KNN近邻算法
K近邻(KNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 kNN方法在类别决策时,只与极少量的相邻样本有关。由于kNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合。
-- 邻近算法 百度百科
KNN近邻算法思想
根据上文 K-means 算法分类,可以将一堆 毫无次序 的样本分成N个簇,如下:
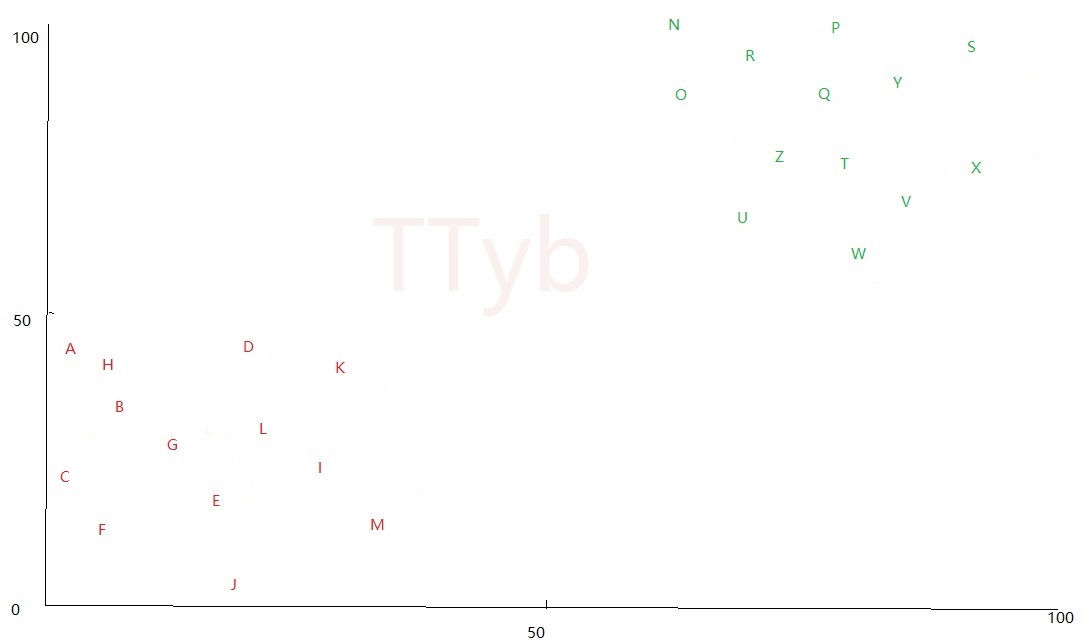
上图中红色代表一个分簇,绿色代表另一个分簇,这两个簇现在可以称呼为 训练样本 ,现在突然出现了一个 黄色的四边形 ,如下:
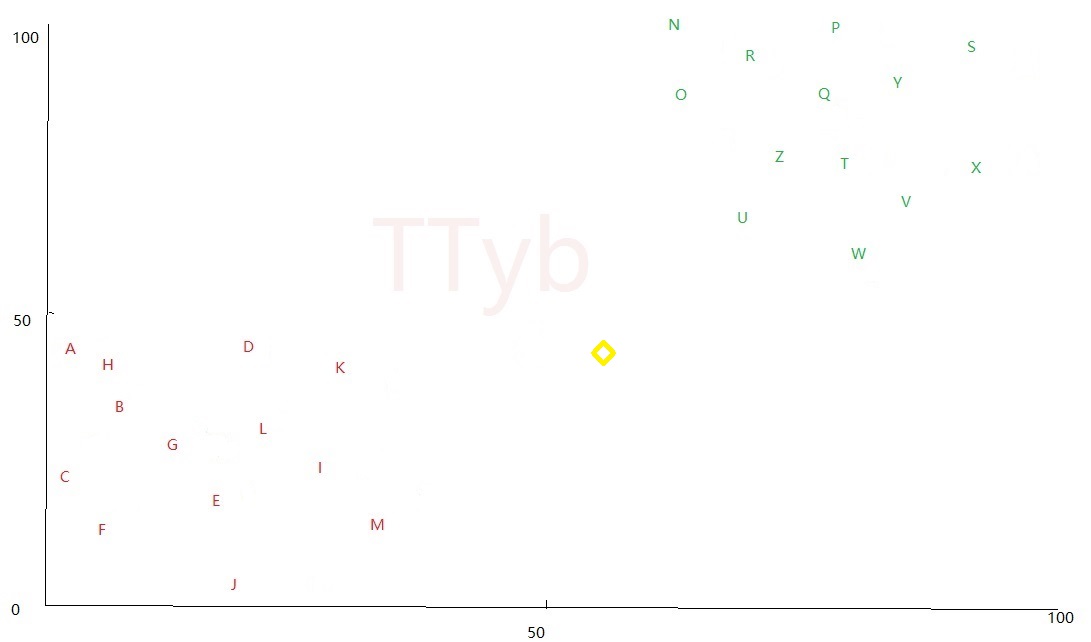
该 黄色的四边形 现在还不知道属于哪一个分簇。选取 黄色的四边形 周围的 K个点 (K一定要是奇数):
- 当K=3时,直观看出 黄色的四边形 周围的3个点为:K、M、U,就可以判断 黄色的四边形 属于红色簇
- 当K=4时,直观看出 黄色的四边形 周围的3个点为:K、M、U、W,无法判断 黄色的四边形 属于哪个簇,因此不能为偶数
- 当K=5时,直观看出 黄色的四边形 周围的3个点为:K、M、U、W、Z,就可以判断 黄色的四边形 属于绿色簇
KNN近邻算法就是以一定量的训练样本,来对其他未知样本进行分类,分类的标准和选取的K值有很大关系
KNN近邻算法实现
假设训练样本为:
clusters = {
'cluster2': {'H': {'y': 25, 'x': 27}, 'F': {'y': 30, 'x': 36}, 'G': {'y': 14, 'x': 31}, 'A': {'y': 34, 'x': 24},
'D': {'y': 33, 'x': 25}, 'I': {'y': 11, 'x': 28}, 'C': {'y': 23, 'x': 26}, 'E': {'y': 23, 'x': 38},
'B': {'y': 23, 'x': 6}, 'L': {'y': 15, 'x': 7}, 'K': {'y': 25, 'x': 17}, 'M': {'y': 39, 'x': 24},
'J': {'y': 26, 'x': 21}},
'cluster1': {'R': {'y': 97, 'x': 80}, 'N': {'y': 82, 'x': 99}, 'U': {'y': 81, 'x': 95}, 'V': {'y': 88, 'x': 79},
'O': {'y': 85, 'x': 73}, 'Y': {'y': 99, 'x': 87}, 'X': {'y': 72, 'x': 88},
'Q': {'y': 84, 'x': 100}, 'T': {'y': 70, 'x': 84}, 'W': {'y': 100, 'x': 89},
'S': {'y': 67, 'x': 86}, 'Z': {'y': 97, 'x': 66}, 'P': {'y': 88, 'x': 62}}}
随机生成一个point:
# 随机生成一个点
def buildpoint():
temp = {}
x = random.randint(0, 100)
y = random.randint(0, 100)
temp["x"] = x
temp["y"] = y
return temp
分别计算计算这个point与26个字母的 欧氏距离
# 取得point与K个值的距离
def classify(K, clusters, point):
dict = {}
distan = {}
for cluster in clusters:
for key in clusters[cluster].keys():
