sqlserver 常用语法
sqlserver查找 table, view, column
select * from information_schema.tables where table_schema='bk'
select * from information_schema.views where table_schema='bk'
select * from information_schema.columns where column_name like '%name'
-- 查询包含某个列名的表
select * from INFORMATION_SCHEMA.COLUMNS where COLUMN_NAME like '%ColumnName%'
-- 查询包含某个基础表的视图
select * from INFORMATION_SCHEMA.VIEWS where VIEW_DEFINITION like '%TableName%'
sqlserver删除语法
-- 1. drop table
IF EXISTS (SELECT 1 FROM sysobjects WHERE id = object_id('__TableName__') AND type = 'U' )
DROP TABLE __TableName__; -- 2. drop view
if exists (select * from dbo.sysobjects where id = object_id(N'__ViewName__') and objectproperty(id, N'isview') = 1)
drop view __ViewName__; -- 3. drop proc
IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'__ProcName__') AND type in (N'P', N'PC'))
DROP PROCEDURE __ProcName__; IF OBJECT_ID('__ProcName__','P') IS NOT NULL
DROP PROC __ProcName__ -- 4. drop columns
IF EXISTS(SELECT * FROM INFORMATION_SCHEMA.COLUMNS WHERE TABLE_SCHEMA='dbo' AND TABLE_NAME = '__TableName__' AND COLUMN_NAME = '__ColumnName__')
alter table __TableName__ DROP COLUMN __ColumnName__; IF EXISTS (SELECT * FROM syscolumns WHERE id=object_id('__TableName__') AND name='__ColumnName__')
EXEC('ALTER TABLE __TableName__ DROP COLUMN __ColumnName__') -- 5. drop constraints
DECLARE @ConstraintName nvarchar(200)
SELECT @ConstraintName = Name FROM SYS.DEFAULT_CONSTRAINTS WHERE PARENT_OBJECT_ID = OBJECT_ID('__TableName__') AND PARENT_COLUMN_ID = (SELECT column_id FROM sys.columns WHERE NAME = N'__ColumnName__' AND object_id = OBJECT_ID(N'__TableName__'))
IF @ConstraintName IS NOT NULL
EXEC('ALTER TABLE __TableName__ DROP CONSTRAINT ' + @ConstraintName) -- 6. drop PK or FK
IF EXISTS(SELECT 1 FROM INFORMATION_SCHEMA.CONSTRAINT_COLUMN_USAGE where TABLE_NAME = '__TableName__' AND COLUMN_NAME = '__ColumnName__')
BEGIN
SELECT @ConstraintName = CONSTRAINT_NAME FROM INFORMATION_SCHEMA.CONSTRAINT_COLUMN_USAGE where TABLE_NAME = '__TableName__' AND COLUMN_NAME = '__ColumnName__'
EXEC('ALTER TABLE __TableName__ DROP CONSTRAINT ' + @ConstraintName)
END
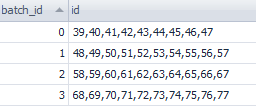
计算每批次的id集合
with ws_ids as(
SELECT ROW_NUMBER() OVER(ORDER BY w.id) / 10 batch_id, w.id
FROM dbo.[webservice] w WHERE validationStatus = 'INIT'
)
SELECT batch_id, id = stuff( SELECT ',' + cast(id AS VARCHAR(20)) FROM ws_ids t
WHERE t.batch_id = a.batch_id FOR XML path(''), 1, 1, '')
FROM ws_ids a
批量更新(多表连接,使用临时表)
IF EXISTS (SELECT 1 FROM sysobjects WHERE id = object_id('dbo.month_sale') AND type = 'U')
DROP TABLE dbo.month_sale;
GO
CREATE TABLE dbo.month_sale
(
seller_name varchar(50) not null,
month_amount decimal(24, 8) not null,
PRIMARY KEY(seller_name, amount)
)
IF OBJECT_ID('[dbo].[calc_month_sale]','P') IS NOT NULL
DROP PROC [dbo].[calc_month_sale];
GO
CREATE PROCEDURE [dbo].[calc_month_sale]
@month int
AS
BEGIN
SET NOCOUNT ON
TRUNCATE TABLE dbo.month_sale
CREATE TABLE #seller_month_amount(
seller_id int identity(1,1) not null,
month_amount datetime not null,
