Sql优化器究竟帮你做了哪些工作?
关系型数据库的一大优势之一,用户无需关心数据的访问方式,因为这些优化器都帮我们处理好了,但sql查询优化的时候,我不得不要对此进行关注,因为这牵扯到查询性能问题。
有经验的程序员都会对一些sql优化了如指掌,比如我们常说的最左匹配原则,非BT谓词规避等等,那么优化器是如何确定这些的?以及为何一定要最左匹配,最左匹配的原理是什么,你是否有深入了解?
这一篇我们就通过一些实例来剖析优化器做了哪些工作,以方便我们更好的优化SQL查询。
本篇你可以知道:
sql的访问路径是什么
优化器如何确定最优访问路径
最左匹配的原则依据是什么
如何有效的评估sql命中行数
示例table:
CREATE TABLE test (
id int(11) NOT NULL AUTO_INCREMENT,
user_name varchar(100) DEFAULT NULL,
sex int(11) DEFAULT NULL,
age int(11) DEFAULT NULL,
c_date datetime DEFAULT NULL,
PRIMARY KEY (id),
# 索引
KEY id_name_sex (id,user_name,sex),
KEY name_sex_age (user_name,sex,age)
) ENGINE=InnoDB AUTO_INCREMENT=12 DEFAULT CHARSET=utf8;
一、访问路径
在SQL语句能够被真正执行之前,优化器必须首先确定如何访问数据。这包括:应该使用哪一个索引,索引的访问方式如何,是否需要辅助式随机读,等等。
从一条SQL,到优化器优化,再到引擎进行数据查询,落地到数据的存储页面,这是一个访问路径确定的过程。
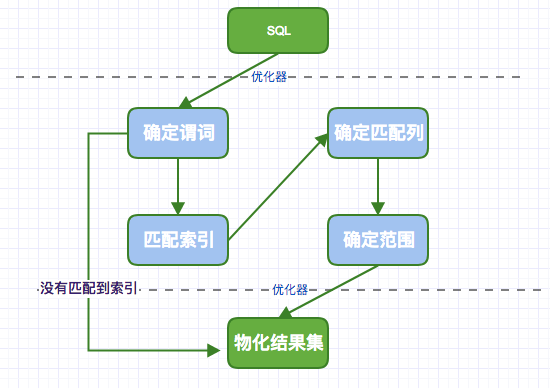
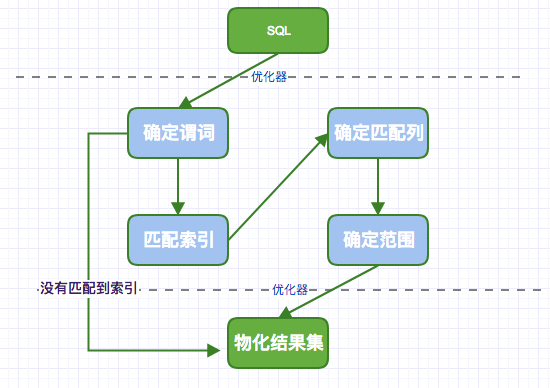
二、谓词
谓词就是我们常说的where子句中的一个或多个搜索参数组成。谓词表达式是索引设计的主要入手点,如果一个索引能够满足select查询语句的所有谓词表达式,那么优化器就可能建立一个高效的访问路径。
select * from test where id =1 and user_name like ’test%’
比如,上述查询 中,where后面的搜索参数,id 和user_name 就是谓词。
三、索引片
索引片即代表谓词表达式所确定的值域范围,而访问路径的成本很大程度上取决于索引片的厚度。
索引片越厚,需要扫描的索引页就越多,需要处理的索引记录也越多,而且最大的开销还是来自于需要对标进行同步读操作。相反,索引片比较窄,就会显著减少索引访问的那部分开销,同时会有更少的表同步读取上。
