Elastic-search在linux上的安装
今天是我装第四次 ES ,之前装好用了一段时间,后面莫名其妙爆炸了,炸出一堆异常...
安装环境:
JDK1.8 centos ElasticSearch-6.2.4
jdk1.8以上,所以安装jdk1.7及以下的朋友 可以换个jdk了
新建用户 ,如果有也可以不新建 : useradd leyouer
设置密码 : passwd leyouer
(安全考虑: ElasticSearch默认是不允许以Root帐号运行的 )
——————————————————提前处理部分异常————————————————————
在安装前的设置(有些配置的顺序没有关系,所以趁我们还在root用户下 提前修改一些配置,主要是我忘记root 用户的密码了,切换用户态挺麻烦的)
vim /etc/security/limits.conf 添加以下字段(因为允许外网访问,必须的系统调优)
* soft nofile 65536
* hard nofile 131072
* soft nproc 4096
* hard nproc 4096
vim /etc/security/limits.d/90-nproc.conf 修改 ( 解决线程不够的异常 )
* soft nproc 1024 把 1024 改成 4096
vim /etc/sysctl.conf 添加(限制一个进程可以拥有的虚拟内存的数量)
vm.max_map_count=655360
保存后执行 sysctl -p (配置生效)
——————————————————————————常规操作————————————————————————
上传安装包到 linux上
剪切重命名 : mv elasticsearch-6.2.4/ elasticsearch
进入目录 : cd ./elasticsearch/config/
给我们的用户分配权利 chown 用户名 /指定的目录 (不分配权限,后面用户启动会有异常)
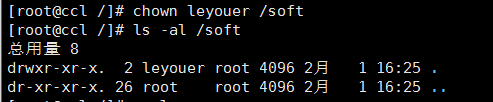
现在就可以切换到你另外的用户了 su leyouer
解压 : tar xvf elasticsearch-6.2.4.tar.gz
——————————————————————————常规配置———————————————————————
进入到解压后的目录 cd /config/ 修改一系列的配置文件
vim jvm.options ——————————修改占用内存 我虚拟机给的1G ——————————————(心急的朋友看清楚了 是第二个 这个坑我踩了)


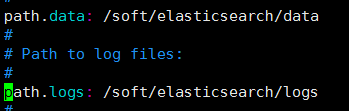
vim elasticsearch.yml——修改日志和数据目录—————————————绑定的ip———————————(异常处理) 以及禁用某个插件 ————

绑定到 0.0.0.0,允许任何ip来访问
我们指定的日志和数据的存放目录中不 data 目录是不存在的 ,data目录自己创建 mkdir data
然后你就可以启动服务了, 启动服务 是在该解压目录的 bin 目录下 ./elasticsearch
——————————可能 ( 基本是要 ) 出现的ERROR(部分已经在上面的配置中解决)——————————————
错误一 : 内核过低 (我们的linux 的内核版本低于了 我们使用的 Elasticsearch 的要求)
解决方案 : 禁用某个插件
vim elasticsearch.yml 在最后面追加一个配置 : bootstrap.system_call_filter: false
错误二 : 权限不足
解决方案 : 给我的用户 添权加力
chown -R leyouer /你的elasticsearch安装目录
我还修改了 配置文件(不知道作用覆盖没)
vim /etc/security/limits.conf
新增内容
* soft nofile 65536
* hard nofile 131072
* soft nproc 4096
* hard nproc 4096
错误三 : 外网不能访问
解决方案 : 修改配位文件 允许所有访问
vim elasticsearch.yml
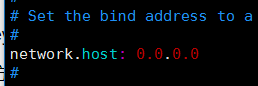
错误四:线程数不够
解决 : vim /etc/security/limits.d/90-nproc.conf
修改 * soft nproc 1024 为 * soft nproc 4096
错误五 : 未知错误
解决 ; vim /etc/sysctl.conf
新添 : vm.max_map_count=655360
保存后执行配置生效指令 : sysctl -p
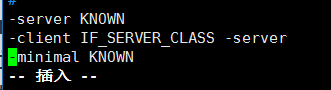
错误六 : java HotSpot Client VM 和 Java HotSpot Server VM 的配置
解决 vim [jdk安装目录]jre/lib/i386/jvm.cfg 把-server KNOWN 放在第一排 内容不做变更
错误七 : 开设端口或者关闭防火墙 端口为9200 https://www.cnblogs.com/msi-chen/p/10243832.html
错误八: java.lang.UnsatisfiedLinkError : Native library (com/sun/jna/linux-x86/libjnidispatch.so) not found in resource path......
解决 : 直接删除或重命名lib目录下面的jna文件 mv jna-4.5.1.jar jna-4.5.1.jar.bak (以bin目录的文件为准,不一定是4.5.1)
然后重新下载该文件 在lib目录内 : wget http://repo1.maven.org/maven2/net/java/dev/jna/jna/4.5.1/jna-4.5.1.jar (根据你之前看到的版本号改动)

