解析ASPX网页__doPostBack分页的网页table数据
由于急于上线的功能要去客服系统里抓取数据进行验证,客服方面又没有时间开发EDI接口给到我,所以用了本办法:爬人家web系统上的数据进行分析。
由于客服的web系统用ASP.Net的__doPostBack控件进行数据分页。__doPostBack是通过__EVENTTARGET,__EVENTARGUMENT两个隐藏控件向服务端发送控制信息的。
这里我要分析的页面概况如下:
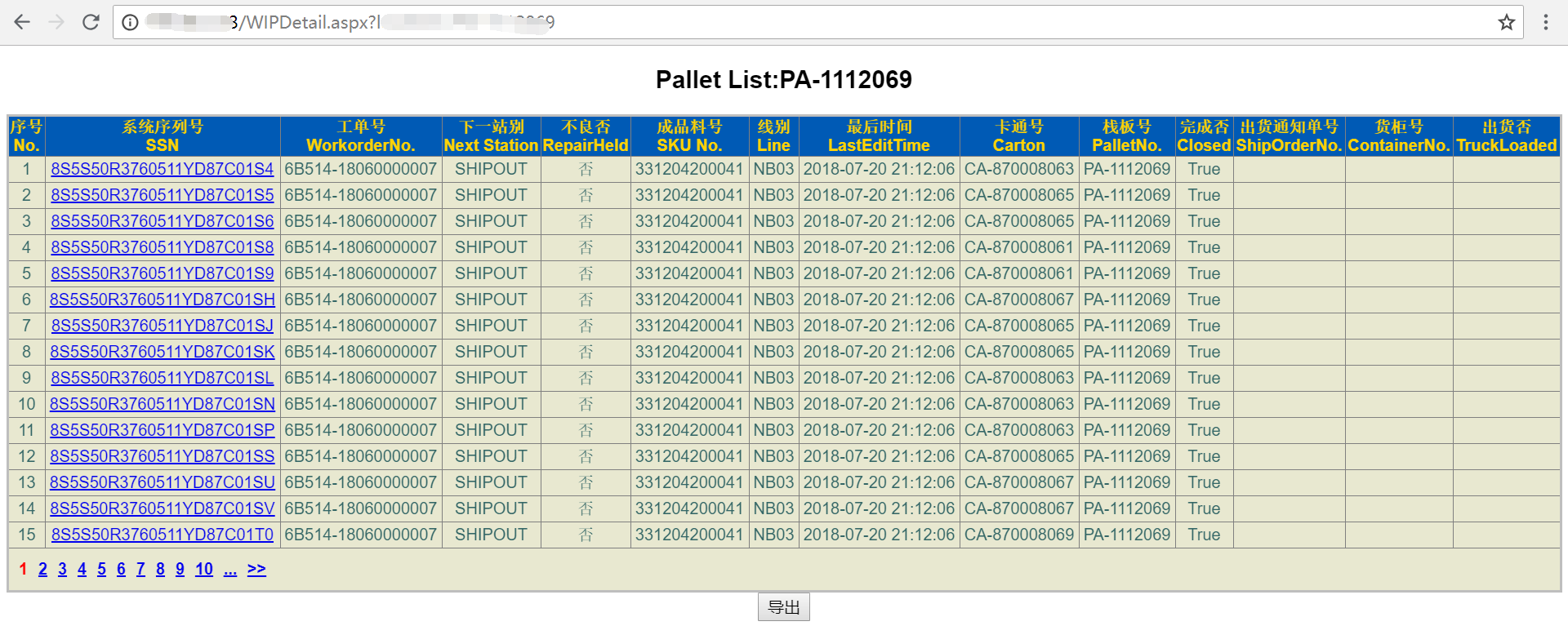
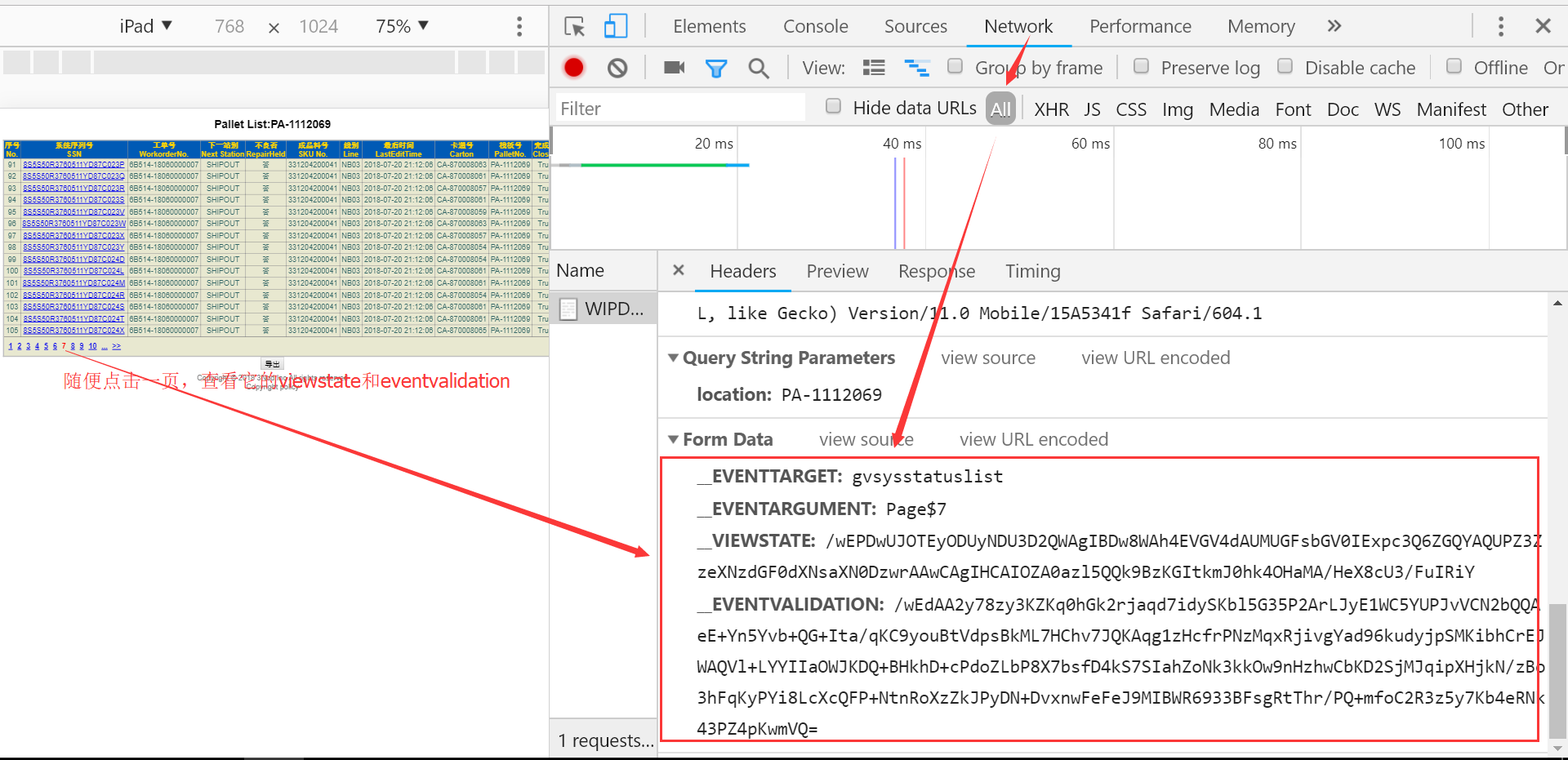
这里有个导出按钮,直接模拟导出按钮获取数据。模拟点击页面来获取我们要解析需要的参数:__VIEWSTATE、__EVENTVALIDATION
设计一个demo
private void button1_Click(object sender, EventArgs e)
{
string strViewState = System.Web.HttpUtility.UrlEncode("/wEPDwUJOTEyODUyNDU3D2QWAgIBDw8WAh4EVGV4dAUMUGFsbGV0IExpc3Q6ZGQYAQUPZ3ZzeXNzdGF0dXNsaXN0DzwrAAwBCAIOZOMeKZkMrWymOLPLpoGaeUA09JXcMmBeiapHUaN/Gi/F");
string strEventValidation = System.Web.HttpUtility.UrlEncode("/wEdAA0xoT8jJS8wSLBSnnngxJ11LlhQ8m9UI3ZtBAB4T5ifli9v5Ab4i1r+ooL3Ki4G1V2mwGQwvscKG/slAoCqDXMdx+s83MyrFGOK+Bhp33qS53KOlIwqJuEKsQlYBBWX4thggho5YkoND4EeSEP5w92hCXHcK3jw5s4JUgUUp9F6PJLbP8X7bsfD4kS7SIahZoNk3kkOw9nHzhwCbKD2SjMJqipXHjkN/zBo3hFqKyPYi8LcXcQFP+NtnRoXzZkJPyDN+DvxnwFeFeJ9MIBWR693WMHe4rn0nQ4UPheoLGOgfsnsDvJMKKjfZWVoPlnQzPA=");
StringBuilder url = new StringBuilder();
url.Append("&__VIEWSTATE=" + strViewState);
url.Append("&__EVENTVALIDATION=" + strEventValidation);
url.Append("&Button1=导出");