PRIMARY KEY(seller_id, month_amount)
)
INSERT #seller_month_amount(seller_id, month_amount)
SELECT seller_id, sum(amount)
FROM [dbo].[order]
WHERE month(ordered_date)=@month
GROUP BY seller_id
INSERT month_sale(seller_name, month_amount)
SELECT s.seller_name, sma.month_amount
FROM [dbo].[seller] s
INNER JOIN #seller_month_amount sma
ON s.seller_id = sma.seller_id
UPDATE sh SET month_amount = ms.month_amount
FROM dbo.sale_history sh
INNER JOIN [dbo].[month_sale] ms
ON s.seller_id = sma.seller_id
END
;
exec [dbo].[calc_month_sale]
批量插入
set rowcount 10000000
declare @looper int = 10000000
declare @current_time datetime while @looper = 10000000
begin select @current_time = getdate()
insert into table1 select * from table2
select @looper = @@rowcount
insert into batch_log values ('table1', @looper, @current_time, getdate()) end
查询replicated tables
-- 1. find publisher and subscriber
SELECT DISTINCT
srv.srvname publication_server
, a.publisher_db
, p.publication + '.' + a.article publication_object
, ss.srvname subscriber_server
, s.subscriber_db
, a.destination_object
--, da.name AS distribution_agent_job_name
FROM [distribution].[dbo].MSArticles a
JOIN [distribution].[dbo].MSpublications p ON a.publication_id = p.publication_id
JOIN [distribution].[dbo].MSsubscriptions s ON p.publication_id = s.publication_id
JOIN master..sysservers ss ON s.subscriber_id = ss.srvid
JOIN master..sysservers srv ON srv.srvid = p.publisher_id
--JOIN [distribution].[dbo].MSdistribution_agents da ON da.publisher_id = p.publisher_id
-- AND da.subscriber_id = s.subscriber_id
ORDER BY 1,2,3 -- 2. find replicated tables
SELECT
P.[publication] AS [Publication Name]
,A.[publisher_db] AS [Database Name]
,A.[article] AS [Article Name]
,A.[source_owner] AS [Schema]
,A.[source_object] AS [Object]
FROM
[distribution].[dbo].[MSarticles] AS A
INNER JOIN [distribution].[dbo].[MSpublications] AS P
ON (A.[publication_id] = P.[publication_id])
ORDER BY
P.[publication], A.[article]; -- 3. Publisher
select t.name
from sys.tables t
where is_published = 1 -- Subscriber
select t.name
from [SERVERNAME].[REPLICATED_DATABASE].sys.tables t
where is_ms_shipped = 0;
查找所有索引
select s.name as schemaName, t.name as tableName, i.name as indexName
from sys.tables t
inner join sys.schemas s on t.schema_id = s.schema_id
inner join sys.indexes i on i.object_id = t.object_id
where i.index_id > 0
and i.type in (1, 2)
and i.is_primary_key = 0
and i.is_unique_constraint = 0
查看索引详情
SELECT
schema_name(schema_id) as SchemaName, OBJECT_NAME(si.object_id) as TableName, si.name as IndexName,
(CASE is_primary_key WHEN 1 THEN 'PK' ELSE 'index' END) as indexType,
(CASE is_unique WHEN 1 THEN '' ELSE '' END)+' '+
(CASE si.type WHEN 1 THEN 'C' WHEN 3 THEN 'X' ELSE 'B' END)+' '+ -- B=basic, C=Clustered, X=XML
(CASE INDEXKEY_PROPERTY(si.object_id,index_id,1,'IsDescending') WHEN 0 THEN 'A' WHEN 1 THEN 'D' ELSE '' END)+
(CASE INDEXKEY_PROPERTY(si.object_id,index_id,2,'IsDescending') WHEN 0 THEN 'A' WHEN 1 THEN 'D' ELSE '' END)+
(CASE INDEXKEY_PROPERTY(si.object_id,index_id,3,'IsDescending') WHEN 0 THEN 'A' WHEN 1 THEN 'D' ELSE '' END)+
