Floyd算法(二)之 C++详解
本章是弗洛伊德算法的C++实现。
目录
1. 弗洛伊德算法介绍
2. 弗洛伊德算法图解
3. 弗洛伊德算法的代码说明
4. 弗洛伊德算法的源码转载请注明出处:http://www.cnblogs.com/skywang12345/
更多内容:数据结构与算法系列 目录
弗洛伊德算法介绍
和Dijkstra算法一样,弗洛伊德(Floyd)算法也是一种用于寻找给定的加权图中顶点间最短路径的算法。该算法名称以创始人之一、1978年图灵奖获得者、斯坦福大学计算机科学系教授罗伯特·弗洛伊德命名。
基本思想
通过Floyd计算图G=(V,E)中各个顶点的最短路径时,需要引入一个矩阵S,矩阵S中的元素a[i][j]表示顶点i(第i个顶点)到顶点j(第j个顶点)的距离。
假设图G中顶点个数为N,则需要对矩阵S进行N次更新。初始时,矩阵S中顶点a[i][j]的距离为顶点i到顶点j的权值;如果i和j不相邻,则a[i][j]=∞。 接下来开始,对矩阵S进行N次更新。第1次更新时,如果"a[i][j]的距离" > "a[i][0]+a[0][j]"(a[i][0]+a[0][j]表示"i与j之间经过第1个顶点的距离"),则更新a[i][j]为"a[i][0]+a[0][j]"。 同理,第k次更新时,如果"a[i][j]的距离" > "a[i][k]+a[k][j]",则更新a[i][j]为"a[i][k]+a[k][j]"。更新N次之后,操作完成!
单纯的看上面的理论可能比较难以理解,下面通过实例来对该算法进行说明。
弗洛伊德算法图解
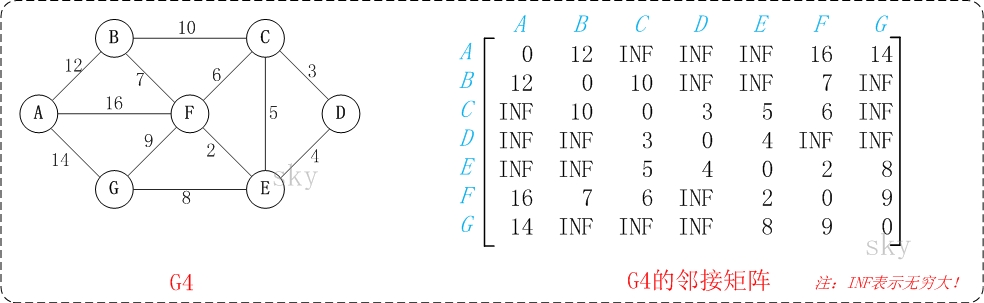
以上图G4为例,来对弗洛伊德进行算法演示。
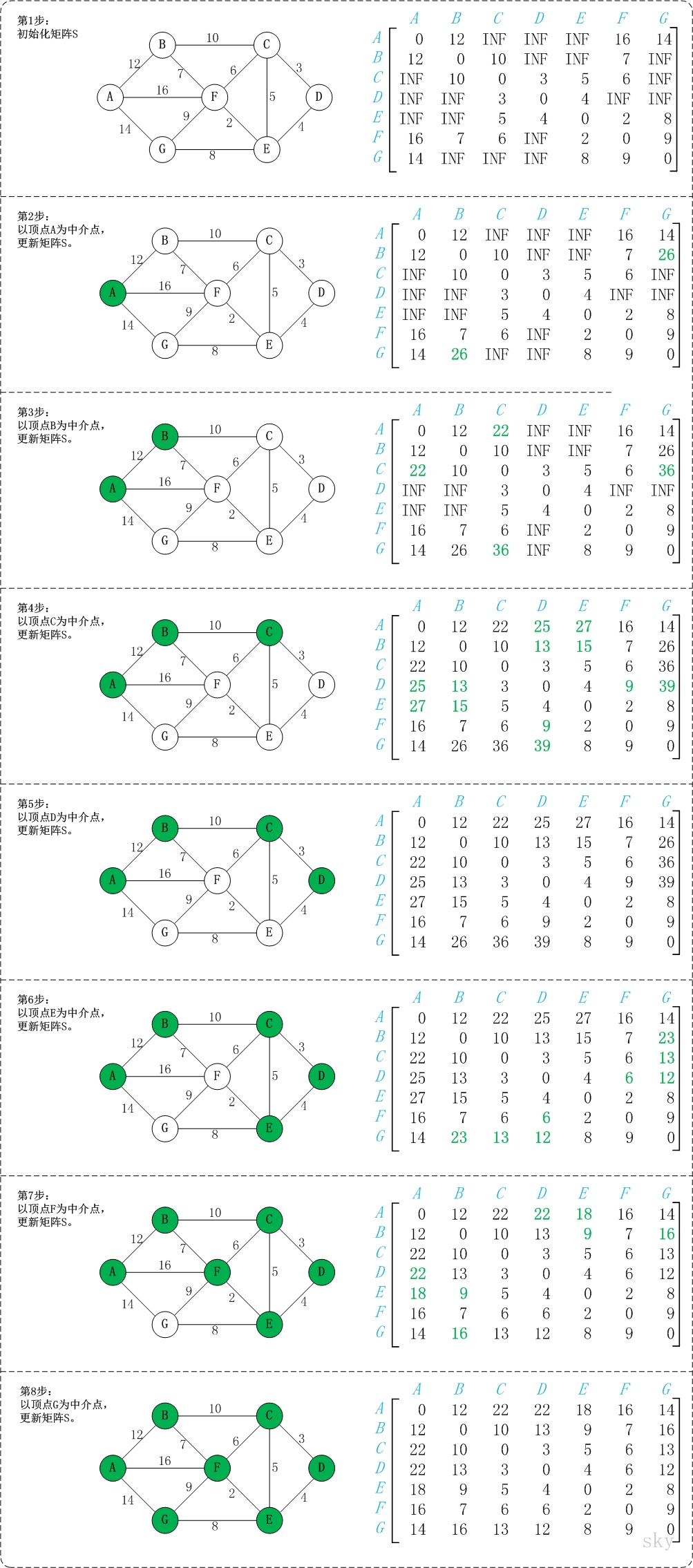
初始状态:S是记录各个顶点间最短路径的矩阵。
第1步:初始化S。
矩阵S中顶点a[i][j]的距离为顶点i到顶点j的权值;如果i和j不相邻,则a[i][j]=∞。实际上,就是将图的原始矩阵复制到S中。
注:a[i][j]表示矩阵S中顶点i(第i个顶点)到顶点j(第j个顶点)的距离。
第2步:以顶点A(第1个顶点)为中介点,若a[i][j] > a[i][0]+a[0][j],则设置a[i][j]=a[i][0]+a[0][j]。
以顶点a[1]6,上一步操作之后,a[1][6]=∞;而将A作为中介点时,(B,A)=12,(A,G)=14,因此B和G之间的距离可以更新为26。
同理,依次将顶点B,C,D,E,F,G作为中介点,并更新a[i][j]的大小。
弗洛伊德算法的代码说明
以"邻接矩阵"为例对弗洛伊德算法进行说明,对于"邻接表"实现的图在后面会给出相应的源码。
1. 基本定义
class MatrixUDG {
#define MAX 100
#define INF (~(0x1<<31)) // 无穷大(即0X7FFFFFFF)
private:
char mVexs[MAX]; // 顶点集合