byte[] data = System.Text.Encoding.ASCII.GetBytes(url.ToString());
Uri uri = new Uri(textBox1.Text.ToString());
System.Net.HttpWebRequest request = (System.Net.HttpWebRequest)System.Net.WebRequest.Create(uri);
request.Method = "post";
request.ContentType = "application/x-www-form-urlencoded";
//request.ContentType = "application/json";
request.ContentLength = data.Length;
Stream requestStream = request.GetRequestStream();
requestStream.Write(data, , data.Length);
requestStream.Close();
System.Net.HttpWebResponse response = (System.Net.HttpWebResponse)request.GetResponse();
Stream responseStream = response.GetResponseStream();
StreamReader readStream = new StreamReader(responseStream, System.Text.Encoding.Default);
string html = readStream.ReadToEnd().ToString();
readStream.Close();
var strReg = @"<table[^>]*>[\s\S]*</table>";
List<string> result = new List<string>();
MatchCollection mc = Regex.Matches(html, strReg);
DataTable dt = new DataTable();
dt.Columns.Add("ID", typeof(string)); //序号
dt.Columns.Add("SN", typeof(string)); //系统序列号
dt.Columns.Add("WO", typeof(string)); //工单号
dt.Columns.Add("NextStation", typeof(string)); //下一站别
dt.Columns.Add("RepairHeld", typeof(string)); //不良否
