SQL Server Lock Escalation - 锁升级
Articles
- Locking in Microsoft SQL Server (Part 12 – Lock Escalation)
- http://dba.stackexchange.com/questions/12864/what-is-lock-escalation
- 2008 R2 Lock Escalation (Database Engine)
---Forward from Locking in Microsoft SQL Server (Part 12 – Lock Escalation)
Today I’d like us to talk about Lock Escalation in Microsoft SQL Server. We will cover:
- What is Lock Escalation?
- How Lock Escalations affects the system
- How to detect and troubleshoot Lock Escalations
- How to disable Lock Escalation
What is Lock Escalation?
All of us know that SQL Server uses row level locking. Let’s think about
scenario when system modifies the row. Let’s create the small table and
insert 1 row there and next check the locks we have. As usual every
image is clickable.
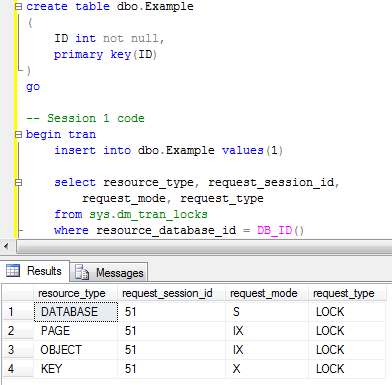
As you can see there are 4 locks in the picture. shared (S) lock on
the database – e.g. indication that database is in use. Intent exclusive
(IX) lock on the table (OBJECT) – e.g. indication that one of the child
objects (row/key in our case) has the exclusive lock. Intent exclusive
(IX) lock on the page – e.g. same indication about child object
(row/key) exclusive lock. And finally exclusive (X) lock on the key
(row) we just inserted.
Now let’s insert another row in the different session (let’s keep the original Session 1 transaction uncommitted).
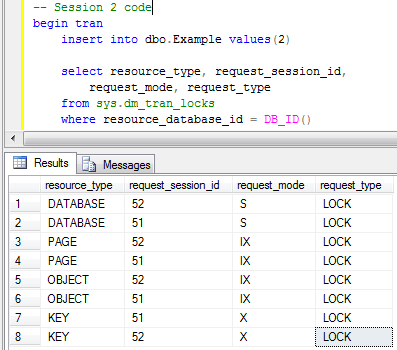
When we check the locks we will see that there are 8 locks – 4 per
session. Both sessions ran just fine and don’t block each other.
Everything works smooth – that great for the concurrency. So far so
good. The problem though is that every lock takes some memory space –
128 bytes on 64 bit OS and 64 bytes on 32 bit OS). And memory is not the
free resource. Let’s take a look at another example. I’m creating the
table and populating it with 100,000 rows. Next, I’m disabling the lock
escalation on the table (ignore it for now) and clear all system cache
(don’t do it in production). Now let’s run the transaction in repeatable
read isolation level and initiate the table scan.

Transaction is not committed and as we remember, in repeatable read isolation level SQL Server holds the locks till end of transaction. And now let’s see how many locks we have and how much memory does it use.


As you can see, now we have 102,780 lock structures that takes more than
20MB of RAM. And what if we have a table with billions of rows? This is
the case when SQL Server starts to use the process that called “Lock
Escalation” – in nutshell, instead of keeping locks on every row SQL
Server tries to escalate them to the higher (object) level. Let’s see
how it works.
First we need to commit transaction and clear the cache. Next, let’s
switch lock escalation for Data table to AUTO level (I’ll explain it in
details later) and see what will happen if we re-run the previous
example.

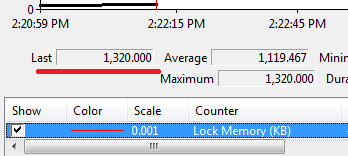
As you can see – just 2 locks and only 1Mb of RAM is used (Memory
clerk reserves some space). Now let’s look what locks do we have:
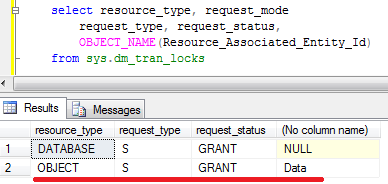
As you can see there is the same (S) lock on the database and now we
have the new (S) shared lock on the table. No locks on page/row levels
are kept. Obviously concurrency is not as good as it used to be. Now,
for example, other sessions would not be able to update the data on the
table – (S) lock is incompatible with (IX) on the table level. And
obviously, if we have lock escalation due data modifications, the table
would hold (X) exclusive lock – so other sessions would not be able to
read the data either.
The next question is when escalation happens. Based on the
documentation, SQL Server tries to escalate locks after it acquires at
least 5,000 locks on the object. If escalation failed, it tries again
after at least 1,250 new locks. The locks count on index/object level.
So if Table has 2 indexes – A and B you have 4,500 locks on the index A
and 4,500 locks on the index B, the locks would not be escalated. In
real life, your mileage may vary – see example below – 5,999 locks does
not trigger the escalation but 6,999 does.

