> <!-- 用于登陆mysql的用户名 -->
<property name="user">root</property> <!-- 用于登陆mysql的密码 -->
<property name="password"></property> </factoryConfig> <!-- ObjectPool实现类 -->
<poolConfig class="com.meidusa.amoeba.net.poolable.PoolableObjectPool">
<property name="maxActive"></property>
<property name="maxIdle"></property>
<property name="minIdle"></property>
<property name="minEvictableIdleTimeMillis"></property>
<property name="timeBetweenEvictionRunsMillis"></property>
<property name="testOnBorrow">true</property>
<property name="testWhileIdle">true</property>
</poolConfig>
</dbServer>
<dbServer name="server2"> <!-- PoolableObjectFactory实现类 -->
<factoryConfig class="com.meidusa.amoeba.mysql.net.MysqlServerConnectionFactory">
<property name="manager">defaultManager</property> <!-- 真实mysql数据库端口 -->
<property name="port"></property> <!-- 真实mysql数据库IP -->
<property name="ipAddress">10.20.147.111</property>
<property name="schema">amoeba_study</property> <!-- 用于登陆mysql的用户名 -->
<property name="user">root</property> <!-- 用于登陆mysql的密码 -->
<property name="password"></property> </factoryConfig> <!-- ObjectPool实现类 -->
<poolConfig class="com.meidusa.amoeba.net.poolable.PoolableObjectPool">
<property name="maxActive"></property>
<property name="maxIdle"></property>
<property name="minIdle"></property>
<property name="minEvictableIdleTimeMillis"></property>
<property name="timeBetweenEvictionRunsMillis"></property>
<property name="testOnBorrow">true</property>
<property name="testWhileIdle">true</property>
</poolConfig>
</dbServer>
</dbServerList>
以上是proxy与后端各mysql数据库服务器配置信息,具体配置见注释很明白了
最后配置读写分离策略:
<queryRouter class="com.meidusa.amoeba.mysql.parser.MysqlQueryRouter">
<property name="LRUMapSize"></property>
<property name="defaultPool">server1</property>
<property name="writePool">server1</property>
<property name="readPool">server2</property>
<property name="needParse">true</property>
</queryRouter>
从以上配置不然发现,写操作路由到server1(master),读操作路由到server2(slave)
3)启动amoeba
在命令行里运行D:/openSource/amoeba-mysql-1.2.0-GA/amoeba.bat即可:
log4j:WARN log4j config load completed from file:D:/openSource/amoeba-mysql-1.2.0-GA/conf/log4j.xml
log4j:WARN ip access config load completed from file:D:/openSource/amoeba-mysql-1.2.0-GA/conf/access_list.conf
2010-07-03 09:55:33,821 INFO net.ServerableConnectionManager - Server listening on 0.0.0.0/0.0.0.0:8066.
三.client端调用与测试
1)编写client调用程序
具体程序细节就不详述了,只是一个最普通的基于mysql driver的jdbc的数据库操作程序
2)配置数据库连接
本client基于c3p0,具体数据源配置如下:
<bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource"
destroy-method="close">
<property name="driverClass" value="com.mysql.jdbc.Driver" />
<property name="jdbcUrl" value="jdbc:mysql://localhost:8066/amoeba_study" />
<property name="user" value="root" />
<property name="password" value="root" />
<property name="minPoolSize" value="" />
<property name="maxPoolSize" value="" />
<property name="maxIdleTime" value="" />
<property name="acquireIncrement" value="" />
<property name="maxStatements" value="" />
<property name="initialPoolSize" value="" />
<property name="idleConnectionTestPeriod" value="" />
<property name="acquireRetryAttempts" value="" />
<property name="acquireRetryDelay" value="" />
<property name="breakAfterAcquireFailure" value="false" />
<property name="testConnectionOnCheckout" value="true" />
<property name="testConnectionOnCheckin" value="false" />
</bean>
值得注意是,client端只需连到proxy,与实际的数据库没有任何关系,因此jdbcUrl、user、password配置都对应于amoeba暴露出来的配置信息
3)调用与测试
首先插入一条数据:insert into zone_by_id(id,name) values(20003,'name_20003')
通过查看master机上的日志/var/lib/mysql/mysql_log.log:
100703 11:58:42 1 Query set names latin1
1 Query SET NAMES latin1
1 Query SET character_set_results = NULL
1 Query SHOW VARIABLES
1 Query SHOW COLLATION
1 Query SET autocommit=1
1 Query SET sql_mode='STRICT_TRANS_TABLES'
1 Query SHOW VARIABLES LIKE 'tx_isolation'
1 Query SHOW FULL TABLES FROM `amoeba_study` LIKE 'PROBABLYNOT'
1 Prepare [1] insert into zone_by_id(id,name) values(?,?)
1 Prepare [2] insert into zone_by_id(id,name) values(?,?)
1 Execute [2] insert into zone_by_id(id,name) values(20003,'name_20003')
得知写操作发生在master机上
通过查看slave机上的日志/var/lib/mysql/mysql_log.log:
100703 11:58:42 2 Query insert into zone_by_id(id,name) values(20003,'name_20003')
得知slave同步执行了这条语句
然后查一条数据:select t.name from zone_by_id t where t.id = 20003
通过查看slave机上的日志/var/lib/mysql/mysql_log.log:
100703 12:02:00 33 Query set names latin1
33 Prepare [1] select t.name from zone_by_id t where t.id = ?
33 Prepare [2] select t.name from zone_by_id t where t.id = ?
33 Execute [2] select t.name from zone_by_id t where t.id = 20003
得知读操作发生在slave机上
并且通过查看slave机上的日志/var/lib/mysql/mysql_log.log发现这条语句没在master上执行
通过以上验证得知简单的master-slave搭建和实战得以生效
构建高性能web之路------mysql读写分离实战(转)的更多相关文章
- 构建高性能web之路------mysql读写分离实战
http://blog.csdn.net/cutesource/article/details/5710645 http://www.jb51.net/article/38953.htm http:/ ...