dt.Columns.Add("SKUNo", typeof(string)); //成品料号
dt.Columns.Add("Line", typeof(string)); //线别
dt.Columns.Add("LastEditTime", typeof(string)); //最后时间
dt.Columns.Add("Carton", typeof(string)); //卡通号
dt.Columns.Add("PalletNo", typeof(string)); //栈板号
dt.Columns.Add("Closed", typeof(string)); //完成否
dt.Columns.Add("ShipOrderNo", typeof(string)); //出货通知单号
dt.Columns.Add("ContainerNo", typeof(string)); //货柜号
dt.Columns.Add("TruckLoaded", typeof(string)); //出货否
string strhead = string.Empty;
Match m = mc[];
int rowindex = ;
foreach (Match mtr in Regex.Matches(m.Value, "(?is)(?<=<tr>).+?(?=</tr>)"))
{
if (rowindex == ) { rowindex++; continue; }
DataRow dr = dt.NewRow();
MatchCollection tds = Regex.Matches(mtr.Value, "(?is)(?<=<td>).+?(?=</td>)");
MatchCollection tds2 = Regex.Matches(mtr.Value, "(?is)(?<=target=\"_blank\">).+?(?=</a></td>)");
MatchCollection tds6 = Regex.Matches(mtr.Value, "(?is)(?<=@\">).+?(?=</td>)");
MatchCollection ids = Regex.Matches(tds[].Value, "(?is)(?<=\">).+?(?=</span>)");
dr["ID"] = FormatString(ids[].Value);
dr["SN"] = FormatString(tds2[].Value);
dr["WO"] = FormatString(tds[].Value);
dr["NextStation"] = FormatString(tds[].Value);
dr["RepairHeld"] = FormatString(tds[].Value);
dr["SKUNo"] = FormatString(tds6[].Value);
