jdk1.8 HashMap的实现
在了解HashMap之前,我们先进行位运算知识的补充
1.Java 位运算:(都是二进制的运算)
- << :相当于乘以2的倍数 --->1<<4 =1*2*2*2*2 =16
- >> :相当于处以2的倍数 ----> 8>>3 = 8/8 =1
- >>> :空位都用0 来补位;
- 2的次幂-1 的二进制低位都是1; 1-->1 3-->11 7 -->111 15-->1111
在了解ArrayList 和LinkedList 数据结构时候,我们知道arraylist 的查询数据上很快的,arraylist 的增删速度是很快的所以--
HashMap 所使用的数据结构是综合了ArrayList 查询速度快和LinkedList 增删速度快快的优点,使用了数组加单向链表的结构进行数据的存储,再加上
在1.8 中,为了避免链表数据过于庞大,在链表数据超过一定的值之后,会将链表的结构转换为红黑树来提升效率,如下图:
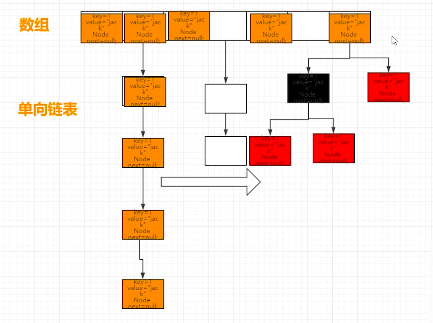
所以它的内部肯定也维护了像LinkedList 一样的node 节点,只不过是单向节点,如下:Node节点维护了key,value ,hash 值,以及用于链接下一个Node 节点的next;
/**
* Basic hash bin node, used for most entries. (See below for
* TreeNode subclass, and in LinkedHashMap for its Entry subclass.)
*/
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next; Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
那么链表在什么情况下转换成红黑树,红黑树什么时候转换为链表呢?
HashMap 提供了默认的阈值静态常量进行切换;节点数大于8时候会使用红黑树,小于6时候会使用单向链表
/**
* The bin count threshold for using a tree rather than list for a
* bin. Bins are converted to trees when adding an element to a
* bin with at least this many nodes. The value must be greater
* than 2 and should be at least 8 to mesh with assumptions in
* tree removal about conversion back to plain bins upon
* shrinkage.
*/
static final int TREEIFY_THRESHOLD = 8; /**
* The bin count threshold for untreeifying a (split) bin during a
* resize operation. Should be less than TREEIFY_THRESHOLD, and at
* most 6 to mesh with shrinkage detection under removal.
*/
static final int UNTREEIFY_THRESHOLD = 6;
接下来我们揭开HashMap(1.8) 的神秘面纱:
(一).在HashMap 默认构造函数中,只进行了加载因子的初始化,不同于1.5中,在构造的时候会初始化一个16大小容量的数组;
关于加载因子上什么,这个一开始肯定很懵逼,这个我们后面说

(二).我们直接看HashMap 的put 方法干了什么,这个了解了,其他的都迎刃而解;
1. 算出一个hashcode 值

在里面又进行了hash 函数的调用-->用于进行算出一个hash值,这一步也是一个很关键的一步,
进行了code 值的高16位与低16位的一个异或运算,>>> 应该不陌生吧,向右位移16 位,前16高位会被0补齐;
这样算出来的code值能会很好被散列的填充到数组中;

2.接下来就是真正的添加操作了,

-->首先是定义了一个Node 数组 以及Node 对象
Node<K,V>[] tab; Node<K,V> p; int n, i;
-->在判断table 是否为空,这个table 是在HashMap的全局变量中维护 ,在第一使用的时候被初始化,有必要的话,会被改变大小,它的长度是2的次幂
-->第一次使用的时候肯定是空,所以 resize() 方法进行了对table 的初始化,当然了resize() 这里是进行初始化的,它的作用还有很多,下面讲;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
接下来就是 resize()方法在这里干了什么操作呢?内容很多,这里的初始化table 主要是进行了

成员变量 threshold 赋值 操作:这里的加载因子0.75就起了作用了,加载因子作用就是用于标示当数组里的数据size 到达数组的大小乘以加载因子的大小时候,会进行
数组的扩充;这里就是一些默认的赋值操作;
默认的 DEFAULT_INITIAL_CAPACITY = 1 << 4; 即 1*2*2*2*2 = 16
16*0.75 =12 ,所以 newThr =12

