SolrCloud集群搭建(基于zookeeper)
1. 环境准备
1.1 三台Linux机器,x64系统
1.2 jdk1.8
1.3 Solr5.5
2. 安装zookeeper集群
2.1 分别在三台机器上创建目录
mkdir /usr/hdp/2.6.0.3-8
2.2 上传zookeeper到三台机器
使用Xshell连接三台机器,使用Xftp上传zookeeper包到2.1创建的目录下。
2.3 修改权限为755
执行命令:chmod 755 zookeeper

2.4 配置节点的data目录,通信端口及集群配置
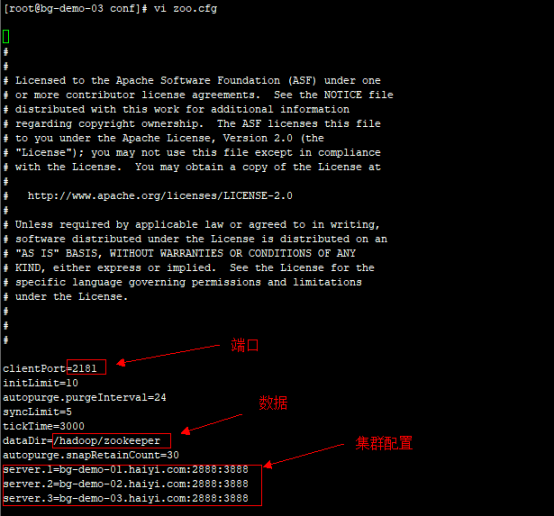
注意:三台机器配置相同,可直接拷贝!
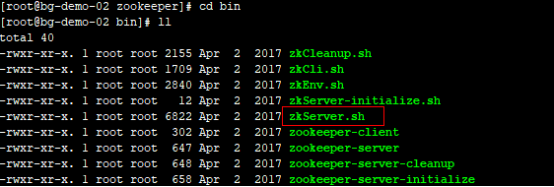
2.5 启动zookeeper集群
依次启动三个zookeeper集群节点,执行命令:./zkServer.sh start
3. 安装solrcloud集群
3.1 上传tomcat到三台机器的对应目录上

3.2 分别配置tomcat中的server.xml
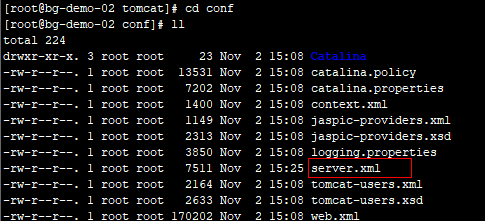
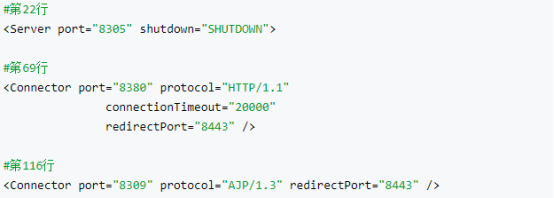
第一台机器上的tomcat:

第二台机器上的tomcat:
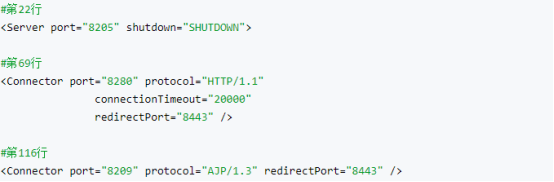
第三台机器上的tomcat:
3.3 上传solr基础文件到三台机器上的目录/usr/hdp/2.6.0.3-8/solrcloud/下,solr基础文件如下:


注意:不包含任何自定义的core!
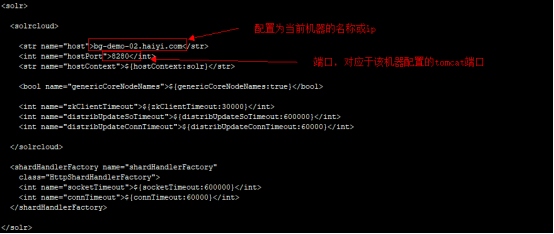
3.4 配置三台机器上的solr的solr.xml文件
3.5 指定tomcat启动solr的路径
修改三台机器上的tomcat中的web.xml文件,指定solr的路径

4. 整合solrcloud集群到zookeeper集群
4.1 配置tomcat节点关联zookeeper集群
配置三台机器上的tomcat中的catalina.sh文件,配置如下:

4.2 上传solr core配置文件到zookeeper集群

执行命令:
./zkcli.sh -zkhost
bg-demo-01.haiyi.com:2181,bg-demo-02.haiyi.com:2181,bg-demo-03.haiyi.com:2181
-cmd upconfig -confdir /usr/hdp/2.6.0.3-8/solr/server/solr/fxk_core/conf/ -confname fxk
5. 访问solrcloud集群
5.1 启动tomcat集群

依次在三台机器上执行命令:./startup.sh 启动tomcat
5.2 访问solrcloud集群
打开浏览器,输入:http://bg-demo-03.haiyi.com:8380/solr/index.html#/~cloud

表示搭建成功!
5.3 配置文件简介

6. 操作collection及shard
6.1 创建collection
执行命令:
http://bg-demo-01.haiyi.com:8180/solr/admin/collections?action=CREATE&name=fxk_collection&numShards=2&replicationFactor=2&collection.configName=fxk&maxShardsPerNode=2
6.2 删除collection
执行命令:
http://bg-demo-01.haiyi.com:8180/solr/admin/collections?action=DELETE&name=fxk
7. 创建索引