dr["Line"] = FormatString(tds[].Value);
dr["LastEditTime"] = FormatString(tds[].Value);
dr["Carton"] = FormatString(tds[].Value);
dr["PalletNo"] = FormatString(tds[].Value);
dr["Closed"] = FormatString(tds[].Value);
dr["ShipOrderNo"] = FormatString(tds[].Value);
dr["ContainerNo"] = FormatString(tds[].Value);
dr["TruckLoaded"] = FormatString(tds[].Value);
dt.Rows.Add(dr);
rowindex++;
}
gridControl1.DataSource = dt;
}
/// <summary>
/// 页面加载
/// </summary>
/// <param name="sender"></param>
/// <param name="e"></param>
private void Form1_Load(object sender, EventArgs e)
{
this.textBox1.Text = @"http://172.16.1.13/WIPDetail.aspx?location=PA-1112069";
}
private string FormatString(string str)
{
str = str.Replace("\r\n", "").Replace(" ", "").Trim();
return str;
}
正则表达式分析解析出来的HTML文本即可。
其实针对上述既要分页又是隐藏控件分页的table不太好爬数据,如果解析不分页的table的话没那么复杂,可以直接获取整个页面的html元素然后进行解析
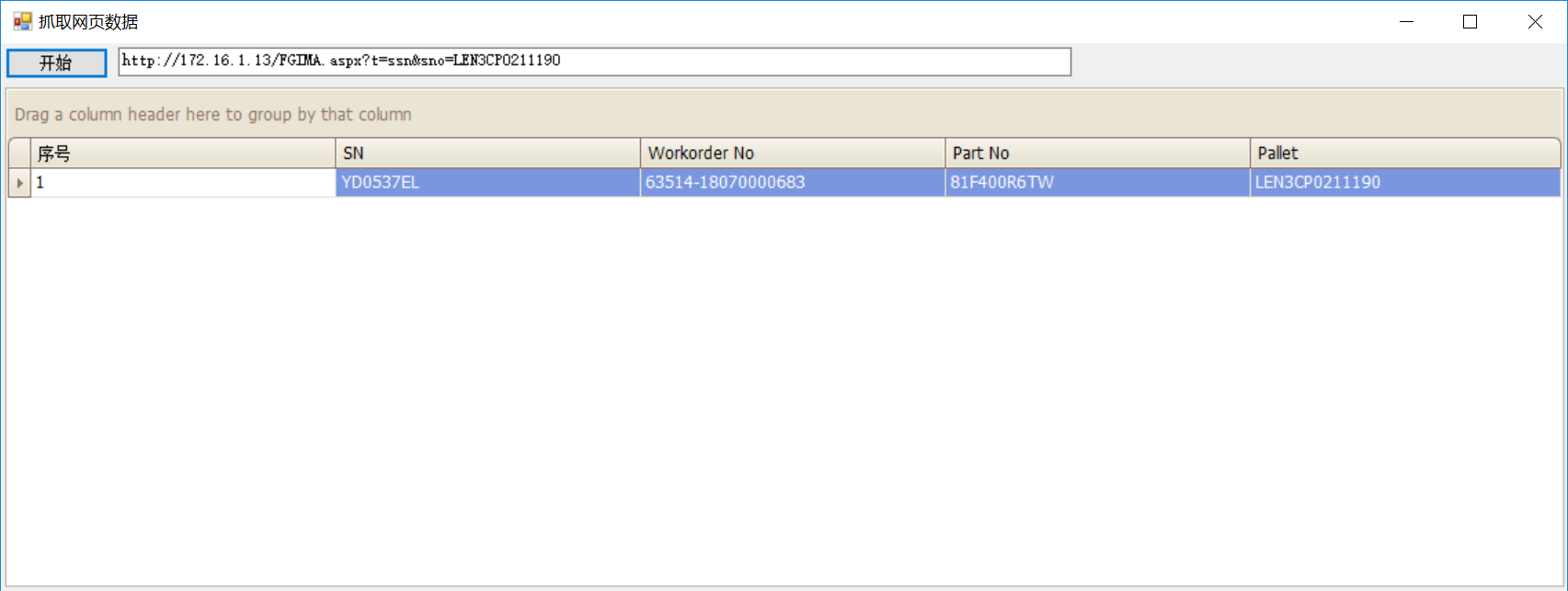
列如我需要知道如下页面的table表里面的数据:
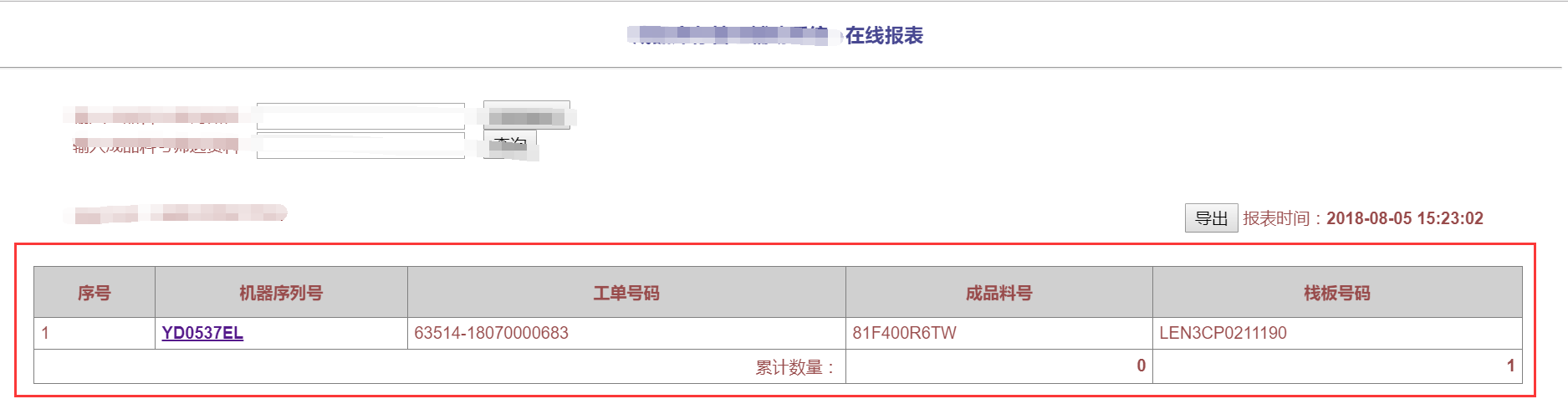
首先根据URL,WebRequest请求该页面,IO流读取整个页面的HTML元素,首先正则定位table,然后遍历这些元素,按照<tr>,<th>解析
WebRequest request = WebRequest.Create("http://172.16.1.13/FGIMA.aspx?t=ssn&sno=" + str_Pallet);
WebResponse response = request.GetResponse();