初始化数组table 的大小:

---> 初始化完成之后, 我们有了Node数组,接下来又进行了一个与运算的操作;是不是很迷茫,为什么还要进行与运算呢?
哈哈是为了保证数组的下标不越界,比如我们初始化的数组大小为16 ,那么下标一定要是在【0-15】之间,一般是有两种方法(只适合2的次幂),能够保证
命中率很高的进行元素的散列分布;不浪费数组空间,提升查询的效率
% 运算 : 任意一个值%16 --> 取到的值肯定是在0-16之内,不包含16;
& 与运算:(16-1)& 任意一个值--> 取到的值也肯定是在0-16 之内,不包含16;
这两种运算结果是一模一样,一般 &与运算的效率会高一些;890 % 16 等于 15& 890

---> 如果数组下标为空 ,直接进行数组赋值
---> 如果数组下标元素不为空 ,则就行链表操作

解读: 当数组下标元素不为空时候,下标元素Node 维护的hash 值 等于要添加进来的键的hash 且key 值相等的时候,大家都知道新值会替代旧值,源码操作如下:
保存旧值返回,新的value 替代旧的value ;

当不是红黑树的时候进行链表操作,进行一个循环(p=e),一直向下循环取next 对象的Node 节点,如果next 返回空,然后进行链表 的引用;完成链表;当然了链表
也会进行判断相同key 的 value 替换;
关于红黑树,我研究好了,再讲。。。。
3.刚才说了 resize() 进行数组初始化功能,它还有进行数组扩容,在添加元素的时候当数组元素size 大于我们设定的阈值时候,就会触发 resize() 进行数组扩容;

双倍扩容;

当然,扩容完之后,并没有结束,而是又进行了散列的重组,重新计算填充数组
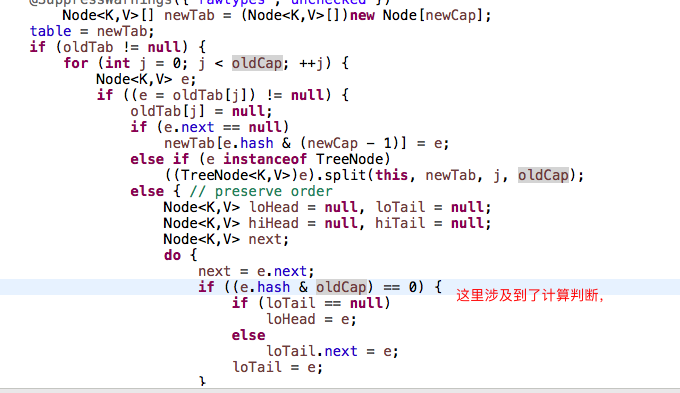
重组之后元素的位置要么在原来数组的位置,要么在【原数组索引+扩容之前数组的长度】

原理如下:需要自己去好好的想,位运算;

