Hive 的企业优化
优化
数据优化
一、从大表拆分成小表(更快地检索)
eg2:常用于分表
create table if not exists default.cenzhongman_2
AS select ip,date from default.cenzhongman;
二、使用外部表(多部门共用,指定存储目录,删表不删数据),分区表(按月按XXX分区)
#创建外部表
CREATE EXTERNAL TABLE IF NOT EXISTS table_name();
#创建分区表
create table emp_partition(ID int, name string, job string, mrg int, hiredate string, sal double, comm double, deptno int) partitioned by (mouth string);
三、使用 ORC | parquet 数据存储格式
#官网例子
create table Addresses (
name string,
street string,
city string,
state string,
zip int
) stored as orc tblproperties ("orc.compress"="NONE");
四、使用 snappy 压缩格式
如上例
五、FetchTask 抓取任务转换 > more
<property>
<name>hive.fetch.task.conversion</name>
<value>more</value>
<description>
Expects one of [none, minimal, more].
Some select queries can be converted to single FETCH task minimizing latency.
Currently the query should be single sourced not having any subquery and should not have
any aggregations or distincts (which incurs RS), lateral views and joins.
0. none : disable hive.fetch.task.conversion
1. minimal : SELECT STAR, FILTER on partition columns, LIMIT only (Select * 、筛选分区、limit 限制显示行数 这三种行为不会经过 mapreduce)
2. more : SELECT, FILTER, LIMIT only (support TABLESAMPLE and virtual columns)(相对nimimal 增加了时间戳,虚拟列,还有所有的选择)
</description>
</property>
优化 SQL 语句
join 优化
common/shuffle/reduce join :join 发生在 reduce 阶段
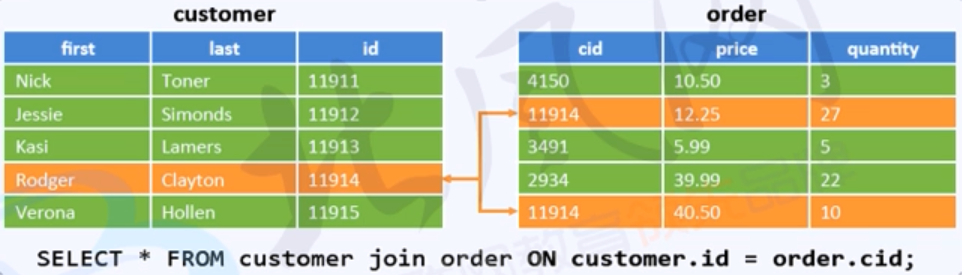

大表对大表,每个表的数据都从文件中读取(发生在Reduce shuffle 的分组Group过程(相同的key的value放在一起))
Map join :join 发生在 Map 阶段

小表对大表,大表的数据从文件中读取,小表的数据在内存中,通过 DistributedCache 类进行缓存
SMB join :Sort-Merge-Bucket join
SMB 的设置

注:Bucket CLUSTERED 按照 num_buckets 对数据进行分区并排序
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]