distan[key] = distance(clusters[cluster][key]["x"], point["x"], clusters[cluster][key]["y"], point["y"])
# reverse=False值按照从小到大排序
distan = sorted(distan.items(), key=lambda d: d[1], reverse=False)
for i in range(K):
key = distan[i][0]
value = distan[i][1]
dict[key] = value
return dict
返回的距离 distan 为:
# [('E', 21.02379604162864), ('F', 21.095023109728988), ('H', 30.805843601498726), ('G', 31.622776601683793), ('D', 32.01562118716424), ('C', 32.28002478313795), ('A', 33.06055050963308), ('M', 33.734255586866), ('I', 35.805027579936315), ('J', 36.49657518178932), ('K', 40.607881008493905), ('S', 45.45327270945405), ('T', 46.61544808322666), ('X', 50.60632371551998), ('B', 51.78802950489621), ('L', 52.81098370604357), ('O', 55.362442142665635), ('P', 56.22277118748239), ('V', 60.166435825965294), ('U', 62.00806399170998), ('N', 65.29931086925804), ('Z', 65.62011886609167), ('Q', 67.47592163134935), ('R', 68.9492567037528), ('Y', 73.40980860893181), ('W', 75.15317691222374)]
因为本文选取的 K=3 ,所以返回了距离point最近的3个点:
# {'U': 30.805843601498726, 'M': 21.02379604162864, 'K': 21.095023109728988}
最后判断这3个点属于哪个分簇即可:
def judgecluster(dict, clusters):
newdict = {}
for cluster in clusters:
for key in dict.keys():
if key in clusters[cluster]:
if cluster in newdict:
newdict[cluster] += 1
else:
newdict[cluster] = 1
newdict = sorted(newdict.items(), key=lambda d: d[1], reverse=True)
print("Point属于分簇" + str(newdict[0][0]))
print(newdict)
return newdict
返回的结果为:
# [('cluster2', 2), ('cluster1', 1)]
Point属于分簇cluster2
源码在我的博客上面:
KNN近邻算法的更多相关文章
- 机器学习之利用KNN近邻算法预测数据
前半部分是简介, 后半部分是案例 KNN近邻算法: 简单说就是采用测量不同特征值之间的距离方法进行分类(k-Nearest Neighbor,KNN) 优点: 精度高.对异常值不敏感.无数据输入假定 ...
