【问题】:spring cloud sleuth日志组件冲突问题
在使用spring cloud sleuth的时候,启动工程报错如下: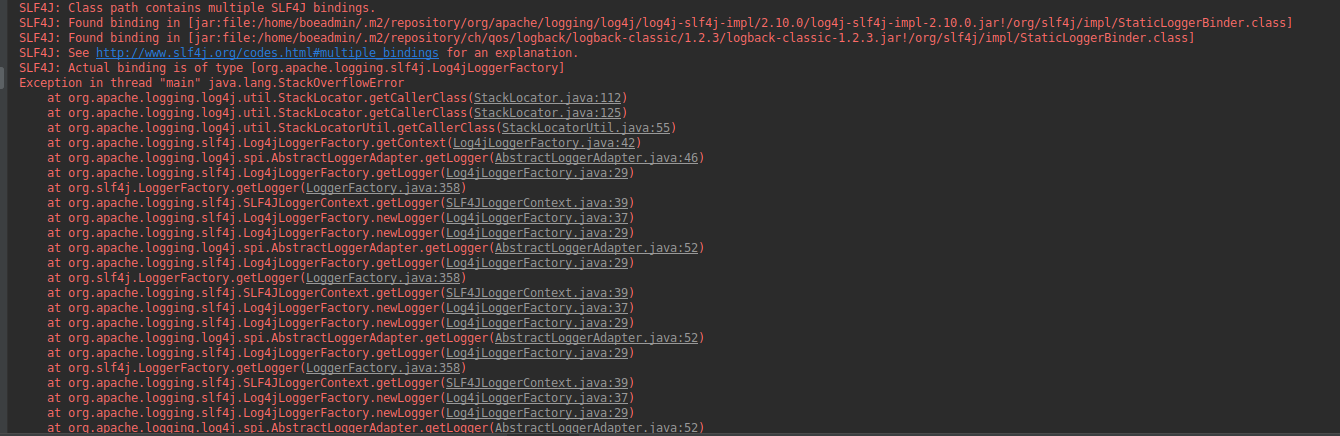
根据错误信息明显就是jar包冲突,spring boot默认用的是logback,所以移除其中一个依赖就可以了,修改pom依赖为以下大功告成。
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-server</artifactId>
<exclusions>
<exclusion>
<artifactId>log4j-slf4j-impl</artifactId>
<groupId>org.apache.logging.log4j</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-ui</artifactId>
</dependency>
</dependencies>
【问题】:spring cloud sleuth日志组件冲突问题的更多相关文章
- spring cloud链路追踪组件sleuth和zipkin
spring cloud链路追踪组件sleuth 主要作用就是日志埋点 操作方法 1.增加依赖 <dependency> <groupId& ...
- springcloud --- spring cloud sleuth和zipkin日志管理(spring boot 2.18)
前言 在spring cloud分布式架构中,系统被拆分成了许多个服务单元,业务复杂性提高.如果出现了异常情况,很难定位到错误位置,所以需要实现分布式链路追踪,跟进一个请求有哪些服务参与,参与的顺序如 ...
- 一句话概括下spring框架及spring cloud框架主要组件
作为java的屌丝,基本上跟上spring屌丝的步伐,也就跟上了主流技术.spring 顶级项目:Spring IO platform:用于系统部署,是可集成的,构建现代化应用的版本平台,具体来说当你 ...
- SpringCloud(7)服务链路追踪Spring Cloud Sleuth
1.简介 Spring Cloud Sleuth 主要功能就是在分布式系统中提供追踪解决方案,并且兼容支持了 zipkin,你只需要在pom文件中引入相应的依赖即可.本文主要讲述服务追踪组件zipki ...
- Spring Cloud Sleuth超详细实战
为什么需要Spring Cloud Sleuth 微服务架构是一个分布式架构,它按业务划分服务单元,一个分布式系统往往有很多个服务单元.由于服务单元数量众多,业务的复杂性,如果出现了错误和异常,很难去 ...
- Spring Cloud Sleuth进阶实战
转载请标明出处: http://blog.csdn.net/forezp/article/details/76795269 本文出自方志朋的博客 为什么需要Spring Cloud Sleuth 微服 ...
- 第11章 分布式服务跟踪: Spring Cloud Sleuth
通常一个由客户端发起的请求在后端系统中会经过多个不同的微服务调用来协同产生最后的请求结果, 在复杂的微服务架构系统中, 几乎每一个前端请求都会形成一条复杂的分布式服务调用链路, 在每条链路中任何一个依 ...
- Spring Cloud Sleuth + Zipkin 链路监控
原文:https://blog.csdn.net/hubo_88/article/details/80878632 在微服务系统中,随着业务的发展,系统会变得越来越大,那么各个服务之间的调用关系也就变 ...
- 【Spring Cloud】Spring Cloud之Spring Cloud Sleuth,分布式服务跟踪(1)
一.Spring Cloud Sleuth组件的作用 为微服务架构增加分布式服务跟踪的能力,对于每个请求,进行全链路调用的跟踪,可以帮助我们快速发现错误根源以及监控分析每条请求链路上的性能瓶颈等. 二 ...
随机推荐
- 关于poedit打开po文件乱码的问题
由于poedit打开po文件时,无法识别译文使用的何种编码,因此需要在po文件头部加上以下代码: msgid "" msgstr "" "Plural ...
- QQ协议
http://www.cnblogs.com/sufei/archive/2012/12/13/2816737.html http://www.360doc.com/content/12/0822/1 ...
- RestAPI的实现
转自:http://blog.csdn.net/yanical/article/details/7856670 Rest的作者认为计算机发展到现在,最大的成就不是企业应用,而是web,是漫漫无边的互联 ...
- JAVA常见算法题(十九)
package com.xiaowu.demo; /** * * 有一分数序列:2/1,3/2,5/3,8/5,13/8,21/13...求出这个数列的前20项之和. * * * @author WQ ...
- Linux内核实践之工作队列
工作队列(work queue)是另外一种将工作推后执行的形式,它和tasklet有所不同.工作队列可以把工作推后,交由一个内核线程去执行,也就是说,这个下半部分可以在进程上下文中执行.这样,通过工作 ...
- 如何在阿里云服务器搭建FTP服务器,在本地电脑连接并操作
首先你需要有一个阿里云的ECS服务器 并且开通了公网宽带(话说也不贵,开来玩玩还是可以的,第一次买会比较便宜,第二次买1M的宽带两天是九毛多吧~) 开通了宽带之后,ECS服务器就可以上网了 如果嫌弃阿 ...
- [Algorithm] Heap data structure and heap sort algorithm
Source, git Heap is a data structure that can fundamentally change the performance of fairly common ...
- Linux学习笔记 (二)常用linux命令
一.命令行语法: 命令字 [选项] [参数] 注意:Linux中对命令是区分大小写的. 二.获取命令帮助: 1.help命令:help xxx,shell内部指令,用来获取linux内部命令.例如:h ...
- javascript 数组 find
find() 方法返回通过测试(函数内判断)的数组的第一个元素的值. let arr = [1,2,3,4] console.log(arr.find(i => {return i>1}) ...
- Javascript 客户端实时显示服务器时间
<!doctype html> <html lang="zh-cn"> <head> <meta charset="utf-8& ...