StreamReader reader = new StreamReader(response.GetResponseStream(), Encoding.GetEncoding("utf-8"));
var html = reader.ReadToEnd();
var strReg = @"(?is)(?<=<table>).+?(?=</table>)";
List<string> result = new List<string>();
MatchCollection mc = Regex.Matches(html, strReg);
DataTable dt = new DataTable();
string strhead = string.Empty;
foreach (Match m in mc)
{
int rowindex = ;
foreach (Match mtr in Regex.Matches(m.Value, "(?is)(?<=<tr>).+?(?=</tr>)"))
{
if (rowindex == )
{
strhead = mtr.Value;
foreach (Match mtdh in Regex.Matches(mtr.Value, "(?is)(?<=<th>).+?(?=</th>)"))
{
if (!dt.Columns.Contains(mtdh.Value.Replace("\r\n", "").Trim()))
{
dt.Columns.Add(mtdh.Value.Replace("\r\n", "").Trim());
}
}
}
else
{
DataRow dr = dt.NewRow();
if (mtr.Value.Contains("累计数量")) continue;
if (mtr.Value.Contains("没有找到相关数据"))
{
return dt;
}
MatchCollection mtdds = Regex.Matches(mtr.Value, "(?is)(?<=<td>).+?(?=</td>)");
int colindex = ;
foreach (Match mtdh in Regex.Matches(strhead, "(?is)(?<=<th>).+?(?=</th>)"))
{
if (mtdh.Value.Contains("机器序列号"))
{
foreach (Match mtdhdd in Regex.Matches(mtr.Value, "(?is)(?<=target=\"_blank\">).+?(?=</a>)"))
{
dr["机器序列号"] = mtdhdd.Value.Replace("\r\n", "").Trim();
}
}
else