- 机器学习入门KNN近邻算法(一)
1 机器学习处理流程: 2 机器学习分类: 有监督学习 主要用于决策支持,它利用有标识的历史数据进行训练,以实现对新数据的表示的预测 1 分类 分类计数预测的数据对象是离散的.如短信是否为垃圾短信,用 ...
- 机器学习实战笔记(Python实现)-01-K近邻算法(KNN)
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
- 基本分类方法——KNN(K近邻)算法
在这篇文章 http://www.cnblogs.com/charlesblc/p/6193867.html 讲SVM的过程中,提到了KNN算法.有点熟悉,上网一查,居然就是K近邻算法,机器学习的入门 ...
- 机器学习之K近邻算法(KNN)
机器学习之K近邻算法(KNN) 标签: python 算法 KNN 机械学习 苛求真理的欲望让我想要了解算法的本质,于是我开始了机械学习的算法之旅 from numpy import * import ...
- class-k近邻算法kNN
1 k近邻算法2 模型2.1 距离测量2.2 k值选择2.3 分类决策规则3 kNN的实现--kd树3.1 构造kd树3.2 kd树搜索 1 k近邻算法 k nearest neighbor,k-NN ...
- 机器学习——KNN算法(k近邻算法)
一 KNN算法 1. KNN算法简介 KNN(K-Nearest Neighbor)工作原理:存在一个样本数据集合,也称为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分 ...
- k近邻算法(KNN)
k近邻算法(KNN) 定义:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别. from sklearn.model_selection ...
- 1. K近邻算法(KNN)
1. K近邻算法(KNN) 2. KNN和KdTree算法实现 1. 前言 K近邻法(k-nearest neighbors,KNN)是一种很基本的机器学习方法了,在我们平常的生活中也会不自主的应用, ...
随机推荐
- taginput ,complete使用笔记
页面用到自动完成功能及需要taginput控件去展示,查资料的过程中发现 有两个类似的jQuery类库,到现在我也没搞明白它们两个有啥关联,jquery.tagsinput.js和bootstrap- ...
- PYTHON 链接 Oracle
一. cx_Oracle Python 连接Oracle 数据库,需要使用cx_Oracle 包. 该包的下载地址:http://cx-Oracle.sourceforge.net/ 下载的时候,注 ...
- Xcode 7.0升级后的bitcode
iOS 9.0中加入了一个新的功能,bitcode, 使用bitcode优化的app,体积可以变得更小. Apple可以在提交app后,向9.0及以上版本用户提供优化的小体积版本,向其他用户提供常规版 ...
- vue学习笔记
来公司以后就一直在用vue框架,不管是业务代码,还是做vue组件.关于vue有一些点是文档中没有提及的,记录一下以便以后查询- 一.Vue的特点 新一代 Vue.js 框架非常关注如何用极少的外部特性 ...
- dom2和dom3
第十二章 DOM2和DOM3 一.DOM变化 1.针对XML命名空间的变化 2.其他方面的变化 二.样式 1.访问元素的样式 .style 1)DOM样 ...
- C#常用操作类库一(验证类)
public class Validator { #region 验证输入字符串为数字 /// <summary> /// 验证输入字符串 ...
- 安装和使用Visual Studio 2013并进行简单的单元测试
现在我正在安装visual studio 2013,我听说好多同学都在安装visual studio 2015,但是他好像只支持Win10吧,我就退而求其次安装了visual studio 2013. ...
- Linux初学---->WinSCP+Putty
十二是个初学者,就觉得有意思.所以学下Linux.如果有啥不对的情路过大牛多多指点.心中也开始学着写博客,因为觉得博客对于学习技术不仅是个记录,还是对学的东西一个复习,一个反思,一个交流.另如果有好的 ...
- C#小小总结(面向对象)
前言 学c#也有一年的时间了 以前零零散散的记的一些笔记啊 随便之类的 没有写过比较整体一点的总结 所以现在写一个小小的总结 内容 一.面向对象 相信刚开始接触编程的童鞋都被这个概念弄糊涂过,对于刚刚 ...
- sql server 中xml 数据类型的insert、update、delete
近日对SQL操作XML作了如下整理: 1.插入 XML DECLARE @myDoc XMLSET @myDoc = '<Root> <ProductDescription Prod ...