Kafka+Log4j2日志
默认你已经安装配置了Zookeeper和Kafka。
为了目录清晰,我的Kafka配置文件的Zookeeper部分是:加上了节点用来存放Kafka信息
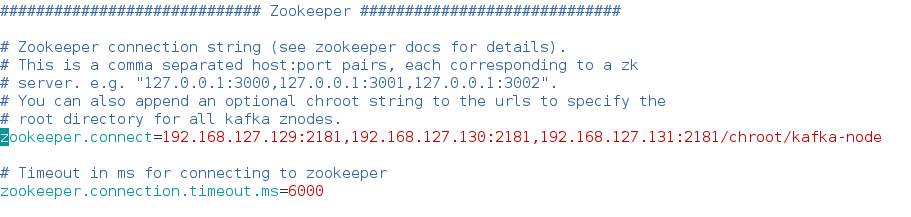
启动Zookeeper,然后启动Kafka。
Zookeeper的节点树:根目录下有专门的Kafka存放节点【以前没有配这个,结果Kafka的一大堆东西全部跑到根节点上了,很乱】
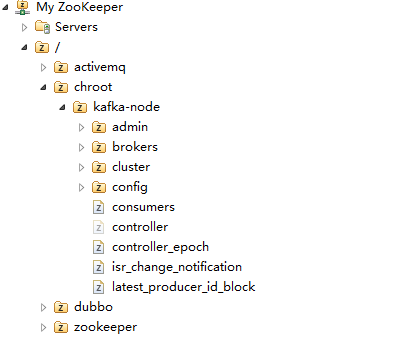
接下来是代码部分了。
依赖包:
Log4j2配置文件:
<?xml version="1.0" encoding="UTF-8"?>
<Configuration monitorInterval="1800"> <Filter type="ThresholdFilter" level="trace" /> <Appenders>
<Console name="console" target="SYSTEM_OUT">
<!--控制台只输出level及以上级别的信息(onMatch),其他的直接拒绝(onMismatch) -->
<ThresholdFilter level="trace" onMatch="ACCEPT"
onMismatch="DENY" />
<PatternLayout pattern="%d %-5p [%t] %C{2} (%F:%L) - %m%n" />
</Console> <Kafka name="Kafka" topic="my-topic" syncSend="false">
<PatternLayout pattern="%date %message" />
<Property name="bootstrap.servers">192.168.127.129:9092,192.168.127.130:9092,192.168.127.131:9092</Property>
</Kafka>
</Appenders>
<Loggers>
<Root level="WARN">
<!-- TRACE < DEBUG < INFO < WARN < ERROR < FATAL -->
<AppenderRef ref="console" />
</Root>
<Logger name="kafkaLog" level="trace">
<AppenderRef ref="Kafka" />
</Logger>
</Loggers>
</Configuration>
生产者:
package learn.kafka.log4j; import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger; public class SimpleProducer { private static Logger log = LogManager.getLogger("kafkaLog"); public static void main(String[] args) {
for (int i = 10; i < 20; i++) {
log.info("Hello---" + i);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
} }
消费者:
package learn.kafka.log4j; import java.util.Arrays;
import java.util.Properties; import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer; public class SimpleConsumer { public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.127.129:9092,192.168.127.130:9092,192.168.127.131:9092");
props.put("group.id", "testGroup");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
//订阅的topic,多个用逗号隔开
consumer.subscribe(Arrays.asList("my-topic"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
//consumer.close();
}
}
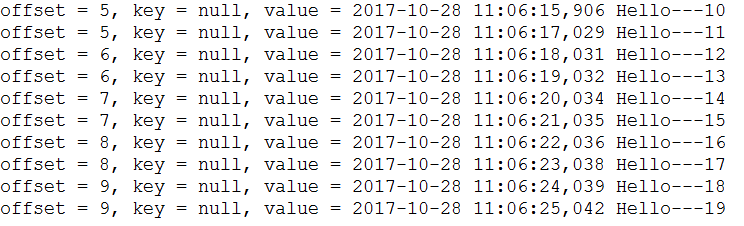
先运行消费者,让它监听等待。
在运行生产者,让它生产消息。
你会发现每隔一秒输出一行信息。信息在value后面。

Kafka+Log4j2日志的更多相关文章
- 基于Flume+LOG4J+Kafka的日志采集架构方案
本文将会介绍如何使用 Flume.log4j.Kafka进行规范的日志采集. Flume 基本概念 Flume是一个完善.强大的日志采集工具,关于它的配置,在网上有很多现成的例子和资料,这里仅做简单说 ...