int mVexNum; // 顶点数
int mEdgNum; // 边数
int mMatrix[MAX][MAX]; // 邻接矩阵
public:
// 创建图(自己输入数据)
MatrixUDG();
// 创建图(用已提供的矩阵)
//MatrixUDG(char vexs[], int vlen, char edges[][2], int elen);
MatrixUDG(char vexs[], int vlen, int matrix[][9]);
~MatrixUDG();
// 深度优先搜索遍历图
void DFS();
// 广度优先搜索(类似于树的层次遍历)
void BFS();
// prim最小生成树(从start开始生成最小生成树)
void prim(int start);
// 克鲁斯卡尔(Kruskal)最小生成树
void kruskal();
// Dijkstra最短路径
void dijkstra(int vs, int vexs[], int dist[]);
// Floyd最短路径
void floyd(int path[][MAX], int dist[][MAX]);
// 打印矩阵队列图
void print();
private:
// 读取一个输入字符
char readChar();
// 返回ch在mMatrix矩阵中的位置
int getPosition(char ch);
// 返回顶点v的第一个邻接顶点的索引,失败则返回-1
int firstVertex(int v);
// 返回顶点v相对于w的下一个邻接顶点的索引,失败则返回-1
int nextVertex(int v, int w);
// 深度优先搜索遍历图的递归实现
void DFS(int i, int *visited);
// 获取图中的边
EData* getEdges();
// 对边按照权值大小进行排序(由小到大)
void sortEdges(EData* edges, int elen);
// 获取i的终点
int getEnd(int vends[], int i);
};
Graph是邻接矩阵对应的结构体。
vexs用于保存顶点,vexnum是顶点数,edgnum是边数;matrix则是用于保存矩阵信息的二维数组。例如,matrix[i][j]=1,则表示"顶点i(即vexs[i])"和"顶点j(即vexs[j])"是邻接点;matrix[i][j]=0,则表示它们不是邻接点。
2. 弗洛伊德算法
/*
* floyd最短路径。
* 即,统计图中各个顶点间的最短路径。
*
* 参数说明:
* path -- 路径。path[i][j]=k表示,"顶点i"到"顶点j"的最短路径会经过顶点k。
* dist -- 长度数组。即,dist[i][j]=sum表示,"顶点i"到"顶点j"的最短路径的长度是sum。
*/
void MatrixUDG::floyd(int path[][MAX], int dist[][MAX])