- mysql读写分离实战
一个完整的MySQL读写分离环境包括以下几个部分: 应用程序client database proxy database集群 在本次实战中,应用程序client基于c3p0连接后端的database ...
- SpringBoot + MyBatis + MySQL 读写分离实战
1. 引言 读写分离要做的事情就是对于一条SQL该选择哪个数据库去执行,至于谁来做选择数据库这件事儿,无非两个,要么中间件帮我们做,要么程序自己做.因此,一般来讲,读写分离有两种实现方式.第一种是依靠 ...
- 【读书笔记】2016.12.10 《构建高性能Web站点》
本文地址 分享提纲: 1. 概述 2. 知识点 3. 待整理点 4. 参考文档 1. 概述 1.1)[该书信息] <构建高性能Web站点>: -- 百度百科 -- 本书目录: 第1章 绪论 ...
- 《构建高性能web站点》随笔 无处不在的性能问题
前言– 追寻大牛的足迹,无处不在的“性能”问题. 最近在读郭欣大牛的<构建高性能Web站点>,读完收益颇多.作者从HTTP.多级缓存.服务器并发策略.数据库.负载均衡.分布式文件系统多个方 ...
- 构建高性能WEB站点笔记三
构建高性能WEB站点笔记三 第10章 分布式缓存 10.1数据库的前端缓存区 文件系统内核缓冲区,位于物理内存的内核地址空间,除了使用O_DIRECT标记打开的文件以外,所有对磁盘文件的读写操作都要经 ...
- 构建高性能web站点--读书大纲
用户输入你的站点网址,等了半天..还没打开,裤衩一下就给关了.好了,流失了一个用户.为什么会有这样的问题呢.怎么解决自己站点“慢”,体验差的问题呢. 在这段等待的时间里,到底发生了什么?事实上这并不简 ...
- 构建高性能WEB站点笔记二
构建高性能WEB站点笔记 因为是跳着看的,后面看到有提到啥epoll模型,那就补充下前面的知识. 第三章 服务器并发处理能力 3.2 CPU并发计算 进程 好处:cpu 时间的轮流使用.对CPU计算和 ...
- MySQL读写分离技术
1.简介 当今MySQL使用相当广泛,随着用户的增多以及数据量的增大,高并发随之而来.然而我们有很多办法可以缓解数据库的压力.分布式数据库.负载均衡.读写分离.增加缓存服务器等等.这里我们将采用读写分 ...
随机推荐
- Linux杀毒软件ClamAV初次体验
1:官网 http://www.clamav.net 2:Ubuntu下安装ClamAV sudo apt-get update--更新系统 sudo apt-get install clamav-- ...
- 【Python】torrentParser1.02
#------------------------------------------------------------------------------------ # torrentParse ...
- 【mybatis】多次查询缓存的问题
转自:http://cheng-xinwei.iteye.com/blog/2021700?utm_source=tuicool&utm_medium=referral 最近在使用mybati ...
- android中RecyclerView控件实现点击事件
RecyclerView控件实现点击事件跟ListView控件不同,并没有提供类似setOnItemClickListener()这样的注册监听器方法,而是需要自己给子项具体的注册点击事件. 本文的例 ...
- iOS编程(双语版)-视图-Autolayout代码初步
一谈到Autolayout,初学者肯定想到的是IB中使用拖拽啊,pin啊各种鼠标操作来进行添加各种约束. 今天我们要聊得是如何利用代码来添加视图间的约束. 我们来看一个例子: (Objective-C ...
- oneinstack一键部署linux生产环境那点事(ubuntu)
http://oneinstack.com/install/ (1)将oneinstack-full.tar.gz最新版安装文件上传至/usr/local/下 (2)解压tar xzvf oneins ...
- 在hadoop上运行java文件
hadoop 2.x版本 编译:javac -d . -classpath /usr/lib/hadoop/hadoop-common-2.2.0.2.0.6.0-102.jar TestGetPat ...
- Array相关的属性和方法
这里只是做了相关的列举,具体的使用方法,请参考网址. Array 对象属性 constructor 返回对创建此对象的数组函数的引用. var test=new Array(); if (test.c ...
- 解决 ERROR in native method: JDWP No transports initialized, jvmtiError=AGENT_ERROR_TRANSPORT_INIT(197)
在/etc/hosts文件中加入下面一行内容 127.0.0.1 localhost.localdomain localhost
- 关于Git HEAD^与HEAD~的关系
关于Git HEAD^与HEAD~的关系 请参考下图,来自stackoverflow http://stackoverflow.com/questions/2221658/whats-the-diff ...