面对大表对大表处理时候的优化,Merge > sort > join
根据两个表的相同字段进行 按 num_buckets 分组(Merge) 并 在组内 排序(Sort)
execution plan 执行计划
官方文档
查看执行计划
EXPLAIN [EXTENDED|DEPENDENCY|AUTHORIZATION] query
eg:explain select * from emp;
能够看到的信息
- The Abstract Syntax Tree for the query 语法树
- The dependencies between the different stages of the plan 依赖关系
- The description of each of the stages 每个阶段的描述
其他高级优化
1.设置任务并行执行
| 参数 | 值 | 备注 |
|---|---|---|
| hive.exec.parallel | false | 默认为 false |
| hive.exec.parallel.thread.number | 8 | 建议10 ~ 20 之间 |
2.合理设置 reduce 任务的数量
| 参数 | 值 | 备注 |
|---|---|---|
| mapreduce.job.reduces | 1 | 测试出真知 |
3.推测执行 speculative
在 mapReduce 运行过程中,当 ApplicationMaster 检测到任务执行时间差异明显比正常时间长时,会多运行一个任务,结果取决于最先结束运行的任务。
在 Hive 执行过程中出现长时间任务为正常现象,为了防止系统创建重复任务占用过多的资源,应该关闭该功能
| 参数 | 值 | 备注 |
|---|---|---|
| hive.mapred.reduce.tasks.speculative.execution | true | 当用 Hive 时候推荐为 false |
| mapreduce.map.speculative | true | 当用 Hive 时候推荐为 false |
| mapreduce.reduce.speculative | true | 当用 Hive 时候推荐为 false |
4.合理设置 Map 值
一般来说,根据文件大小就是很合理的了。
5.动态分区调整
| 参数 | 值 | 备注 |
|---|---|---|
| hive.exec.dynamic.partition | true | 是否开启动态分区属性 |
| hive.exec.dynamic.partition.mode | strict | strict mode, 用户必须指定至少一个静态分区以防用户意外地覆盖了所有的分区。nonstrict mode 所有的分区都是动态的 |
6.查询模式设置
| 参数 | 值 | 备注 |
|---|---|---|
| hive.mapred.mode nonstrict | nostrict | strict/nostrict |
设置严格模式将禁止三种类型查询
- 1)对于分区表,不加分区字段过滤条件,不能执行:分区表中,where 子句中不加分区过滤
Error eg:select * from emp_partition where name = 'cenzhongman';
Right eg:select * from emp_partition where name = 'cenzhongman', month = '201707'; - 2)对于 oder by 语句,必须使用 limit 语句
- 3)限制笛卡尔积的查询(Join 的时候不适用 on 而使用 where 的)
Hive 的企业优化的更多相关文章
- 深入浅出Hive企业级架构优化、Hive Sql优化、压缩和分布式缓存(企业Hadoop应用核心产品)
一.本课程是怎么样的一门课程(全面介绍) 1.1.课程的背景 作为企业Hadoop应用的核心产品,Hive承载着FaceBook.淘宝等大佬 95%以上的离线统计,很多企业里的离线统 ...
- HDP Hive StorageHandler 下推优化的坑
关键词:hdp , hive , StorageHandler 了解Hive StorageHandler的同学都知道,StorageHandler作为Hive适配不同存储的拓展类,同时肩负着Hive ...
- 大数据技术之_11_HBase学习_02_HBase API 操作 + HBase 与 Hive 集成 + HBase 优化
第6章 HBase API 操作6.1 环境准备6.2 HBase API6.2.1 判断表是否存在6.2.2 抽取获取 Configuration.Connection.Admin 对象的方法以及关 ...
- Hive常用性能优化方法实践全面总结
Apache Hive作为处理大数据量的大数据领域数据建设核心工具,数据量往往不是影响Hive执行效率的核心因素,数据倾斜.job数分配的不合理.磁盘或网络I/O过高.MapReduce配置的不合理等 ...
- 大数据开发主战场hive (企业hive应用)
hive在大数据套件中占很的地位,分享下个人经验. 1.在hive日常开发中,我们首先面对的就是hive的表和库,因此我要先了解库,表的命名规范和原则 如 dwd_whct_xmxx_m 第1部分为表 ...
- Hive语句执行优化-简化UDF执行过程
Hive会将执行的SQL语句翻译成对应MapReduce任务,当SQL语句比较简单时,性能还是可能处于可接受的范围.但是如果涉及到非常复杂的业务逻辑,特别是通过程序的方式(一些模版语言生成)生成大 ...
- hive中的优化问题
一.fetch抓取 fetch 抓取是指,hive中对某些情况的查询可以不必使用MapReduce计算.(1)把hive.fetch.task.conversion 设置成none,然后执行查询语句, ...
- nginx配置文件企业优化
1.1 企业规范优化Nginx配置文件 第一个里程碑:创建扩展目录,生成虚拟主机配置文件 mkdir extra sed -n '10,15p' nginx.conf >extra/www.co ...
- Hadoop Hive概念学习系列之hive里的优化和高级功能(十四)
在一些特定的业务场景下,使用hive默认的配置对数据进行分析,虽然默认的配置能够实现业务需求,但是分析效率可能会很低. Hive有针对性地对不同的查询进行了优化.在Hive里可以通过修改配置的方式进行 ...
随机推荐
- Android 关于apk 打包后的地图定位和导航失败的问题
项目中,使用了高德地图定位,调试的debug包定位完全没有问题,但是签名打包后,却始终无法定位,发现是测试环境下的SHA1码和签名发布版的SHA1码是不同的. 所以我们需要获取发布版的SHA1码: 方 ...
- 【Node.js】一个愚蠢的Try Catch过错
前段时间学习<深入浅出Nodejs>时,在第四章 - 异步编程中作者朴灵曾提到,异步编程的难点之一是异常处理,书中描述"尝试对异步方法进行try/catch操作只能捕获当次事件循 ...
- Linux命令之文件重定向2
linux中重定向用符号“>”表示,语法一般是 源文件 > 目标文件 1)创出.txt文件touch 1.txt 注意:创建文件夹用mkdir 2)向.txt文件中写入内容 注意:①cat ...
- 洛谷 P1080 国王游戏
题目描述 恰逢 H 国国庆,国王邀请 n 位大臣来玩一个有奖游戏.首先,他让每个大臣在左.右手上面分别写下一个整数,国王自己也在左.右手上各写一个整数.然后,让这 n 位大臣排成一排,国王站在队伍的最 ...
- python 笔记1:官网下载及安装python;eclipse中安装配置pydev
1 下载安装python. 官网:https://www.python.org/downloads/ 根据自己的操作系统选择需要的版本下载并安装. 我的电脑操作系统windows xp的,只 ...
- 返回json格式 不忽略null字段
返回json格式 不忽略null字段 发布于 353天前 作者 king666 271 次浏览 复制 上一个帖子 下一个帖子 标签: json 如题,一个实体的某个字段如果为null,在 ...
- 【UOJ139】【UER #4】被删除的黑白树(贪心)
点此看题面 大致题意: 请你给一棵树黑白染色,使每一个叶结点到根节点的路径上黑节点个数相同. 贪心 显然,按照贪心的思想,我们要让叶结点到根节点的路径上黑节点的个数尽量大. 我们可以用\(Min_i\ ...
- 网格中的BFS,逆向(POJ2049)
题目链接:http://poj.org/problem?id=2049 解题报告: 网格中的BFS,最主要的是边界问题. 1.这里在左右,上下两个方向上,分别判断墙,和门,细节是,向上有t个墙,for ...
- an exception occurred while initializing the database.
对于手动删除本地的LocalDB数据库之后出现标题所示异常的,推荐下面的命令: sqllocaldb.exe stop v11.0 sqllocaldb.exe delete v11.0 在程序包管理 ...
- Ray-AABB交叉检测算法
最近在解决三维问题时,需要判断线段是否与立方体交叉,这个问题可以引申为:射线是否穿过立方体AABB. 在3D游戏开发中碰撞检测普遍采用的算法是轴对齐矩形边界框(Axially Aligned ...