{
int i,j,k;
int tmp;
// 初始化
for (i = 0; i < mVexNum; i++)
{
for (j = 0; j < mVexNum; j++)
{
dist[i][j] = mMatrix[i][j]; // "顶点i"到"顶点j"的路径长度为"i到j的权值"。
path[i][j] = j; // "顶点i"到"顶点j"的最短路径是经过顶点j。
}
}
// 计算最短路径
for (k = 0; k < mVexNum; k++)
{
for (i = 0; i < mVexNum; i++)
{
for (j = 0; j < mVexNum; j++)
{
// 如果经过下标为k顶点路径比原两点间路径更短,则更新dist[i][j]和path[i][j]
tmp = (dist[i][k]==INF || dist[k][j]==INF) ? INF : (dist[i][k] + dist[k][j]);
if (dist[i][j] > tmp)
{
// "i到j最短路径"对应的值设,为更小的一个(即经过k)
dist[i][j] = tmp;
// "i到j最短路径"对应的路径,经过k
path[i][j] = path[i][k];
}
}
}
}
// 打印floyd最短路径的结果
cout << "floyd: " << endl;
for (i = 0; i < mVexNum; i++)
{
for (j = 0; j < mVexNum; j++)
cout << setw(2) << dist[i][j] << " ";
cout << endl;
}
}
弗洛伊德算法的源码
这里分别给出"邻接矩阵图"和"邻接表图"的弗洛伊德算法源码。
Floyd算法(二)之 C++详解的更多相关文章
- Floyd算法(三)之 Java详解
前面分别通过C和C++实现了弗洛伊德算法,本文介绍弗洛伊德算法的Java实现. 目录 1. 弗洛伊德算法介绍 2. 弗洛伊德算法图解 3. 弗洛伊德算法的代码说明 4. 弗洛伊德算法的源码 转载请注明 ...
- Dijkstra算法(二)之 C++详解
本章是迪杰斯特拉算法的C++实现. 目录 1. 迪杰斯特拉算法介绍 2. 迪杰斯特拉算法图解 3. 迪杰斯特拉算法的代码说明 4. 迪杰斯特拉算法的源码 转载请注明出处:http://www.cnbl ...
- Prim算法(二)之 C++详解
本章是普里姆算法的C++实现. 目录 1. 普里姆算法介绍 2. 普里姆算法图解 3. 普里姆算法的代码说明 4. 普里姆算法的源码 转载请注明出处:http://www.cnblogs.com/sk ...
- Kruskal算法(二)之 C++详解
本章是克鲁斯卡尔算法的C++实现. 目录 1. 最小生成树 2. 克鲁斯卡尔算法介绍 3. 克鲁斯卡尔算法图解 4. 克鲁斯卡尔算法分析 5. 克鲁斯卡尔算法的代码说明 6. 克鲁斯卡尔算法的源码 转 ...