- 【转】flume+kafka+zookeeper 日志收集平台的搭建
from:https://my.oschina.net/jastme/blog/600573 flume+kafka+zookeeper 日志收集平台的搭建 收藏 jastme 发表于 10个月前 阅 ...
- ELK+kafka构建日志收集系统
ELK+kafka构建日志收集系统 原文 http://lx.wxqrcode.com/index.php/post/101.html 背景: 最近线上上了ELK,但是只用了一台Redis在 ...
- spring boot自定义log4j2日志文件
背景:因为从 spring boot 1.4开始的版本就要用log4j2 了,支持的格式有json和xml两种格式,此次实践主要使用的是xml的格式定义日志说明. spring boot 1.5.8. ...
- JavaWeb项目架构之Kafka分布式日志队列
架构.分布式.日志队列,标题自己都看着唬人,其实就是一个日志收集的功能,只不过中间加了一个Kafka做消息队列罢了. kafka介绍 Kafka是由Apache软件基金会开发的一个开源流处理平台,由S ...
- 【kafka学习之五】kafka运维:kafka操作日志设置和主题删除
一.操作日志 首先附上kafka 操作日志配置文件:log4j.properties 根据相应的需要设置日志. #日志级别覆盖规则 优先级:ALL < DEBUG < INFO <W ...
- Log4j2 日志级别
Log4j2日志级别 级别 在log4j2中, 共有8个级别,按照从低到高为:ALL < TRACE < DEBUG < INFO < WARN < ERROR < ...
- ELK+Kafka 企业日志收集平台(一)
背景: 最近线上上了ELK,但是只用了一台Redis在中间作为消息队列,以减轻前端es集群的压力,Redis的集群解决方案暂时没有接触过,并且Redis作为消息队列并不是它的强项:所以最近将Redis ...
- Spring Boot Log4j2 日志学习
简介 Java 中比较常用的日志工具类,有: Log4j. SLF4j. Commons-logging(简称jcl). Logback. Log4j2(Log4j 升级版). Jdk Logging ...
随机推荐
- OC与JS的交互(iOS与H5混编)
大神总结WKWebView的坑:https://mp.weixin.qq.com/s/rhYKLIbXOsUJC_n6dt9UfA 在开发过程中,经常会出现需要iOS移动端与H5混编的使用场景. iO ...
- [BUAA软工]第一次博客作业---阅读《构建之法》
[BUAA软工]第一次博客作业 项目 内容 这个作业属于哪个课程 北航软工 这个作业的要求在哪里 第1次个人作业 我在这个课程的目标是 学习如何以团队的形式开发软件,提升个人软件开发能力 这个作业在哪 ...
- java-过滤器、拦截器
1.基础知识 1.1面向对象编程(OOP).面向切面编程(AOP) 面向对象编程: 将需求功能划分为不同的.相对独立的和封装良好的类,使他们有属于自己的行为,依靠继承和多态等来定义彼此的关系. 面向切 ...
- 第三个Sprint冲刺第4天
成员:罗凯旋.罗林杰.吴伟锋.黎文衷 讨论内容:各成员汇报各自完成的情况.
- Spring整合SpringMVC
整合:把在springMVC配置文件中的spring提取出来整合为另一份配置文件 希望: 1).Spring的配置文件只是用来配置和业务逻辑有关的功能(数据源.事务控制.切面....) 2).Spri ...
- hadoop伪分布式安装之Linux环境准备
Hadoop伪分布式安装之Linux环境准备 一.软件版本 VMare Workstation Pro 14 CentOS 7 32/64位 二.实现Linux服务器联网功能 网络适配器双击选择VMn ...
- shell脚本--cut命令与awk简单使用
cut:对内容进行列切割 -d 后面的是分割符,表示用什么符号来分割符来分割列,分隔符使用引号括起来: -f后面跟着要选择的字段列,从1开始,表示第一列,如果要多列,可以用逗号分隔 : -c参数后面跟 ...
- prettier & codes format
prettier & codes format https://prettier.io/playground/ https://github.com/collections/front-end ...
- 在property里面设置版本号可灵活引用
- __add__运行过程