8.搜索

SolrCloud集群搭建(基于zookeeper)的更多相关文章
- solrcloud集群搭建
solrcloud 集群搭建 初始条件: 1. 三台服务器 IP 地址分别为 192.168.1.133 192.168.1.134 192.168.1.135 2. 使用 solr-5.3.1,zo ...
- JAVAEE——宜立方商城08:Zookeeper+SolrCloud集群搭建、搜索功能切换到集群版、Activemq消息队列搭建与使用
1. 学习计划 1.solr集群搭建 2.使用solrj管理solr集群 3.把搜索功能切换到集群版 4.添加商品同步索引库. a) Activemq b) 发送消息 c) 接收消息 2. 什么是So ...
- 搜索服务Solr集群搭建 使用ZooKeeper作为代理层
上篇文章搭建了zookeeper集群 那好,今天就可以搭建solr搜服服务的集群了,这个和redis 集群不同,是需要zk管理的,作为一个代理层 安装四个tomcat,修改其端口号不能冲突.8080~ ...
- Ignite集群管理——基于Zookeeper的节点发现
Ignite支持基于组播,静态IP,Zookeeper,JDBC等方式发现节点,本文主要介绍基于Zookeeper的节点发现. 环境准备,两台笔记本电脑A,B.A笔记本上使用VMware虚拟机安装了U ...
- 【集群搭建】Zookeeper集群环境配置
1.下载解压安装文件 2.配置文件:conf/zoo.cfg tickTime=2000 dataDir=/usr/sunny/logs/zookeeper/data dataLogDir=/usr/ ...
- hadoop-2.6.0-cdh5.4.5.tar.gz(CDH)的3节点集群搭建(含zookeeper集群安装)
前言 本人呕心沥血所写,经过好一段时间反复锤炼和整理修改.感谢所参考的博友们!同时,欢迎前来查阅赏脸的博友们收藏和转载,附上本人的链接 http://www.cnblogs.com/zlslch/p/ ...
- 3.Hadoop集群搭建之Zookeeper安装
前期准备 下载Zookeeper 3.4.5 若无特殊说明,则以下操作均在master节点上进行 1. 解压Zookeeper #直接解压Zookeeper压缩包 tar -zxvf zookeepe ...
- docker集群——搭建Mesos+Zookeeper+Marathon的Docker管理平台
服务器架构 机器信息: 这里部属的机器为3个Master控制节点,3个slave运行节点,其中: zookeeper.Mesos-master.marathon运行在Master端:Mesos-sla ...
- hadoop-2.4.1集群搭建及zookeeper管理
准备 1.1修改主机名,设置IP与主机名的映射 [root@xuegod74 ~]# vim /etc/hosts 192.168.1.73 xuegod73 192.168.1.74 xuegod7 ...
随机推荐
- 【BJOI2019】排兵布阵 DP
题目大意:有$n$座城堡,$s$轮游戏. 对于第$x$轮,第i座城堡的士兵数量为$a[x][i]$. 如果你需要攻下第i座城堡,你在第i座城堡部署的士兵必须严格大于$2a[x][i]$,如果攻下了你会 ...
- 21天打造分布式爬虫-requests库(二)
2.1.get请求 简单使用 import requests response = requests.get("https://www.baidu.com/") #text返回的是 ...
- android 中的Http请求类HttpUrlConnection和HttpClient类
Android系统提供了两种HTTP通信类,HttpURLConnection和HttpClient. 如何选择这两个类的使用:android-developers.blogspot.com/2011 ...
- 新电脑一般javaweb配置
下个jdk (官网)1.打开我的电脑--属性--高级--环境变量 2.新建系统变量JAVA_HOME 和CLASSPATH 变量名:JAVA_HOME 变量值:C:\Program Files\Jav ...
- 一款jq的计时器
举例子: http://files.cnblogs.com/Alandre/201201031633347950.rar
- docker 日志方案
docker logs默认会显示命令的标准输出(STDOUT)和标准错误(STDERR).下面使用echo.sh和Dockerfile创建一个名为echo.v1的镜像,echo.sh会一直输出”hel ...
- 解决Android Studio 3.x版本的安装时没有SDK,运行时出现SDK tools错误
好久没更新了,最近手机上的闹钟APP没一个好用的,所以想自己写个. 那Android开发环境搭起来,注意先装好jdk. 1.安装Android Studio google的Android开发网站已经有 ...
- jQuery链式选择器方法-导航
利用vs新建一个空白web项目, 再用nuget安装jQuery 1.x最新版,目前是 jQuery 1.12.4 新建一个html页面 再将jquery.js拖进新建的页面的头部 最后的html页面 ...
- jqGrid 翻页
比如查出来有9条数据,表格第一页显示5条,第二页显示4条 第一次查询,后台返回9条数据,但是只显示第一页的5条, 当点击下一页,会再去数据库查询,只返回第二页的4条数据, 这时候再点击回到上一页,返回 ...
- JVM参数以及用法
工作以后,发觉真的几乎没有像大学那样空闲的时间,坐下来看看书写写博客了.最近的一篇博客距离现在已经近一个多月了,最近也在复习Java的东西,准备校招,看了看JVM的东西,就当作记笔记. (一)JVM参 ...