(CASE INDEXKEY_PROPERTY(si.object_id,index_id,4,'IsDescending') WHEN 0 THEN 'A' WHEN 1 THEN 'D' ELSE '' END)+
(CASE INDEXKEY_PROPERTY(si.object_id,index_id,5,'IsDescending') WHEN 0 THEN 'A' WHEN 1 THEN 'D' ELSE '' END)+
(CASE INDEXKEY_PROPERTY(si.object_id,index_id,6,'IsDescending') WHEN 0 THEN 'A' WHEN 1 THEN 'D' ELSE '' END)+
(CASE INDEXKEY_PROPERTY(si.object_id,index_id,7,'IsDescending') WHEN 0 THEN 'A' WHEN 1 THEN 'D' ELSE '' END)+
(CASE INDEXKEY_PROPERTY(si.object_id,index_id,8,'IsDescending') WHEN 0 THEN 'A' WHEN 1 THEN 'D' ELSE '' END)+
'' as 'Type',
INDEX_COL(schema_name(schema_id)+'.'+OBJECT_NAME(si.object_id),index_id,1) as Key1,
INDEX_COL(schema_name(schema_id)+'.'+OBJECT_NAME(si.object_id),index_id,2) as Key2,
INDEX_COL(schema_name(schema_id)+'.'+OBJECT_NAME(si.object_id),index_id,3) as Key3,
INDEX_COL(schema_name(schema_id)+'.'+OBJECT_NAME(si.object_id),index_id,4) as Key4,
INDEX_COL(schema_name(schema_id)+'.'+OBJECT_NAME(si.object_id),index_id,5) as Key5,
INDEX_COL(schema_name(schema_id)+'.'+OBJECT_NAME(si.object_id),index_id,6) as Key6,
INDEX_COL(schema_name(schema_id)+'.'+OBJECT_NAME(si.object_id),index_id,7) as Key7,
INDEX_COL(schema_name(schema_id)+'.'+OBJECT_NAME(si.object_id),index_id,8) as Key8
FROM sys.indexes as si
LEFT JOIN sys.objects as so on so.object_id=si.object_id
WHERE index_id>0 -- omit the default heap
and OBJECTPROPERTY(si.object_id,'IsMsShipped')=0 -- omit system tables
--and not (schema_name(schema_id)='dbo' and OBJECT_NAME(si.object_id)='sysdiagrams') -- omit sysdiagrams
and schema_name(schema_id)='fdp_cvs' -- and OBJECT_NAME(si.object_id) ='fdp_cvs'
ORDER BY SchemaName,TableName,IndexName
sqlserver日期函数
DATEADD(datepart,number,date)
DATEDIFF(datepart,startdate,enddate)
DATEPART(datepart,date) select getdate() -- 当前日期 8/15/2017 3:21:45 AM
select dateadd(m, 0, 0) -- 时间起点 1/1/1900 12:00:00 AM
select dateadd(m, datediff(m,0,getdate())-2, 0) -- 当前季度的第一天 6/1/2017 12:00:00 AM
select dateadd(m, datediff(m,0,getdate())-11, 0)-- 一年前当月的第一天 9/1/2016 12:00:00 AM
select dateadd(d, 1, dateadd(q,-1,getdate())) -- 一季度前的起始日期 5/16/2017 3:21:45 AM
select dateadd(d, 2, dateadd(y,-1,getdate())) -- 一年前的起始日期 8/16/2017 3:21:45 AM select CONVERT(datetime,CONVERT(char(8),getdate(),120)+'') -- 该月第一天 8/1/2017 12:00:00 AM
select CONVERT(char(5), getdate(),120)+'1-1' -- 年的第一天
select CONVERT(char(5), getdate(),120)+'12-31' -- 年的最后一天 select 年份=year(getdate()),月份=month(getdate())
select 年份=datepart(year,getdate()),月份=datepart(month,getdate())
创建数据库快照
NAME: snapshot文件的逻辑名称,FILENAME: snapshot文件的存放位置
CREATE DATABASE AdventureWorks_dbss1800 ON
( NAME = AdventureWorks_Data, FILENAME =
'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\Data\AdventureWorks_data_1800.ss' )
AS SNAPSHOT OF AdventureWorks;
GO
sqlserver 常用语法的更多相关文章
- sqlserver常用语法
--临时表 IF OBJECT_ID('tempdb..#Entry') is not null BEGIN DROP TABLE #Entry END ------------------- ...
- SqlServer常用语法总结
前言 近期公司做一个短信平台,写了一些关于统计方面的存储过程,今天刚好有空总结一下. 统计查询和性能提升 一.使用WITH AS提高性能简化嵌套SQL 首先,感谢@飞洋过海和@宋沄剑,通过阅读他们的博 ...