How it affects the system?
Let’s re-iterate our first small example on the bigger scope. Let’s
run the first session that updates 1,000 rows and check what locks are
held.

As you see, we have intent exclusive (IX) locks on the object (table)
and pages as well as various (X) locks on the rows. If we run another
session that updates completely different rows everything would be just
fine. (IX) locks on table are compatible. (X) locks are not acquired on
the same rows.

Now let’s trigger lock escalation updating 11,000 rows.

As you can see – now the table has exclusive lock. So if you run the
session 2 query from above again, it would be blocked because (X) lock
on the table held by session 1 is incompatible with (IX) lock from the
session 2.
When it affects us? There are 2 very specific situations
- Batch inserts/updates/deletes. You’re trying to import thousands of
the rows (even from the stage table). If your import session is lucky
enough to escalate the lock, neither of other sessions would be able to
access the table till transaction is committed. - Reporting – if you’re using repeatable read or serializable
isolation levels in order to have data consistent in reports, you can
have (S) lock escalated to the table level and as result, writers will
be blocked until the end of transaction.
And of course, any excessive locking in the system can trigger it too.
How to detect and troubleshoot Lock Escalations
First of all, even if you have the lock escalations it does not mean
that it’s bad. After all, this is expected behavior of SQL Server. The
problem with the lock escalations though is that usually customers are
complaining that some queries are running slow. In that particular case
waits due lock escalations from other processes could be the issue. If
we look at the example above when session 2 is blocked, and run the
script (as the session 3) that analyzes sys.dm_tran_locks DMV, we’d see
that:


I’m very heavy on the wait statistics as the first troubleshooting tool (perhaps heavier than I need to be
). One of the signs of the issues with lock escalations would be the
high percent of intent lock waits (LCK_M_I*) together with relatively
small percent of regular non-intent lock waits. See the example below:

In case if the system has high percent of both intent and regular
lock waits, I’d focus on the regular locks first (mainly check if
queries are optimized). There is the good chance that intent locks are
not related with lock escalations.
In addition to DMVs (sys.dm_tran_locks, sys.dm_os_waiting_tasks,
sys.dm_os_wait_stats, etc), there are Lock Escalation Profiler event and
Lock Escalation extended event you can capture. You can also monitor
performance counters related with locking and create the baseline
(always the great idea)
Last but not least, look at the queries. As I mentioned before
in most part of the cases excessive locking happen because of
non-optimized queries. And that, of course, can also trigger the lock
escalations.
How to disable Lock Escalation
Yes, you can disable Lock Escalations. But it should be the last
resort. Before you implement that, please consider other approaches
- For data consistency for reporting (repeatable read/serializable isolation levels) – switch to optimistic(read committed snapshot, snapshot) isolation levels
- For batch operations consider to either change batch size to be
below 5,000 rows threshold or, if it’s impossible, you can play with
lock compatibility. For example have another session that aquires IS
lock on the table while importing data. Or use partition switch from the
staging table if it’s possible
In case if neither option works for you please test the system before you disable the lock escalations. So:
For both SQL Server 2005 and 2008 you can alter the behavior on the
instance level with Trace Flags 1211 and 1224. Trace flag 1211 disables
the lock escalation in every cases. In case, if there are no available
memory for the locks, the error 1204 (Unable to allocate lock resource)
would be generated. Trace flag 1224 would disable lock escalations in
case if there is no memory pressure in the system. Although locks would
be escalated in case of the memory pressure.
With SQL Server 2005 trace flags are the only options you have. With
SQL Server 2008 you can also specify escalation rules on the table level
with ALTER TABLE SET LOCK_ESCALATION statement. There are 3 available
modes:
- DISABLE – lock escalation on specific table is disabled
- TABLE (default) – default behavior of lock escalation – locks are escalated to the table level.
- AUTO – if table is partitioned, locks would be escalated to
partition level when table is partitioned or on table level if table is
not partitioned
SQL Server Lock Escalation - 锁升级的更多相关文章
- 如何解决 SQL Server 中的锁升级所致的阻塞问题
概要 锁升级为表锁插入转换很多细粒度的锁 (如行或页锁) 的过程.Microsoft SQL Server 动态确定何时执行锁升级.作出决定之前,SQL Server 将特定的扫描,整个事务,并且用于 ...
- SQL Server深入理解“锁”机制
相比于 SQL Server 2005(比如快照隔离和改进的锁与死锁监视),SQL Server 2008 并没有在锁的行为和特性上做出任何重大改变.SQL Server 2008 引入的一个主要新特 ...
- sql server 阻塞与锁
SQL Server阻塞与锁 在讨论阻塞与加锁之前,需要先理解一些核心概念:并发性.事务.隔离级别.阻塞锁及死锁. 并发性是指多个进程在相同时间访问或者更改共享数据的能力.一般情况而言,一个系统在互不 ...
- 【转】T-SQL查询进阶—理解SQL Server中的锁
简介 在SQL Server中,每一个查询都会找到最短路径实现自己的目标.如果数据库只接受一个连接一次只执行一个查询.那么查询当然是要多快好省的完成工作.但对于大多数数据库来说是需要同时处理多个查 ...
- SQL Server中的锁的简单学习
简介 在SQL Server中,每一个查询都会找到最短路径实现自己的目标.如果数据库只接受一个连接一次只执行一个查询.那么查询当然是要多快好省的完成工作.但对于大多数数据库来说是需要同时处理多个查询的 ...
- sql server行级锁,排它锁,共享锁的使用
锁的概述 一. 为什么要引入锁 多个用户同时对数据库的并发操作时会带来以下数据不一致的问题: 丢失更新 A,B两个用户读同一数据并进行修改,其中一个用户的修改结果破坏了另一个修改的结果,比如订票系统 ...
- T-SQL查询进阶—理解SQL Server中的锁
在SQL Server中,每一个查询都会找到最短路径实现自己的目标.如果数据库只接受一个连接一次只执行一个查询.那么查询当然是要多快好省的完成工作.但对于大多数数据库来说是需要同时处理多个查询的.这些 ...
- 【SqlServer系列】浅谈SQL Server事务与锁(上篇)
一 概述 在数据库方面,对于非DBA的程序员来说,事务与锁是一大难点,针对该难点,本篇文章视图采用图文的方式来与大家一起探讨. “浅谈SQL Server 事务与锁”这个专题共分两篇,上篇主讲事务及 ...
- 浅谈SQL Server事务与锁(上篇)
一 概述 在数据库方面,对于非DBA的程序员来说,事务与锁是一大难点,针对该难点,本篇文章试图采用图文的方式来与大家一起探讨. “浅谈SQL Server 事务与锁”这个专题共分两篇,上篇主讲事务及 ...
随机推荐
- memcache的最佳实践方案
1.memcached的基本设置 1)启动Memcache的服务器端 # /usr/local/bin/memcached -d -m 10 -u root -l 192.168.0.200 -p 1 ...
- Java多线程开发系列之二:如何创建多线程
前文已介绍过多线程的基本知识了,比如什么是多线程,什么又是进程,为什么要使用多线程等等. 在了解了软件开发中使用多线程的基本常识后,我们今天来聊聊如何简单的使用多线程. 在Java中创建多线程的方式有 ...
- MQ通道配置
转自:http://www.cnblogs.com/me115/p/3471788.html MQ通道配置 通道是用来连接两个队列管理器的: 在单个队列管理器内读写消息不需要建立通道:但在一个队列管理 ...
- ios webView 放大网页解决/input 获得焦点focus 网页放大 解决
新手遇到的问题: 终于找到原因,各种HTML viewport 都试过 setScalePageToFit 也试过,webViewDidFinishLoad加JS代码,动态算webView.scrol ...
- YbSoftwareFactory 代码生成插件【十六】:Web 下灵活、强大的审批流程实现(含流程控制组件、流程设计器和表单设计器)
程序=数据结构+算法,而企业级的软件=数据+流程,流程往往千差万别,客户自身有时都搞不清楚,随时变化的情况更是家常便饭,抛开功能等不谈,需求变化很大程度上就是流程的变化,流程的变化会给开发工作造成很大 ...
- html与Android——webView
1 <html> 2 <head> 3 <title>myHtml.html</title> 4 5 <meta http-equiv=" ...
- ARM——操作系统—最小操作系统-开发板测试
怀着激动的心情,打算弄到硬件上试试. 折腾了一整天.终于运行起来了. 需要设置IBRD和CR,以及寄存器. 希望大家也能顺利完成自己的开发板实验. 我畅想了一下,目前所有带串口的嵌入式ARM设备,都应 ...
- XML转换JSON的工具使用方法
1.xml的文件,文件的内容如下: <?xml version="1.0" encoding="UTF-8" standalone="yes&q ...
- Tween.js的使用示例
可参考:http://www.htmleaf.com/jQuery/Layout-Interface/201501271284.html 官方文档:https://github.com/tweenjs ...
- java 使用jar包
//主类 路径 /home/fly/flywww/c/java import mypackage.One; import mypackage.Two; public class Test { publ ...