同步读是一个随机IO操作,单次的读取就要耗费10ms左右的时间。这个我们在上篇有说明。
比如:
//会匹配到5个数据
sql1:select * from test where sex=1;
// 匹配到2个数据
sql2:select * from test where sex=1 and age <10;
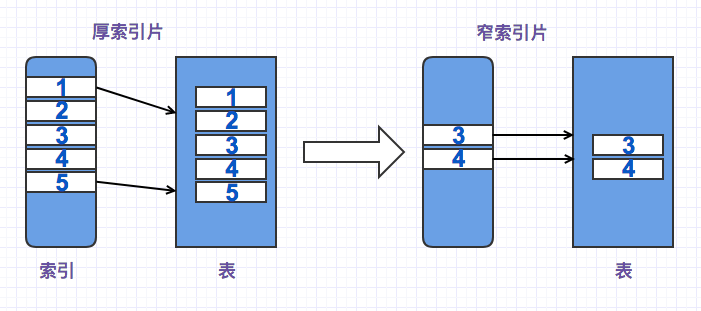
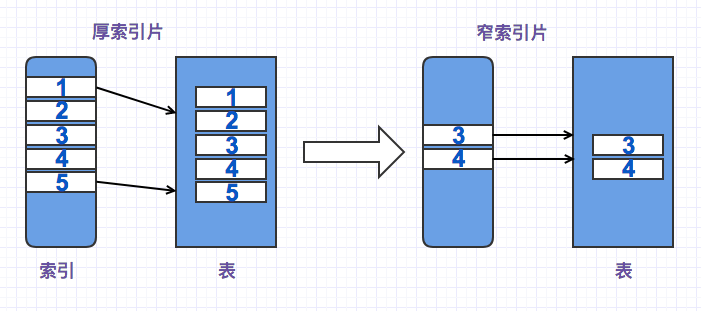
因此我们需要通过谓词来确定索引片的厚度,过滤的值域范围越少,索引片厚度就越窄。那么谓词一定就能匹配到索引么,或者说匹配的规则是什么?
四、匹配列&过滤列
谓词不一定都能匹配到索引,能够匹配上的,我们称之为匹配列。此时它可以参与索引片的定义。
只有匹配列和过滤列可以参与索引片的定义和过滤,其他不可。
我们来看下谓词匹配的定义:
检查索引列,从头到尾依次检查索引列,查看以下规则:
在where子句中,该列是否至少拥有一个足够简单的谓词与之对应?如果有,则这个列就是匹配列。如果没有,那么这个列及其后面的索引列都是非匹配列。
谓词是否是一个范围谓词,如果是,那么剩余的索引列都是非匹配列。
对于最后一个匹配列之后的索引列,如果拥有一个足够简单的谓词与其对应,那么该列为过滤列。
1、示例
select * from test where user_name=’test1’ and sex>0 and age =10
发现索引id_name_sex
逐行检查其索引列(
id,user_name,sex)首先检查
id,发现where后面的谓词没有与之对应,则 这个索引列以及后面的索引列都是非匹配列索引
id_name_sex匹配结束,无匹配列
发现索引name_sex_age
逐行检查其索引列(
user_name,sex,age)首先检查
user_name,发现where后面的 谓词user_name有与之对应,认定此列为匹配列检查索引字段
sex,发现where后面有谓词sex与之对应,认定此列为匹配列,由于谓词sex是范围谓词,则剩余的索引为非匹配列。索引列
age是在最后一个匹配列sex之后,而又有谓词age与之对应,因此此列 为过滤列,
通过这个示例,我们最终确定了:
匹配索引:
name_sex_age匹配列:
user_name,sex过滤列:
age
我们查看下 explain ,和我们分析的对应。


2、确定匹配列有什么用
确定匹配列之后我们可以知道当前的查询会用到哪些索引,以及匹配到该索引的哪些列,最终可以提前锁定数据的访问范围,为数据的读取节省读取压力。
相对于没用匹配到索引的查询,有匹配列的查询,条件过滤是前置的,而没有匹配到索引的查询,条件过滤是后置的,即全表扫描之后,再过滤结果,如此磁盘IO压力过大。
