Python爬虫抓取糗百的图片,并存储在本地文件夹
思路:
1.观察网页,找到img标签
2.通过requests和BS库来提取网页中的img标签
3.抓取img标签后,再把里面的src给提取出来,接下来就可以下载图片了
4.通过urllib的urllib.urlretrieve来下载图片并且放进文件夹里面(第一之前的准备工作就是获取当前路径然后新建一个文件夹)
5.如果有多张图片,不断的重复3-4
由于爬虫写得少,通过自己的调试,终于写了出来了
下面直接上代码:
#coding = 'utf-8'
import requests
from bs4 import BeautifulSoup
import urllib
import os
import sys
reload(sys)
sys.setdefaultencoding("utf-8") if __name__ == '__main__':
url = 'http://www.qiushibaike.com/'
res = requests.get(url)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'html.parser')
imgs = soup.find_all("img") _path = os.getcwd()
new_path = os.path.join(_path , 'pictures')
if not os.path.isdir(new_path):
os.mkdir(new_path)
new_path += '\ ' try:
x = 1
if imgs == []:
print "Done!"
for img in imgs:
link = img.get('src')
if 'http' in link:
print "It's downloading %s" %x + "th's piture"
urllib.urlretrieve(link, new_path + '%s.jpg' %x)
x += 1 except Exception, e:
print e
else:
pass
finally:
if x :
print "It's Done!!!"
接下来上结果:
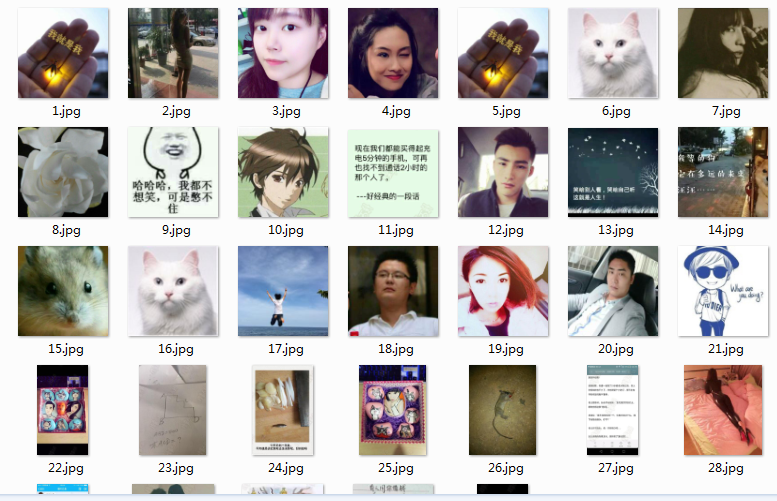
python3中的版本,略有有一点点不同,就是下载图片的方法需要加上request,然后才能使用urlretrieve方法进行下载
#!/usr/bin/python3
#coding = 'utf-8' import requests
from bs4 import BeautifulSoup
import urllib
import os
import sys
#reload(sys)
#sys.setdefaultencoding("utf_8") if __name__ == '__main__':
url = 'http://www.qiushibaike.com/'
res = requests.get(url)
res.encoding = 'utf-8'
print (res)
soup = BeautifulSoup(res.text,'html.parser')
#imgs = soup.find_all('img', attrs={'class': 'item_img'})
imgs = soup.find_all('img') _path = os.getcwd()
new_path = os.path.join(_path,'pictures\\')#需要添加斜杠,才能将图片放进单独的文件夹里面
print(new_path) if not os.path.isdir(new_path):
os.mkdir(new_path) #new_path = new_path + '\'
#print (str(new_path)) try:
x = 1
if imgs == []:
print ("Done!")
print (len(imgs))
for img in imgs:
link = img.get('src')
link = 'http:' + link
#print (link)
if True:
print ("It's downloading %s" %x + "th's piture")
#python3如下使用urlretrieve
#_new111 = new_path + '%s.jpg'%5
#print (_new111)
urllib.request.urlretrieve(link,new_path + '%s.jpg' %x)
x += 1 except Exception:
pass
# else:
# pass
finally:
if x:
print ("It's Done!")