jdk1.8 HashMap的实现的更多相关文章
- JDK1.8 HashMap源码分析
一.HashMap概述 在JDK1.8之前,HashMap采用数组+链表实现,即使用链表处理冲突,同一hash值的节点都存储在一个链表里.但是当位于一个桶中的元素较多,即hash值相等的元素较多时 ...
- JDK1.8 HashMap$TreeNode.balanceInsertion 红黑树平衡插入
红黑树介绍 1.节点是红色或黑色. 2.根节点是黑色. 3.每个叶子节点都是黑色的空节点(NIL节点). 4 每个红色节点的两个子节点都是黑色.(从每个叶子到根的所有路径上不能有两个连续的红色节点) ...
- JDK1.8 HashMap$TreeNode.rotateLeft 红黑树左旋
红黑树介绍 1.节点是红色或黑色. 2.根节点是黑色. 3.每个叶子节点都是黑色的空节点(NIL节点). 4 每个红色节点的两个子节点都是黑色.(从每个叶子到根的所有路径上不能有两个连续的红色节点) ...
- jdk1.8 HashMap底层数据结构:深入解析为什么jdk1.8 HashMap的容量一定要是2的n次幂
前言 1.本文根据jdk1.8源码来分析HashMap的容量取值问题: 2.本文有做 jdk1.8 HashMap.resize()扩容方法的源码解析:见下文“一.3.扩容:同样需要保证扩容后的容量是 ...
- 为什么jdk1.8 HashMap的容量一定要是2的n次幂
一.jdk1.8中,对“HashMap的容量一定要是2的n次幂”做了严格控制 1.默认初始容量: [Java] 纯文本查看 复制代码 ? 1 2 3 4 /** * The default init ...
- JDK1.7 HashMap 源码分析
概述 HashMap是Java里基本的存储Key.Value的一个数据类型,了解它的内部实现,可以帮我们编写出更高效的Java代码. 本文主要分析JDK1.7中HashMap实现,JDK1.8中的Ha ...
- JDK1.8 HashMap中put源码分析
一.存储结构 在JDK1.8之前,HashMap采用桶+链表实现,本质就是采用数组+单向链表组合型的数据结构.它之所以有相当快的查询速度主要是因为它是通过计算散列码来决定存储的位置.Hash ...
- JDK1.7 HashMap 导致循环链表
转载自:疫苗:JAVA HASHMAP的死循环 在淘宝内网里看到同事发了贴说了一个CPU被100%的线上故障,并且这个事发生了很多次,原因是在Java语言在并发情况下使用HashMap造成Race C ...
- jdk1.8 HashMap红黑树操作详解-putTreeVal()
以前也看过hashMap源码不过是看的jdk1.7的,由于时间问题看的也不是太深入,只是大概的了解了一下他的基本原理:这几天通过假期的时间就对jdk1.8的hashMap深入了解了下,相信大家都是对红 ...
- jdk1.8 HashMap扩容原理详解
JDK1.7中,resize时,index取得时,全部采用重新hash的方式进行了.JDK1.8对这个进行了改善. 以前要确定index的时候用的是(e.hash & oldCap-1),是取 ...
随机推荐
- C# 比较两个路径是否指向同一对象
string path1 = @"c:\test\rootpath"; string path2 = @"C:\TEST\..\TEST\ROOTPATH"; ...
- [C#]typeof,Gettype()和is的区别
typeof 参数是一个类型名称,比如你自己编写的一个类 GetType()是类的方法,继承自object,返回该实例的类型 is 用来检测实例的兼容性(是否可以相互转换) 例: class Anim ...
- Hanlp1.7版本的新增功能一览
Hanlp1.7版本在去年下半年的时候就随大快的DKH1.6版本同时发布了,截至目前1.7大版本也更新到了1.7.1了.本篇分别就1.7.0和1.7.1中新增的功能做一个简单的汇总介绍. HanLP ...
- linq 实现对象映射
public static string GetPrintList(string data) { string[] _data = data.Split(','); string Order_No = ...
- 追求极致的用户体验ssr(基于vue的服务端渲染)
首先这篇博客并不是ssr建议教程,需要ssr入门的我建议也不要搜索博客了,因为官网给出了详细的入门步骤,只需要step by step就可以了,这篇博客的意义是如何使用ssr,可能不同的人有不同的意见 ...
- C/C++中的volatile简单描述
首先引入一篇博客: 1. 为什么用volatile? C/C++ 中的 volatile 关键字和 const 对应,用来修饰变量,通常用于建立语言级别的 memory barrier.这是 BS 在 ...
- python之路——7
王二学习python的笔记以及记录,如有雷同,那也没事,欢迎交流,wx:wyb199594 复习 1. 小数据池 int -5---256 str 特殊字符 *202. ASCII码 8位 1字节 - ...
- note 4 三大结构
程序流程图 顺序结构 选择结构 if if-else if 语句-嵌套结构(Nested) 多分支结构(Chained) if score >= 90: print 'ARM' elif sco ...
- C#操作wps、excel
比如打开表格,如下 object openEt() { ]; Type wpsAppName; string progID = "KET.Application";// " ...
- Java笔记Spring(四)
spring web项目启动入口 1.首先看一下传统Java Web的配置文件web.xml,网上找的一个,参考地址:https://blog.csdn.net/github_36301064/art ...