另外 “最左匹配”原则也是基于匹配列规则而来,为何是最左匹配,除了B树的原理之外,还有一个重要的原因,在核对匹配列的时候,是从头到尾依次检查索引列。
所以对于是否能够匹配到索引,where后面的谓词顺序不重要,重要的是索引列的顺序。
比如:
select * from test where user_name=’test1’ and sex>0 and age =10
select * from test where sex>0 and user_name=’test1’ and age =10
select * from test where age =10 and user_name='test1' and sex>0
都可以匹配到name_sex_age 索引



3、复杂谓词
like 谓词
如果值是%xx ,那么将会选择全索引扫描,不参与索引匹配,如果是xx%,这会参与索引匹配,选择索引片扫描。
OR操作符
即便是简单的谓词,如果它们与其他谓词之间为OR操作,对优化器而言是异常困难的,除非在多索引访问,才有可能参与到一个索引片的定义,尽量不要用。
假设一个谓词的判定结果为false,而此时不检查其他谓词就不能确定的将一行记录排除在外,那么这类谓词对优化器而言就是十分困难的。
BT谓词
比如只有and 操作符,那么所有的简单谓词都可以称谓BT谓词,也就是好的谓词,除非访问路径是一个多索引扫描,否则只有BT谓词可以参加定义索引片。
谓词值不确定
比如谓词的值采用了函数,或者参与了计算,优化器在做静态SQL绑定的时候,每次都需要重新计算选择,无法缓存,耗费大量的CPU,也无法参与索引列的匹配。
五、过滤因子
匹配列确定了使用那些索引列,但索引片的厚度(也就是预计要访问多少行),还没有估算出来。此处需要进行通过过滤因子来确定。
过滤因子描述的谓词的选择性,即表中满足谓词条件的记录行数所占用的比例,依赖于列值分布情况。
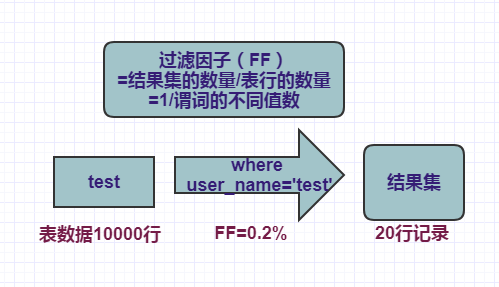
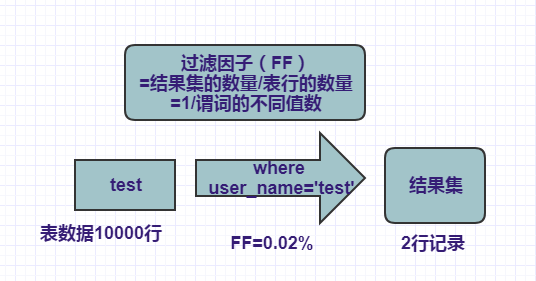
1、单个谓词的过滤因子
比如,我们的的test表有10000条记录,谓词user_name 匹配了 一个索引列,其过滤因子是0.2%(1/不同user_name数量=user_name中有500个不同值的比率),则意味着查询结果会包含20行的记录。
select * from test where user_name=’test’
2、组合谓词的过滤因子
当有多个谓词符合匹配列的时候,我们可以通过单个谓词的过滤因子推导出组合过滤因子。一般的公式是:
组合过滤因子=谓词1过滤因子*谓词2过滤因子....