dr[mtdh.Value.Replace("\r\n", "").Trim()] = mtdds[colindex].Value.Replace("\r\n", "").Trim();
colindex++;
}
dt.Rows.Add(dr);
}
rowindex++;
}
}
if (dt.Columns.Contains("机器序列号"))
{
dt.Columns["机器序列号"].ColumnName = "SN";
}
if (dt.Columns.Contains("工单号码"))
{
dt.Columns["工单号码"].ColumnName = "WorkorderNo";
}
if (dt.Columns.Contains("成品料号"))
{
dt.Columns["成品料号"].ColumnName = "PartNo";
}
if (dt.Columns.Contains("栈板号码"))
{
dt.Columns["栈板号码"].ColumnName = "Pallet";
}
reader.Close();
reader.Dispose();
response.Close();
return dt;
解析ASPX网页__doPostBack分页的网页table数据的更多相关文章
- 抓取Js动态生成数据且以滚动页面方式分页的网页
代码也可以从我的开源项目HtmlExtractor中获取. 当我们在进行数据抓取的时候,如果目标网站是以Js的方式动态生成数据且以滚动页面的方式进行分页,那么我们该如何抓取呢? 如类似今日头条这样的网 ...
- 可以Ping通和DNS解析,但打不开网页的解决办法
一. 网络故障表现为: 1.Ping地址正常,能ping通任何本来就可以ping通地址,如网关.域名. 2.能DNS解析域名. 3.无法打开网页,感觉是网页打开的一瞬间就显示无网络连接. 4.只需要连 ...
- Django学习(5)优雅地分页展示网页
在我们平时浏览网页时,经常会遇到网页里条目很多的情形,这时就会用到分页展示的功能.那么,在Django中,是如何实现网页分类的功能的呢?答案是Paginator类. 本次分享讲具体展示如何利用Djan ...
- 利用pandas库中的read_html方法快速抓取网页中常见的表格型数据
本文转载自:https://www.makcyun.top/web_scraping_withpython2.html 需要学习的地方: (1)read_html的用法 作用:快速获取在html中页面 ...
- 博客代码:iframe—网页中嵌入其他网页
iframe 是一个可以把另外一个网页嵌入到一个网页里的代码,非常有用.对于一个内容不错的网页,要方便地把它搬到自己的博客里,用这个代码最合适.而对于在新浪博客里不支持的一些网页效果和代码,可先把他们 ...