最后你可以启动访问测试一下:
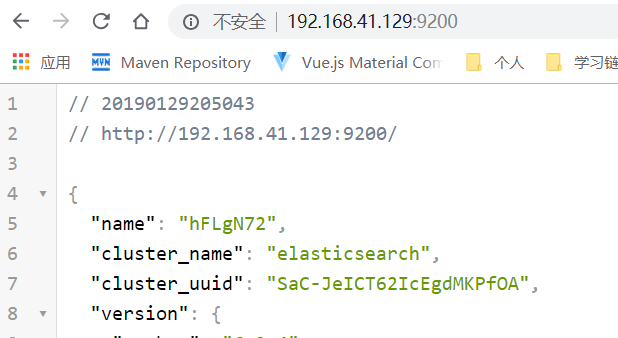
————反反复复装了三次,终于装好,朋友你不要灰心,相信有了我这篇文章,你——如鱼得水—————
Elastic-search在linux上的安装的更多相关文章
- jemalloc在linux上从安装到使用
jemalloc在linux上从安装到使用 上次在引导大家安装Redis时提到可能会报错: 发现了redis有用到jemalloc. 首先,jemalloc是干什么的? 我们看看作者自己的介绍: j ...
- 分布式缓存技术redis学习系列(一)——redis简介以及linux上的安装
redis简介 redis是NoSQL(No Only SQL,非关系型数据库)的一种,NoSQL是以Key-Value的形式存储数据.当前主流的分布式缓存技术有redis,memcached,ssd ...
- GIT在Linux上的安装和使用简介
GIT最初是由Linus Benedict Torvalds为了更有效地管理Linux内核开发而创立的分布式版本控制软件,与常用的版本控制工具如CVS.Subversion不同,它不必服务器端软件支持 ...
- 分布式缓存技术redis学习(一)——redis简介以及linux上的安装
redis简介 redis是NoSQL(No Only SQL,非关系型数据库)的一种,NoSQL是以Key-Value的形式存储数据.当前主流的分布式缓存技术有redis,memcached,ssd ...
- 在Linux上怎么安装和配置Apache Samza
samza是一个分布式的流式数据处理框架(streaming processing),它是基于Kafka消息队列来实现类实时的流式数据处理的.(准确的说,samza是通过模块化的形式来使用kafka的 ...
- ODI11G 在Linux上的安装配置
ODI11G 在Linux上的安装配置 OS环境:Red hat Linux x86_64 一.JDK安装 1. 去oracle官网上下载 http://www.oracle.com/technetw ...
- 【JAVAWEB学习笔记】27_Redis:在Linux上的安装、Jedis和常用命令
一.Redis简介 1.关于关系型数据库和nosql数据库 关系型数据库是基于关系表的数据库,最终会将数据持久化到磁盘上,而nosql数据 库是基于特殊的结构,并将数据存储到内存的数据库.从性 ...
- 【数据库】Mean web开发 04-MongoDB在Linux上的安装及遇到的问题
简介 Mean是JavaScript的全栈开发框架.更多介绍 用MongoDB实现持久数据的存储是Mean Web全栈开发中的一部分. MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非 ...
- linux上redis安装配置及其防漏洞配置及其攻击方法
Linux上redis安装: 需先在服务器上安装yum(虚拟机可使用挂载的方式安装) 安装配置所需要的环境运行指令: yum -y install gcc 进入解压文件执行make 指令进行编译 执 ...
- Nginx 在 Linux 上的安装和配置
一.Nginx的安装 1.单台Nginx的安装 Nginx在Linux上的安装可以参考这篇博客:http://blog.csdn.net/molingduzun123/article/details/ ...
随机推荐
- pyqt5.0 GraphicsView框架
场景(The Scene) QGraphicsScene提供图形视图场景.该场景具有以下职责: 提供用于管理大量图元的快速界面(锅) 将事件传播到每个图元(把螃蟹烧熟了) 管理图元状态,例如选择和焦点 ...
- ODPS SQL <for 数据操作语言DML>
基本操作: 查询: SELECT [ALL | DISTINCT] select_expr, select_expr, ... FROM table_reference [WHERE where_co ...
- 吴裕雄 python深度学习与实践(11)
import numpy as np from matplotlib import pyplot as plt A = np.array([[5],[4]]) C = np.array([[4],[6 ...
- servlet中的请求响应与重定向区别
一.概念 请求响应(转发):将客户端请求转发另一个servlet或者jsp页面------------------------getRequestDispatcher()方法 重定向: 返回一个连接给 ...
- window.innerWidth和document.body.clientWidth的区别
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 关于深度学习中的batch_size
5.4.1 关于深度学习中的batch_size 举个例子: 例如,假设您有1050个训练样本,并且您希望设置batch_size等于100.该算法从训练数据集中获取前100个样本(从第1到第100个 ...
- python爬虫小说代码,可用的
python爬虫小说代码,可用的,以笔趣阁为例子,python3.6以上,可用 作者的QQ:342290433,汉唐自远工程师 import requests import refrom lxml i ...
- I/O系统(一)
输入输出系统的发展大致可以分为4个阶段1.早期阶段 特点: 1.1每个IO设备都得有一套独立的逻辑电路和CPU相连. 1.2输入输出过程需要通过CPU,穿插在程序运行的过程中,处理IO时候 ...
- ATM取款机数据库设计
创建文件夹 USE master GO EXEC xp_cmdshell 'mkdir d:\bank', NO_OUTPUT 建库 --检验数据库是否存在,如果为真,删除此数据库-- ...
- python脚本批量复制文件
1.拷贝一个目录下的所有文件及文件夹到另一个目录下(递归拷贝) # cat /home/test.py #!/usr/bin/python import os import shutil def ...