比如如下查询
select * from test where user_name=’test’ and sex=1 and age =10
包含3个谓词,user_name、sex、age、其中user_name有500个不同的值,sex有2个不同的值,age有40个不同的值。
则每个谓词的过滤因子:
FF(user_name) =1/500*100 =0.2%
FF(sex) =1/2*100=50%
FF(age) =1/40*100=2.5%
组合过滤因子=0.2%*50%*2.5%=0.0025%
通过以上组合过滤因子,可以推算出最终的结果集=10000*0.0025%=0.25 ~=1
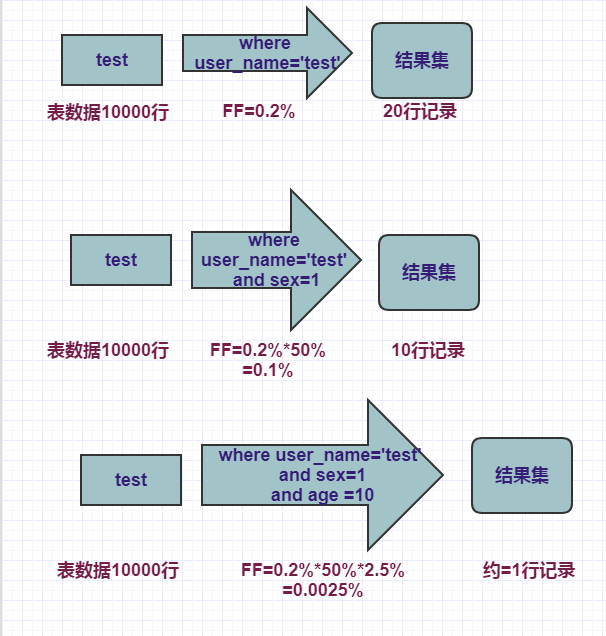
通过以上过滤因子评估之后,我们可以看到,最终需要查找的结果集只需要获取1行就够了,这对数据库的磁盘访问有很高的性能提升。
这也是优化器在评估可选访问路径成时,必须先进行过滤因子评估的重要性。
六、排序
物化结果集意味着通过执行必要的数据库访问来构建结果集。最好情况下,只需要返回一条记录,而最坏的情况下需要返回多条记录,需要发起大量的磁盘读取。而排序就是其中一种。
在以下情况中,一次fetch调用只需要物化一条记录,否则对结果进行排序的时候就需要物化整个结果集。
没有排序需求,比如order by,group by 等。
虽然需要排序满足以下两个条件:
<!--存在一个索引满足结果集的排序需求,比如上述的(id_name_sex) 或者(name_sex_age)-->
<!--优化器决定以传统的方式使用这个索引,即访问第一条满足条件的索引行并读取相应的表行,然后访问第二条满足条件的索引行并读取相应的表行,依次类推。-->
<!--比如使用索引(name_sex_age)时候,select * from test where user_name=’test’ order by sex ,此时在索引中,结果集基于sex本身就是有序的-->
七、最后
sql优化器做的不仅仅是你这些工作,但索引片的大小的预估,以及访问路径的确定却是它最重要的工作,后续我们再继续介绍。
转载出处:https://my.oschina.net/u/1859679/blog/1586098
版权申明:内容来源网络,版权归原创者所有。除非无法确认,我们都会标明作者及出处,如有侵权烦请告知,我们会立即删除并表示歉意。谢谢。
小编积累多年的干货文档免费赠送,包含前端后端和测试,系统架构,高并发处理,优化等

Sql优化器究竟帮你做了哪些工作?的更多相关文章
- Sql优化器究竟帮你做了哪些工作
https://my.oschina.net/u/1859679?tab=newest&catalogId=597012 上一篇,我们介绍了<DB——数据的读取和存储方式>,这篇聊 ...
- SQL优化器执行过程之逻辑算子
我们提到了两种SQL优化器,分别是RBO和CBO.那么无论是RBO,还是CBO都包含了一系列优化规则,这些优化规则可以对关系表达式进行等价转换,从而寻找最优的执行计划. 那么常见的优化规则就包括: 列 ...
- 深入了解 TiDB SQL 优化器
分享嘉宾:张建 PingCAP TiDB优化器与执行引擎技术负责人 编辑整理:Druid中国用户组第6次大数据MeetUp 出品平台:DataFunTalk 导读: 本次报告张老师主要从原理上带大家深 ...