- 转:JAVAWEB开发之权限管理(二)——shiro入门详解以及使用方法、shiro认证与shiro授权
原文地址:JAVAWEB开发之权限管理(二)——shiro入门详解以及使用方法.shiro认证与shiro授权 以下是部分内容,具体见原文. shiro介绍 什么是shiro shiro是Apache ...
- 二叉搜索树详解(Java实现)
1.二叉搜索树定义 二叉搜索树,是指一棵空树或者具有下列性质的二叉树: 若任意节点的左子树不空,则左子树上所有节点的值均小于它的根节点的值: 若任意节点的右子树不空,则右子树上所有节点的值均大于它的根 ...
- 数据结构图文解析之:二叉堆详解及C++模板实现
0. 数据结构图文解析系列 数据结构系列文章 数据结构图文解析之:数组.单链表.双链表介绍及C++模板实现 数据结构图文解析之:栈的简介及C++模板实现 数据结构图文解析之:队列详解与C++模板实现 ...
- Java进阶(三十二) HttpClient使用详解
Java进阶(三十二) HttpClient使用详解 Http协议的重要性相信不用我多说了,HttpClient相比传统JDK自带的URLConnection,增加了易用性和灵活性(具体区别,日后我们 ...
- Spring Boot 启动(二) 配置详解
Spring Boot 启动(二) 配置详解 Spring 系列目录(https://www.cnblogs.com/binarylei/p/10198698.html) Spring Boot 配置 ...
随机推荐
- 项目修改有感_主要是以js、Gridview为主
1.弹出提示:confirm--弹出的窗口有确认.取消按钮 alert--弹出的窗口只有确认按钮 例:若需要在点击确认后执行其他操作(confirm) var toAlert = confirm(&q ...
- 美帝的emal to message gateway
Provider Email to SMS Address Format AllTel number@text.wireless.alltel.com AT&T number@txt.att. ...
- c#判断是否为合法的email地址
题目要求: class Program { static void Main(string[] args) { Console.WriteLine("请输入正确的邮箱地址,以 @sina.c ...
- angular2 递归导航菜单实现方式
看了网上很多源码,基本都是采用循环三级的方式.如果是无限级的菜单,就无法实现了. 菜单格式: [ { "title": "Item-1", "icon ...
- fatal error C1083: 无法打开预编译头文件:“Debug\a.pch”:No such file or directory
一.解决方法 右键点击你创建的项目,选择“属性标签”点击属性,弹出“项目属性页”,在左侧找到以下位置 配置属性 --> C/C++ --> 预编译头,并选择它:在右边的菜单中选择 “ ...
- ABP入门系列(3)——领域层创建实体
这一节我们主要和领域层打交道.首先我们要对ABP的体系结构以及从模板创建的解决方案进行一一对应.网上有代码生成器去简化我们这一步的任务,但是不建议初学者去使用. 一.首先来看看ABP体系结构 领域层就 ...
- 轻量级MVC框架:Nancy学习
一.认识Nancy 今天听讲关于Nancy框架的培训,被Nancy的易用性所吸引.故晚上回来梳理了一下知识. 什么是Nancy呢?如标题所述,Nancy是一个轻量级的独立的框架: Nancy 是一个轻 ...
- 【C语言学习】《C Primer Plus》第4章 字符串和格式化输入/输出
学习总结 1.String str=”hello world!”;(Java),char[20]=” hello world!”;(C).其实Java字符串的实现,也是字符数组. 2.字符串的尾部都会 ...
- Javascript aop(面向切面编程)之around(环绕)
Aop又叫面向切面编程,其中“通知”是切面的具体实现,分为before(前置通知).after(后置通知).around(环绕通知),用过spring的同学肯定对它非常熟悉,而在js中,AOP是一个被 ...
- 前端自动化测试工具doh学习总结(二)
一.robot简介 robot是dojo框架中用来进行前端自动化测试的工具,doh主要目的在于单元测试,而robot可以用来模仿用户操作来测试UI.总所周知,Selenium也是一款比较流行的前端自动 ...