- HTML-图片热点、网页内嵌、网页拼接、快速切图
图片热点 规划出图片上的一个区域,可以做出超链接,直接点击图片区域就可以完成跳转的效果.与图片链接不同,热点是图片上的某一个区域或多个区域. 我们用魔兽世界图片来做一个图片热点,点击logo.区域和不 ...
- C# 网络编程之webBrowser获取网页url和下载网页中图片
该文章主要是通过C#网络编程的webBrowser获取网页中的url并简单的尝试瞎子啊网页中的图片,主要是为以后网络开发的基础学习.其中主要的通过应用程序结合网页知识.正则表达式实现浏览.获取url. ...
- ifram的使用 左边是<a>链接 右边是对应网页嵌套的显示网页链接内容 和toggle的收放用法
1.ifram的使用 左边是<a>链接 右边是对应网页嵌套的显示网页链接内容 <div class="container"> <div class= ...
- 网页手机wap2.0网页的head里加入下面这条元标签......
网页手机wap2.0网页的head里加入下面这条元标签,在iPhone的浏览器中页面将以原始大小显示,并不允许缩放. <meta name="viewport" conten ...
随机推荐
- 诺基亚 920T - 我的非凡系列手机始终显示旋转齿轮而无响应,我该如何让手机停止显示旋转齿轮?
有时,在 OTA 更新 (或重置手机) 后,设备可能始终显示“旋转齿轮”而无响应. 如果“旋转齿轮”在屏幕上显示的时间超过 60 分钟,则需要执行恢复操作. 您可以尝试下面这些简单的解决方法: 按住电 ...
- bootstrap常用部件下载
http://shapebootstrap.net/item/1524915-adminlte-dashboard-and-control-panel/live-demo
- java线程基础知识----SecurityManager类详解
在查看java Thread源码的时候发现一个类----securityManager,虽然很早就知道存在这样一个类但是都没有深究,今天查看了它的api和源码,发现这个类功能强大,可以做很多权限控制策 ...
- SQL Server修改主、外键和约束
0.创建表 create table Users ( Id int, Name ), Phone ), Email ), Role_Id uniqueidentifier ) go create ta ...
- React 从入门到进阶之路(四)
之前的文章我们介绍了 React 绑定属性( 绑定class 绑定style).引入图片 循环数组渲染数据.接下来我们将介绍 React 事件,方法, React定义方法的几种方式 获取数据 改 ...
- Neutron网络研究
你将学到什么 虚拟机的Ping包是如何出外网的 DevStack环境准备 节点 硬件配置 网络配置 类型 操作系统 DevStack 4G 2CPU 50GB 2张网卡(NAT模式) VMWare虚拟 ...
- 消耗战——dp+虚树
题目 [题目描述] 在一场战争中,战场由 $n$ 个岛屿和 $n-1$ 个桥梁组成,保证每两个岛屿间有且仅有一条路径可达.现在,我军已经侦查到敌军的总部在编号为 $1$ 的岛屿,而且他们已经没有足够多 ...
- 使用shell脚本分析Nagios的status.dat文件
前言 Nagios的安装和配置以及批量添加监控服务器在我前面的文章中已经讲的很详细了. 我们知道,Nagios的网页控制页面(一般为http://nagio.domain.com/nagios)里可以 ...
- centos 7 安装python3
centos系统默认已安装python2.7,python3需要手动安装.以上是安装步骤 一.备份原来的2.7版本 首先看一下默认的python2.7在哪里 [root@apple ~]# cd / ...
- LaTeX使用心得
LaTeX是一个功能强大的,开源的排版工具. 最近教练让我们做课件,我做数论,鉴于LaTeX的数学公式功能强大(而MS办公软件的数学公式简直就是个LJ)和我的学习精神,我决定用LaTeX写课件. 在一 ...