- SQL优化器-RBO与CBO分别是什么
数据库系统发展历史 数据库系统产生于20世纪60年代中期,至今有近50多年的历史,其发展经历了三代演变,造就了四位图灵奖得主,发展成为一门计算机基础学科,带动了一个巨大的软件产业. 数据库系统是操作系 ...
- Oracle SQL优化器简介
目录 一.Oracle的优化器 1.1 优化器简介 1.2 SQL执行过程 二.优化器优化方式 2.1 优化器的优化方式 2.2 基于规则的优化器 2.3 基于成本的优化器 三.优化器优化模式 3.1 ...
- 分享:SQL优化器简介
SQL优化是我们经常会遇到的问题,无论你是专职的数据分析人员还是全栈开发大神或者是CURD搬运工. 我们在工作中经常会听到这样的声音:“查询慢?加个索引吧”.虽然加索引并不一定能解决问题,但是这体现了 ...
- SQL优化器简介
文章导读: 什么是RBO? 什么是CBO? 我们在工作中经常会听到这样的声音:"SQL查询慢?你给数据库加个索引啊".虽然加索引并不一定能解决问题,但是这初步的体现了SQL优化的思 ...
- 从两表连接看Oracle sql优化器的效果
select emp.*,dept.* from tb_emp03 emp,tb_dept03 dept where emp.deptno=dept.id -- 不加hint SQL> sele ...
- 转://从一条巨慢SQL看基于Oracle的SQL优化
http://mp.weixin.qq.com/s/DkIPwbDKIjH2FMN13GkT4w 本次分享的内容是基于Oracle的SQL优化,以一条巨慢的SQL为例,从快速解读SQL执行计划.如何从 ...
随机推荐
- 虚拟机上安装Cell节点(12.1.2.3.3)
安装介质下载 打开firefox,输入:https://edelivery.oracle.com 点击"Sign In",输入帐号.密码,登陆edelivery网站. ...
- element input搜索框探索
转(https://blog.csdn.net/qq_37746973/article/details/78402812) 在script中添加下面两个函数 //queryString 为在框中输入的 ...
- Luogu P4551 最长异或路径 01trie
做一个树上前缀异或和,然后把前缀和插到$01trie$里,然后再对每一个前缀异或和整个查一遍,在树上从高位向低位贪心,按位优先选择不同的,就能贪出最大的答案. #include<cstdio&g ...
- django 请求生命周期
详细例子:
- spring boot之 Bean的初始化和销毁(4)
原文:https://blog.csdn.net/z3133464733/article/details/79189699 -------------------------------------- ...
- about 字节
关于由于赋值导致字节的截断.字节扩展及数据类型的提升: 一.字节截断:int----->char 当一个字节(8位)放不下时,出现截断,直接取(最后一个字节)最后面面8位. 例如:1000000 ...
- Java集合——集合框架Set接口
1.Set接口 一个不包含重复元素的collecyion.更确切的讲,set不包含满足e1.equals(e2)的元素e1和e2,并且最多包含一个null元素. 2.HashSet 类实现Set接口, ...
- ElasticSearch 全文检索— ElasticSearch 基本操作
REST 简介-定义 REST (REpresentation State Transfer)描述了一个架构样式的网络系统,比如 web 应用程序.它首次出现在 2000 年 Roy Fielding ...
- MapReduce 二次排序
默认情况下,Map 输出的结果会对 Key 进行默认的排序,但是有时候需要对 Key 排序的同时再对 Value 进行排序,这时候就要用到二次排序了.下面让我们来介绍一下什么是二次排序. 二次排序原理 ...
- Java爬虫初体验
年关将近,工作上该完成的都差不多了,上午闲着就接触学习了一下爬虫,抽空还把正则表达式复习了,Java的Regex和JS上还是有区别的,JS上的"\w"Java得写成"\\ ...