结果都是一样,就不再另外贴结果截图了
总结:
虽然一开始思路不清晰,而且对怎样把图片保存下来,都不是很熟
但是经过自己的思考,只要思路清楚了,确定了方向就好办了,至于函数不会用的话,可以直接百度查,很方便的
总而言之,写程序之前一定要有思路,边写边想思路是不行的,那样容易返工
不过最后还是写出来了,哈哈
也请大家来共同学习和指正
----------------------
转载的话请大家注明出处哦,谢谢了
Python爬虫抓取糗百的图片,并存储在本地文件夹的更多相关文章
- Python爬虫——抓取糗百段子
在别人博客里学习的 抓取糗百段子,由于糗百不断的更新,代码需要改正. 抓取网页:http://www.qiushibaike.com/hot/page/1 修改后的代码如下: # -*- coding ...
- Python 爬虫: 抓取花瓣网图片
接触Python也好长时间了,一直没什么机会使用,没有机会那就自己创造机会!呐,就先从爬虫开始吧,抓点美女图片下来. 废话不多说了,讲讲我是怎么做的. 1. 分析网站 想要下载图片,只要知道图片的地址 ...
- python 爬虫抓取心得
quanwei9958 转自 python 爬虫抓取心得分享 urllib.quote('要编码的字符串') 如果你要在url请求里面放入中文,对相应的中文进行编码的话,可以用: urllib.quo ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- Python爬虫----抓取豆瓣电影Top250
有了上次利用python爬虫抓取糗事百科的经验,这次自己动手写了个爬虫抓取豆瓣电影Top250的简要信息. 1.观察url 首先观察一下网址的结构 http://movie.douban.com/to ...
- Python爬虫抓取东方财富网股票数据并实现MySQL数据库存储
Python爬虫可以说是好玩又好用了.现想利用Python爬取网页股票数据保存到本地csv数据文件中,同时想把股票数据保存到MySQL数据库中.需求有了,剩下的就是实现了. 在开始之前,保证已经安装好 ...
- python学习-抓取知乎图片
#!/bin/usr/env python3 __author__ = 'nxz' """ 抓取知乎图片webdriver Chromedriver驱动需要安装,并指定d ...
- python爬虫抓取哈尔滨天气信息(静态爬虫)
python 爬虫 爬取哈尔滨天气信息 - http://www.weather.com.cn/weather/101050101.shtml 环境: windows7 python3.4(pip i ...
- Python爬虫 —— 抓取美女图片
代码如下: #coding:utf-8 # import datetime import requests import os import sys from lxml import etree im ...
随机推荐
- webpack-vue搭建,部署到后端
1.安装npm(安装node自带npm),npm安装成功测试 2.安装cnpm,也可以装nvm-windows 步骤1,打开user/admin/.npmrc,输入,也可以用命令 步骤2,输入npm ...
- rails下react的demo
gemfile gem 'react-rails' gen一下 react:install 创建组件 react:component MyComponent name:string age:int v ...
- PHP 缩放图片
class CImage { /** * 生成保持原图纵横比的缩略图,支持.png .jpg .gif * 缩略图类型统一为.png格式 * $srcFile 原图像文件名称 * $toW 缩略图宽 ...
- log4net 配置
1.是直接在代码中通过调用XmlConfigurator.Configure()来解析配置文件,配置日志环境. log4net.Config.XmlConfigurator.Configure(); ...
- Bash Shell 获取进程 PID
转载地址:http://weyo.me/pages/techs/linux-get-pid/ 导读 Linux 的交互式 Shell 与 Shell 脚本存在一定的差异,主要是由于后者存在一个独立的运 ...
- Button--防止button多次点击
================================= //代码2 public abstract class NoDoubleClickListener implements OnCli ...
- email
#region 邮件帮助类 //+-------------------------------------------------------------------+ //+ FileName: ...
- Python 之 for循环中的lambda
第一种 f = [lambda x: x*i for i in range(4)] (如果将x换成i,调用时候就不用传参数,结果都为3) 对于上面的表达式,调用结果: >>> f ...
- [delphi]indy idhttp post方法
网易 博客 LOFTCam-用心创造滤镜 LOFTER-最美图片社交APP 送20张免费照片冲印 > 注册登录 加关注 techiepc的博客 万事如意 首页 日志 LOFTER 相册 音乐 ...
- VC++6.0 配置CppUTest测试环境
最近看<软件项目成功之道>,书中无数次提及到“单元测试”对于项目成败的重要性,看到同事将CppUTest用于Linux动态库测试,于是在VC++6.0环境下搭建一个基于CppUTest的单 ...