- Markdown通用的常用语法说明
前言 Markdown 是一种轻量级的 标记语言,语法简洁明了.学习容易,还具有其他很多优点,目前被越来越多的人用来写作使用. Markdown具有一系列衍生版本,用于扩展Markdown的功能(如表 ...
- Markdown简介以及常用语法
Markdown简介以及常用语法 最近发现用markdown记录东西很方便,感觉和emacs的org mode很类似,但是windows下使用emacs不是很方便.特此记录一下markdown常用的语 ...
- Sql常用语法以及名词解释
Sql常用语法以及名词解释 SQL分类: DDL—数据定义语言(CREATE,ALTER,DROP,DECLARE) DML—数据操纵语言(SELECT,DELETE,UPDATE,INSERT) D ...
- Markdown常用语法
什么是Markdown Markdown 是一种方便记忆.书写的纯文本标记语言,用户可以使用这些标记符号以最小的输入代价生成极富表现力的文档. 通过Markdown简单的语法,就可以使普通文本内容具有 ...
- 2 hive的使用 + hive的常用语法
本博文的主要内容有: .hive的常用语法 .内部表 .外部表 .内部表,被drop掉,会发生什么? .外部表,被drop掉,会发生什么? .内部表和外部表的,保存的路径在哪? .用于创建一些临时表存 ...
- sql 常用语法汇总
Sql常用语法 SQL分类: DDL—数据定义语言(CREATE,ALTER,DROP,DECLARE) DML—数据操纵语言(SELECT,DELETE,UPDATE,INSERT) DCL—数据控 ...
- ylb:SQLServer常用系统函数-字符串函数、配置函数、系统统计函数
原文:ylb:SQLServer常用系统函数-字符串函数.配置函数.系统统计函数 ylbtech-SQL Server:SQL Server-SQLServer常用系统函数 -- ========== ...
随机推荐
- day17 12.复习
最后能抽取成word文档或者是图片之类的. 1.jdbc介绍 jdbc是一套标准,可以让我们Java程序员通过Java代码直接操作数据库,这就够了.jdbc涉及到的包两个:java.sql,java ...
- Eclipse报错could not write metadata for '/remotesystemstempfiles'
1. windows-Preferences 中,在search中输入remote,取消选中reopen remote systems view to previous state'. 2. win ...
- jQuery AJAX 函数
jQuery 拥有供 AJAX 开发的丰富函数(方法)库. 什么是 AJAX? AJAX = Asynchronous JavaScript and XML. AJAX 是一种创建快速动态网页的技术. ...
- SpringMvc配置web.xml避免view被dispatcherServlet拦截
在我们以SpringMvc作为开发框架,开发接口框架时,我们只用到Controller一层,因为数据是交到前端处理的,所以我们是不需要处理视图的.此时,在配置dispatcherServlet时,一般 ...
- windows脚本设置网络IP地址
需求描述 不通的网络环境下,可能需要设置静态IP地址,或设置为动态获取,每次重复手动的配置费时费力,通过脚本可以实现一键设置 脚本实现 1.设置静态IP 1.1新建文本文档,复制粘贴如下内容 nets ...
- 重建freescale 4.6.2 multilib toolchain
patch和crosstool-ng 可以从下面的网址下载, https://community.freescale.com/thread/386450 不过估计你会失望的,改了脚本,编译了后发现不对 ...
- WinForm 生命周期, WinForm 事件执行顺序
1.窗体启动: Control.HandleCreatedControl.BindingContextChangedForm.LoadControl.VisibleChangedForm.Activa ...
- 前端基础:call,apply,bind的的理解
背景 前两天在做小程序的需求的时候用到bind的时候才想起自己对这三的东西的了解比较浅薄,这个时候用的时候就有点怕.时候还是要好好学习下,理解下怎么玩. 正文 先说call 和 apply吧:ECMA ...
- P5212 SubString LCT+SAM
$ \color{#0066ff}{ 题目描述 }$ 给定一个字符串init,要求支持两个操作 在当前字符串的后面插入一个字符串 询问字符串ss在当前字符串中出现了几次?(作为连续子串) 强制在线. ...
- 在线作图工具 Flowchart Maker & Online Diagram Software & Visual Solution
9款国内外垂直领域的在线作图工具:那些可以替代Visio的应用!-CSDN.NEThttps://www.csdn.net/article/2015-02-12/2823939 Documentsht ...